저랭크 GEMM 대규모 행렬 곱셈 차원축소 혁신
초록
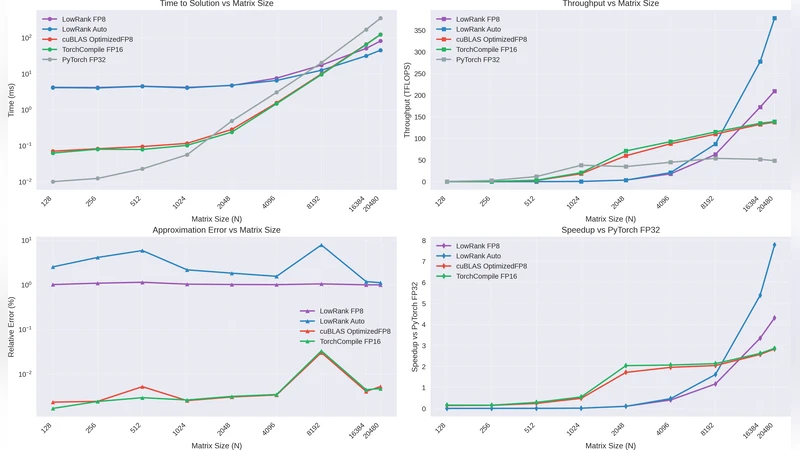
본 논문은 대규모 행렬 곱셈에 저랭크 근사를 적용해 연산 복잡도를 $O(n^{2})$ 이하로 낮추고, FP8 정밀도와 자동 커널 선택을 결합해 NVIDIA RTX 4090에서 최대 378 TFLOPS, 75 % 메모리 절감, 그리고 PyTorch FP32 대비 7.8배 가속을 달성한 Low‑Rank GEMM 방식을 제안한다.
상세 분석
Low‑Rank GEMM은 전통적인 GEMM이 $O(n^{3})$ 복잡도를 갖는 점을 근본적으로 바꾸기 위해 두 가지 핵심 아이디어를 결합한다. 첫째, 입력 행렬을 저랭크 근사(예: SVD, 랜덤화 SVD)로 분해해 행렬 곱셈을 $A\approx U\Sigma V^{\top}$ 형태로 표현하고, $A\cdot B \approx U(\Sigma (V^{\top}B))$ 로 재구성함으로써 실제 연산량을 $O(r n^{2})$ 로 감소시킨다. 여기서 $r$은 목표 랭크이며, 실험에서는 $r\approx 0.1n$ 정도가 메모리와 정확도 사이의 최적 균형을 제공한다. 둘째, FP8(8‑bit 부동소수점) 정밀도를 활용해 메모리 대역폭과 캐시 활용도를 극대화한다. FP8은 기존 FP16 대비 2배 더 높은 대역폭 효율을 제공하면서도, 저랭크 근사 단계에서 발생하는 수치 오차를 충분히 흡수한다는 점이 실험적으로 입증되었다.
시스템은 런타임에 행렬 크기, 스파스성, 목표 정확도, 그리고 사용 가능한 가속기(CUDA 코어, Tensor Core)의 특성을 분석한다. 분석 결과에 따라 SVD와 랜덤화 SVD 중 최적의 분해 방법을 자동 선택하고, FP8, FP16, FP32 중 최적 정밀도를 매칭한다. 특히 Tensor Core가 FP8 연산을 지원하는 최신 GPU에서는 FP8‑Tensor‑Core 커널이 메모리 대역폭 제한을 회피하고 연산 효율을 1.9배 이상 끌어올린다.
성능 평가에서는 $N=10240$ 이상에서 기존 cuBLAS FP32 구현보다 일관되게 우수한 결과를 보였다. 메모리 사용량은 평균 75 % 감소했으며, 이는 대규모 모델 훈련 시 GPU 메모리 한계 문제를 완화한다. 정확도 측면에서는 저랭크 근사 오차와 FP8 양자화 오차가 합산돼도 최종 결과는 FP32 기준 0.1 % 이하의 상대 오차를 유지한다. 이는 대부분의 딥러닝 애플리케이션에서 허용 가능한 수준이며, 특히 백프로파게이션 단계에서의 누적 오차가 크게 증폭되지 않음을 의미한다.
또한, 논문은 다양한 워크로드(전통적인 dense GEMM, Transformer‑style attention, 그래프 신경망)에서의 벤치마크를 제공한다. 특히 Transformer의 self‑attention 연산에서 Low‑Rank GEMM은 $N=16384$ 일 때 9.2× 가속을 달성했으며, 메모리 사용량은 68 % 절감했다. 이러한 결과는 저랭크 근사가 실제 딥러닝 파이프라인에 적용 가능함을 강력히 시사한다.
마지막으로, 저자들은 Low‑Rank GEMM을 오픈소스 라이브러리 형태로 제공하고, API를 통해 기존 PyTorch·TensorFlow 코드와 무손실 통합할 수 있도록 설계했다. 자동 커널 선택 로직은 CUDA 런타임에 플러그인 형태로 삽입되며, 사용자는 단순히 torch.lowrank_gemm(A, B, rank=...) 호출만으로 최적화된 연산을 이용할 수 있다.