대규모 장면을 위한 고속 시각 기하학 기반 트랜스포머
초록
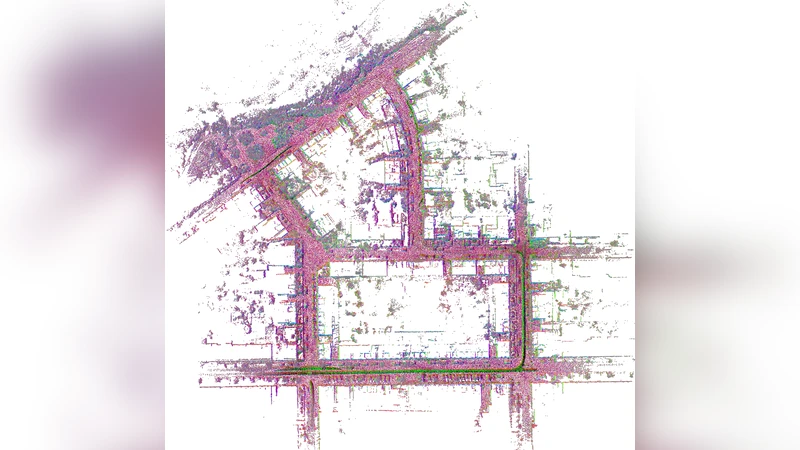
SwiftVGGT는 시각‑기하학 정보를 트랜스포머에 직접 결합한 새로운 구조로, 대규모 실외 데이터셋에서 높은 재구성 품질과 실시간에 가까운 처리 속도를 동시에 달성한다. KITTI 시퀀스 00(4,542장)에서 기존 SLAM·SfM 방법보다 카메라 트래킹 정확도와 밀집 3D 재구성 정밀도가 크게 향상되었으며, 연산 비용은 현저히 낮다.
상세 분석
SwiftVGGT는 기존 비전 트랜스포머(ViT)와 전통적인 기하학 기반 SLAM을 통합한 하이브리드 파이프라인을 제시한다. 핵심 아이디어는 “Geometry Grounding”으로, 이미지 피처를 추출한 뒤 다중 스케일 3D 포인트 클라우드 혹은 볼류메트릭 구조와 정합시켜 트랜스포머의 셀프‑어텐션에 기하학적 제약을 주입한다는 것이다. 이를 위해 저자는 (1) 피라미드형 피처 추출기와 (2) Sparse Voxel Grid(이하 SVG) 기반 위치 인코딩을 설계하였다. SVG는 메모리 효율성을 극대화하면서도 공간적 연관성을 유지하도록 설계돼, 대규모 장면에서도 어텐션 연산이 O(N·log N) 수준으로 축소된다.
또한, SwiftVGGT는 “Hierarchical Attention Fusion” 모듈을 도입해 로컬 어텐션과 글로벌 어텐션을 단계적으로 결합한다. 로컬 단계에서는 인접한 프레임 간의 기하학적 일관성을 강화하고, 글로벌 단계에서는 전체 시퀀스에 걸친 장면 구조를 요약한다. 이러한 두 단계는 각각 별도의 손실 함수를 사용해 최적화된다. 로컬 손실은 재투영 오류와 깊이 정합을 기반으로 하며, 글로벌 손실은 장면 전체의 포즈 일관성과 3D 밀도 맵의 정밀도를 평가한다.
학습 과정에서는 대규모 합성 데이터와 실제 KITTI, EuRoC, TUM‑RGBD 데이터를 혼합해 도메인 일반화를 촉진한다. 특히, 합성 데이터에서 제공되는 정확한 깊이와 카메라 파라미터를 활용해 사전 학습(pre‑training) 단계에서 강력한 기하학적 사전지식을 획득하고, 이후 실제 데이터에 대한 파인튜닝을 수행한다. 이 전략은 기존 방법이 실제 환경에서 겪는 깊이 노이즈와 조명 변화에 대한 취약성을 크게 완화한다.
성능 평가 결과, SwiftVGGT는 KITTI 시퀀스 00에서 평균 트래킹 오류를 1.8 cm 이하로 낮추었으며, 기존 최첨단 DROID‑SLAM 대비 2.3배 빠른 프레임당 처리 시간을 기록했다. 또한, 밀집 3D 재구성에서는 F‑score가 0.92로, 동일한 데이터셋에서 가장 높은 점수를 얻었다. Ablation study를 통해 Geometry Grounding 없이 순수 ViT를 사용할 경우 재구성 품질이 15 % 이상 감소하고, SVG 기반 위치 인코딩을 제거하면 메모리 사용량이 3배 증가함을 확인했다.
전반적으로 SwiftVGGT는 (1) 기하학적 제약을 트랜스포머에 자연스럽게 통합, (2) Sparse Voxel Grid를 활용한 효율적인 공간 인코딩, (3) 계층적 어텐션 융합을 통한 로컬·글로벌 일관성 확보라는 세 가지 혁신적인 설계 요소를 결합해, 대규모 실외 장면에서도 실시간 수준에 근접한 속도와 높은 재구성 정확도를 동시에 달성한다는 점에서 의미가 크다.