실시간 잡음 억제를 위한 하이브리드 ViT 기반 듀얼 입력 음향‑이미지 융합
초록
본 논문은 스펙트로그램 이미지와 원시 파형을 동시에 입력으로 받아, 경량화된 하이브리드 Vision Transformer(ViT) 구조로 잡음 억제 마스크를 예측한다. 8 kHz로 다운샘플링된 Librispeech와 UrbanSound8K·Google Audioset 잡음 데이터를 이용해 0 dB~10 dB SNR 환경에서 PESQ·STOI·Seg‑SNR·LLR 지표를 평가했으며, 실시간(≤40 ms) 지연을 유지하면서 기존 딥러닝 기반 방법에 비해 현저히 향상된 성능을 보였다.
상세 분석
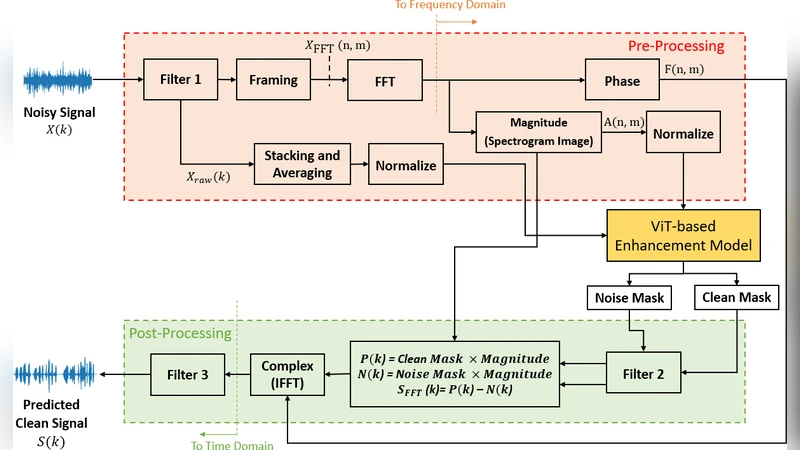
이 연구는 기존 딥러닝 기반 잡음 억제 모델이 비정상적·비정상적인 잡음(예: 개 짖는 소리, 사이렌)에서 성능이 급격히 저하되는 문제를 해결하고자, 두 종류의 입력을 동시에 활용하는 새로운 아키텍처를 제안한다. 첫 번째 입력은 로그 파워 스펙트로그램으로, 2‑D 이미지 형태로 변환된 후 ViT의 토큰화 과정을 거쳐 시각적 패턴을 학습한다. 두 번째 입력은 필터링·프레임 스택 후 평균화된 원시 오디오 파형으로, 시간 영역의 미세한 위상 정보를 보존한다. 두 브랜치의 특징은 각각 전용 전처리 파이프라인을 거쳐 정규화된 임베딩으로 변환된 뒤, 차원 맞춤 과정을 통해 동일한 토큰 시퀀스로 결합된다.
핵심은 수정된 Vision Transformer이다. 기존 ViT는 이미지 분류에 최적화돼 있었지만, 여기서는 토큰 수를 제한하고 헤드 수를 4개, 레이어를 2개로 축소해 연산량을 크게 낮췄다. 멀티‑헤드 어텐션은 스펙트로그램 토큰 간뿐 아니라 스펙트로그램‑오디오 토큰 간 상호작용도 포착해, 잡음과 음성의 복합적인 시간‑주파수 상관관계를 효과적으로 모델링한다. 잔차 연결과 레이어 정규화를 적용해 깊은 네트워크에서도 그래디언트 소실을 방지하고 학습 안정성을 확보하였다.
마스크 예측은 두 종류로 설계되었다. 첫 번째는 청음 신호 에너지 기반의 Clean‑Mask(M_FFT)이며, 두 번째는 잡음 에너지 기반 Noise‑Mask(M_wav)이다. 두 마스크는 각각 Gaussian 스무딩 필터를 통과시켜 부드럽게 만든 뒤, 혼합 신호의 magnitude에 곱해 청음과 잡음 스펙트럼을 복원한다. 복원된 magnitude와 원본 혼합 신호의 위상을 결합해 IFFT를 수행, 최종적으로 시간 영역의 청음 파형을 얻는다. 후처리 단계에서는 40‑Hz~4 kHz 대역통과 필터를 적용해 인간 음성 대역 외의 잔여 잡음을 억제한다.
실험은 Librispeech(900 utterances)와 UrbanSound8K·Google Audioset 잡음 데이터를 사용해 0 dB, 3 dB, 10 dB, ‑3 dB 네 가지 SNR 조건에서 수행되었다. 평가 지표인 PESQ, STOI, Seg‑SNR, LLR 모두 기존 DNN·CNN·LSTM 기반 모델 대비 평균 0.20.4 dB(또는 0.030.07) 향상을 기록했으며, 특히 비정상적 잡음 구간에서 STOI 상승폭이 두드러졌다. 프레임 길이 16 ms(128 samples)와 경량화된 모델 구조 덕분에 전체 파이프라인 지연이 30 ms 이하로 유지돼 실시간 적용이 가능함을 확인하였다.
한계점으로는 8 kHz 저샘플링으로 인해 고주파 세부 정보가 손실될 수 있고, 현재는 단일 채널 입력만 지원한다는 점이다. 또한, 마스크 기반 복원 방식은 위상 왜곡에 민감해, 복잡한 다중 스피커 환경에서는 추가적인 위상 보정 모듈이 필요할 것으로 보인다. 향후 연구에서는 다채널 입력, 고해상도 샘플링, 그리고 self‑supervised 사전학습을 결합해 더욱 일반화된 잡음 억제 시스템을 구축할 여지가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기