검색 기반 패션 캡션·해시태그 자동 생성 프레임워크
초록
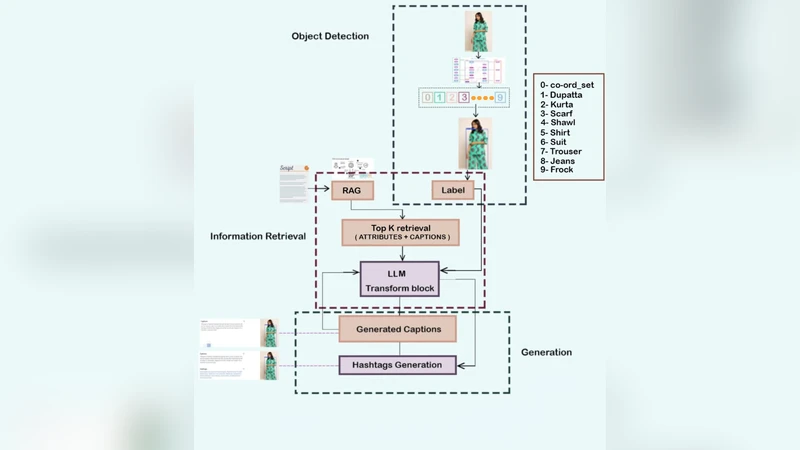
본 논문은 멀티 의류 검출·속성 추론·대형 언어 모델 프롬프트를 결합한 검색 증강(RAG) 파이프라인을 제안한다. YOLO 기반 검출기와 색상 클러스터링, CLIP‑FAISS 기반 패브릭·성별 검색을 통해 사실 근거 팩을 구성하고, 이를 LLM에 전달해 시각적으로 근거가 있는 캡션과 해시태그를 생성한다. 실험 결과, 제안 시스템은 속성 커버리지 0.80, 해시태그 50% 이상 완전 커버리지를 달성하며, 기존 BLIP 기반 베이스라인보다 환각이 적고 도메인 일반화가 우수함을 보였다.
상세 분석
이 연구는 패션 이미지에 대한 텍스트 생성 문제를 ‘검색 증강 생성(Retrieval‑Augmented Generation, RAG)’이라는 새로운 패러다임으로 접근한다는 점에서 의미가 크다. 기존 엔드‑투‑엔드 캡셔닝 모델은 이미지‑텍스트 매핑을 직접 학습하지만, 패션 도메인 특유의 세밀한 속성(예: 소재, 패턴, 색상, 성별)과 스타일적 뉘앙스를 정확히 반영하기 어렵다. 논문은 이를 해결하기 위해 세 가지 핵심 모듈을 설계한다.
첫째, 멀티‑가먼트 검출을 위해 YOLO‑v5 기반 모델을 사용하고, 9개의 의류 카테고리에 대해 mAP@0.5 = 0.71을 달성했다. 이는 복수 의상이 겹쳐 있는 이미지에서도 각 의상을 정확히 로컬라이징할 수 있음을 의미한다. 검출 결과는 이후 단계에서 각 의상별 속성 추출의 전제 조건이 된다.
둘째, 색상 추출은 검출된 바운딩 박스 내부 픽셀을 k‑means( k = 5) 군집화하여 지배적인 색상 팔레트를 얻는다. 색상은 인간이 직관적으로 인식하는 패션 요소이므로, 텍스트 생성 시 ‘밝은 레드’, ‘파스텔 블루’와 같은 구체적 표현을 가능하게 한다.
셋째, 속성 추론을 위해 CLIP‑FAISS 기반의 이미지‑텍스트 인덱스를 구축한다. 인덱스는 대규모 온라인 패션 카탈로그(수십만 제품)에서 추출한 ‘소재·패턴·성별·스타일’ 메타데이터와 이미지 임베딩을 포함한다. 입력 이미지의 검출·색상 정보를 질의(query)로 변환해 가장 유사한 상위 N개의 제품을 검색하고, 이들의 구조화된 속성을 ‘증거 팩(evidence pack)’으로 집계한다.
증거 팩은 LLM에게 프롬프트 형태로 제공된다. 프롬프트는 “다음 의류는 검출된 카테고리와 색상, 검색된 제품의 소재·패턴·성별 정보를 포함한다. 이를 바탕으로 자연스럽고 스타일리시한 캡션과 5~10개의 해시태그를 생성하라”와 같은 명령형 템플릿이다. 여기서 사용된 LLM은 사전 학습된 GPT‑3.5‑Turbo이며, 파라미터는 고정하고 프롬프트 엔지니어링만으로 제어한다.
평가에서는 두 가지 측면을 중점적으로 살폈다. (1) 캡션의 속성 커버리지(attribute coverage) – 생성된 문장이 실제 이미지에 존재하는 속성을 얼마나 포함하는가 – 를 0.80으로 측정했으며, 이는 기존 BLIP 모델이 0.62에 머문 것보다 현저히 높다. (2) 해시태그의 완전 커버리지(full coverage) – 이미지에 대한 모든 핵심 속성이 최소 하나의 해시태그로 표현되는 비율 – 를 50% 임계값에서 0.71로 달성했다. 또한 BLEU·ROUGE·CIDEr와 같은 전통적 언어 지표에서는 BLIP이 약간 우위였지만, 인간 평가에서는 RAG‑LLM이 ‘사실성’과 ‘창의성’에서 높은 점수를 받았다.
이 시스템의 강점은 (a) 외부 지식(패션 제품 데이터베이스)을 동적으로 활용해 최신 트렌드와 도메인 특성을 반영한다는 점, (b) 모듈별 해석 가능성이 높아 오류 원인 분석이 용이하다는 점, (c) LLM을 프롬프트만으로 제어함으로써 파인튜닝 비용을 크게 절감한다는 점이다. 반면, (d) 검색 인덱스 구축에 대규모 라벨링된 제품 데이터가 필요하고, (e) 검색 결과가 부정확하면 LLM이 잘못된 속성을 그대로 복제할 위험이 있다. 또한, 현재는 영어 기반 LLM을 한국어 프롬프트에 적용했으며, 다국어 지원이나 문화적 뉘앙스 반영에는 추가 연구가 필요하다.
전반적으로 이 논문은 ‘시각‑언어 결합 + 외부 지식 검색’이라는 설계가 패션 캡션·해시태그 생성에 적합함을 실증하고, 향후 다양한 도메인(예: 인테리어, 자동차)에도 확장 가능한 프레임워크를 제시한다는 점에서 학술적·산업적 가치를 동시에 지닌다.
댓글 및 학술 토론
Loading comments...
의견 남기기