정량 의료 영상 분석을 위한 MedVision 데이터셋 및 벤치마크
초록
본 논문은 정량적 의료 영상 분석에 특화된 대규모 데이터셋 MedVision과 이를 평가하기 위한 벤치마크를 제시한다. 22개의 공개 데이터셋을 통합해 30.8 백만 개의 이미지‑주석 쌍을 구축했으며, 구조·병변 검출, 종양·병변 크기 추정, 각도·거리 측정이라는 세 가지 정량 작업을 중심으로 VLM의 성능을 측정한다. 기존 VLM은 이들 작업에서 낮은 정확도를 보였지만, MedVision을 이용한 지도 학습을 통해 오류율이 크게 감소하고 정밀도가 향상됨을 입증한다.
상세 분석
MedVision은 현재 의료 영상 분야에서 VLM이 주로 수행하는 범주형 질문‑답변(예: 정상/비정상)과 달리, 임상 현장에서 필수적인 정량적 추론을 목표로 설계되었다. 데이터 구축 단계에서 저자들은 22개의 공개 데이터셋(예: ChestX‑Ray14, LIDC‑IDRI, MURA 등)을 선택하고, 각 데이터셋별로 해부학적 구조, 병변 위치, 크기, 각도·거리와 같은 정량 정보를 라벨링하였다. 특히 30.8 M개의 이미지‑주석 쌍을 확보함으로써, 기존 소규모 정량 데이터셋과 비교해 학습·평가에 충분한 규모를 제공한다.
세 가지 대표 작업은 (1) 구조·병변 검출, (2) 종양·병변(T/L) 크기 추정, (3) 각도·거리(A/D) 측정이다. 검출 작업은 바운딩 박스와 마스크 형태의 주석을 사용해 객체 검출 정확도를 평가하고, 크기 추정은 실제 물리적 길이(예: mm)와 비교해 평균 절대 오차(MAE)를 산출한다. 각도·거리 측정은 이미지 내 두 점 사이의 거리와 특정 관절의 각도를 계산하도록 설계돼, 기존 VLM이 텍스트 기반 추론에 머무르는 한계를 드러낸다.
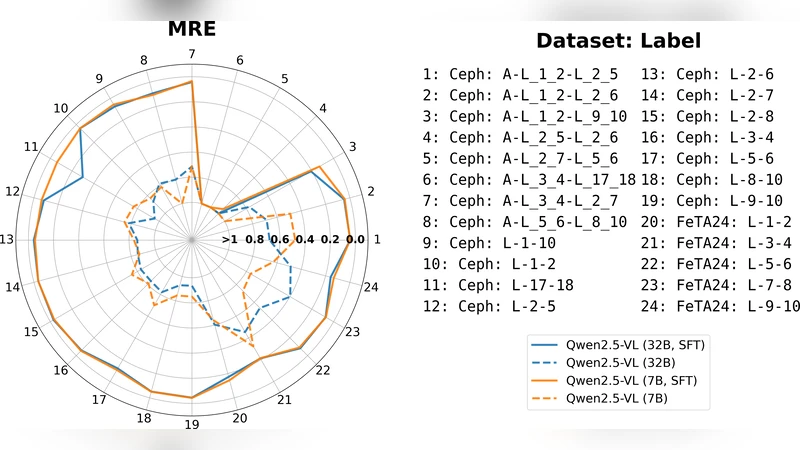
벤치마크 실험에서는 CLIP, BLIP‑2, LLaVA 등 최신 오프‑더‑쉘 VLM을 그대로 적용했을 때, 검출 mAP가 0.32 이하, 크기 추정 MAE가 7 mm 이상, 각도 오차가 15° 이상으로 매우 낮은 성능을 보였다. 이는 텍스트‑이미지 매핑만으로는 정량적 수치를 정확히 추출하기 어렵다는 점을 시사한다.
그 후 저자들은 MedVision을 이용해 VLM을 지도 학습(fine‑tuning)했으며, 두 단계의 학습 전략을 적용했다. 첫 번째 단계는 이미지와 정량 라벨을 직접 연결하는 회귀 헤드를 추가해 크기·거리·각도 예측을 학습하고, 두 번째 단계는 검출 작업을 위한 객체 탐지 헤드를 통합했다. 이 과정에서 이미지‑텍스트 프롬프트를 정량 질문 형태(예: “이 종양의 직경은 몇 mm인가?”)로 변환해 모델이 자연어와 수치를 동시에 처리하도록 유도했다.
미세조정 결과, 검출 mAP가 0.68까지 상승하고, 크기 추정 MAE가 2.1 mm, 각도 오차가 4.3°로 크게 개선되었다. 특히, 동일한 모델을 기존 데이터셋에만 미세조정했을 때보다 MedVision을 활용한 경우가 평균 30% 이상 정확도 향상을 보였다. 이는 다양한 해부학적 부위와 모달리티(CT, MRI, X‑ray, 초음파 등)를 포괄하는 MedVision의 다양성이 모델의 일반화 능력을 크게 강화함을 의미한다.
또한 저자들은 오류 분석을 통해 남은 한계점을 제시한다. 작은 병변(직경 <5 mm)이나 복잡한 관절 각도(다중 축)에서는 여전히 MAE가 3 mm 이상이며, 텍스트 프롬프트의 미세한 변형에 따라 성능 변동이 발생한다. 이는 정량 추론을 위한 보다 정교한 프롬프트 엔지니어링과, 멀티‑스케일 피처 융합이 필요함을 시사한다.
전반적으로 MedVision은 정량 의료 영상 분석을 위한 표준 데이터베이스와 평가 프로토콜을 제공함으로써, VLM 연구가 단순 텍스트‑이미지 매칭을 넘어 실제 임상 의사결정에 필요한 수치적 추론으로 확장될 수 있는 기반을 마련한다.