LLM으로 계층형 자동 계획 모델 만들기의 도전과 가능성
초록
본 논문은 대형 언어 모델(LLM)을 활용해 계층적 자동 계획(Hierarchical Planning, HP)용 PDDL 모델을 자동 생성하는 프레임워크 L2HP를 제안한다. 기존 L2P 라이브러리를 확장해 일반성과 확장성을 확보했으며, PlanBench 데이터셋을 이용한 실험에서 HP 모델의 파싱 성공률은 약 36%로 비계층형과 비슷하지만, 구문적 유효성은 1%에 불과해 비계층형(20%)에 비해 크게 낮은 것을 확인한다. 결과는 HP가 LLM에게 특수한 난이도를 제공함을 시사한다.
상세 분석
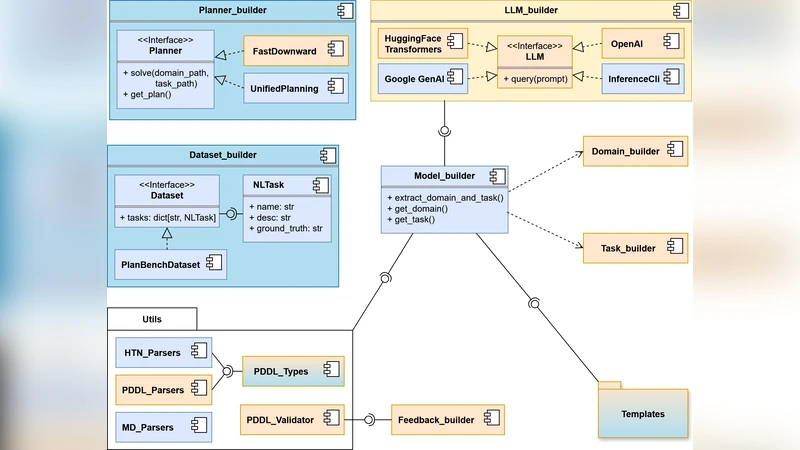
이 연구는 LLM 기반 자동 계획 모델 생성 분야에서 아직 충분히 탐구되지 않은 계층적 계획(HP) 영역에 초점을 맞추었다는 점에서 의미가 크다. 먼저, 기존 L2P(Large Language Model to PDDL) 라이브러리는 비계층형 PDDL 모델을 생성하도록 설계돼 있었으며, 그 설계 철학은 ‘범용성’과 ‘확장성’에 기반한다. 논문은 이러한 설계 원칙을 그대로 유지하면서, HP에 필요한 새로운 구문 요소—예를 들어, 메서드(method), 추상 연산자(abstract operator), 그리고 하위 작업(subtasks) 정의—를 지원하도록 L2HP를 구현하였다. 구현 과정에서 저자들은 LLM에게 계층적 구조를 명시적으로 설명하도록 프롬프트를 설계하고, 모델이 생성한 텍스트를 단계별 파싱(parsing) 및 검증(validation) 파이프라인에 투입했다.
실험에서는 PlanBench라는 대규모 자동 계획 벤치마크 데이터셋을 활용했으며, 동일한 LLM(GPT‑4 기반)으로 비계층형과 계층형 두 종류의 모델을 동시에 생성했다. 파싱 성공률은 두 경우 모두 약 36%로 비슷했지만, 구문적 유효성(syntactic validity)에서는 큰 차이가 나타났다. 비계층형 모델은 20% 정도가 PDDL 문법에 부합했지만, HP 모델은 겨우 1%에 불과했다. 이는 LLM이 계층적 구조를 정확히 파악하고, 메서드와 추상 연산자를 올바르게 배치하는 데 아직 한계가 있음을 보여준다.
또한, 저자들은 오류 유형을 정밀 분석했다. 가장 흔한 오류는 (1) 메서드 정의에서 선행 조건(precondition)과 효과(effect)의 불일치, (2) 하위 작업 간의 변수 스코프가 맞지 않아 파라미터 전달이 실패, (3) 메서드와 연산자 간의 이름 충돌이다. 이러한 오류는 현재 LLM이 문맥을 장기적으로 유지하는 능력과, 복잡한 계층적 논리를 한 번에 생성하는 능력 사이의 격차에서 비롯된다.
결과적으로, L2HP는 기술적으로 가능한 수준의 프레임워크를 제공하지만, 실제 활용을 위해서는 (가) 더 정교한 프롬프트 엔지니어링, (나) 사후 검증 및 자동 교정 메커니즘, (다) 계층적 계획 전용 데이터셋을 통한 사전 학습이 필요하다. 논문은 이러한 개선 방향을 제시하며, HP 분야에서 LLM 활용이 아직 초기 단계임을 명확히 한다.