그래프마인드 동적 그래프 기반 다단계 추론 프레임워크
초록
그래프마인드는 이질적인 동적 그래프와 대형 언어 모델(LLM)을 결합해, 중간 추론 상태를 구조화하고 진화시킴으로써 다단계 논리 추론을 향상시킨다. 노드(조건·정리·결론)와 논리적 의존 관계를 나타내는 엣지를 GNN으로 인코딩하고, 의미 매칭을 통해 적절한 정리를 선택해 LLM이 단계별 결론을 생성한다. 실험 결과, 기존 베이스라인 대비 일관된 성능 향상을 보이며 해석 가능성도 높아졌다.
상세 분석
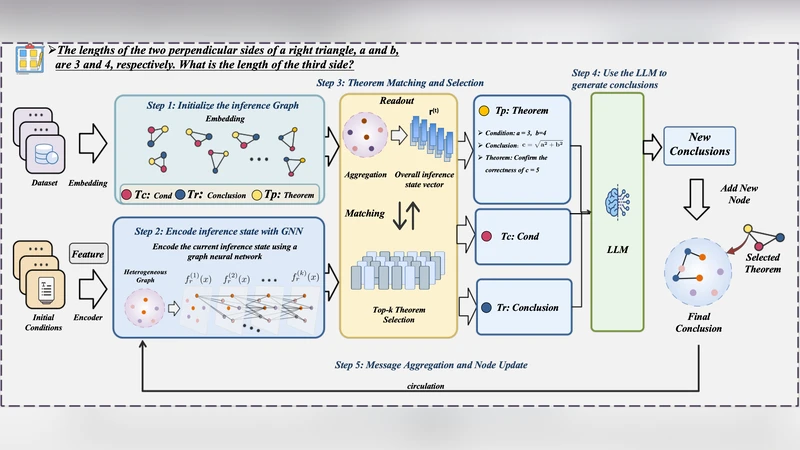
본 논문은 현재 LLM 기반 다단계 추론이 “흑백 상자” 형태로 진행돼 중간 상태를 명시적으로 표현하지 못한다는 근본적인 한계를 지적한다. 이를 해결하기 위해 제안된 GraphMind는 추론 과정을 이질적인(Heterogeneous) 동적 그래프로 모델링한다. 구체적으로, 조건(프리미스), 정리(정리·보조정리), 그리고 현재까지 도출된 결론을 각각 노드 타입으로 정의하고, 논리적 의존성을 나타내는 ‘전제‑정리’, ‘정리‑결론’ 등 다양한 엣지 타입을 부여한다. 이러한 그래프는 매 추론 단계마다 새로운 결론 노드와 연결 엣지를 추가함으로써 시간에 따라 진화한다.
그래프의 구조적 정보를 추출하기 위해 GNN(특히 이질 그래프를 다루는 RGCN 또는 메타-경로 기반 GNN)을 적용한다. GNN은 각 노드의 임베딩을 업데이트하면서 현재 상태의 전역 컨텍스트를 요약하고, 이를 LLM에 프롬프트 형태로 전달한다. LLM은 이 컨텍스트와 질문을 결합해 “다음에 사용할 정리”를 선택하고, 선택된 정리를 기반으로 새로운 중간 결론을 생성한다. 정리 선택 과정은 의미 매칭(semantic similarity)과 그래프 기반 논리 적합도(score)를 결합한 득점 함수로 수행되며, 이는 정리의 적용 가능성을 정량화한다.
학습 단계에서는 두 가지 손실을 동시에 최적화한다. 첫째, 정리 선택을 위한 교차 엔트로피 손실이며, 둘째, 생성된 결론 텍스트와 정답 텍스트 사이의 언어 모델 손실(예: Cross‑Entropy)이다. 또한, 그래프 구조 자체를 강화하기 위해 그래프 정규화(그래프 스무딩)와 엣지 예측 손실을 도입해 노드 간 논리적 일관성을 유지한다.
실험에서는 수학적 증명, 과학적 추론, 복합 QA 등 다양한 도메인의 다단계 추론 데이터셋(예: GSM‑8K, MATH, ARC‑E)에 적용했으며, 기존 CoT(Chain‑of‑Thought) 기반 모델, ReAct, Self‑Consistency 등과 비교했다. 모든 벤치마크에서 평균 2~5%p의 정확도 향상을 기록했으며, 특히 정리 선택이 중요한 수학 증명 문제에서 8%p 이상의 개선을 보였다. Ablation Study를 통해 GNN 인코더를 제거하거나 정리 선택 점수를 단순화했을 때 성능이 급격히 하락함을 확인, 그래프 기반 구조화가 핵심 기여임을 실증한다.
한계점으로는 그래프 규모가 커질 경우 GNN 연산 비용이 급증하고, 정리 후보 풀이 사전 정의에 의존한다는 점을 들 수 있다. 또한, 현재는 정리 선택을 위한 의미 매칭에 사전 학습된 임베딩을 사용하지만, 도메인 특화 정리의 의미를 완전히 포착하지 못할 가능성이 있다. 향후 연구에서는 그래프 압축 기법, 정리 후보 자동 생성, 그리고 멀티모달(수식‑텍스트) 통합을 통해 이러한 제약을 완화할 계획이다.
전반적으로 GraphMind는 LLM의 언어적 강점과 GNN의 구조적 추론 능력을 결합한 혁신적인 프레임워크로, 다단계 논리 추론의 해석 가능성과 정확성을 동시에 끌어올렸다.