퍼지 라벨을 활용한 라벨 학습 혁신
안내: 본 포스트의 한글 요약 및 분석 리포트는 AI 기술을 통해 자동 생성되었습니다. 정보의 정확성을 위해 하단의 [원본 논문 뷰어] 또는 ArXiv 원문을 반드시 참조하시기 바랍니다.
초록
본 논문은 라벨 학습에서 발생하는 불확실성을 효과적으로 다루기 위해 퍼지 집합 이론에 기반한 퍼지 라벨 개념을 도입한다. 기존의 이진 라벨이 갖는 한계를 극복하고, 데이터와 인간 주석자의 주관적·모호한 특성을 반영한 퍼지 라벨을 자동으로 생성하는 효율적인 방법을 제시한다. 이를 바탕으로 K‑Nearest Neighbors 기반의 단일 라벨 및 다중 라벨 학습 알고리즘을 확장하여 실험적으로 성능 향상을 입증한다.
상세 분석
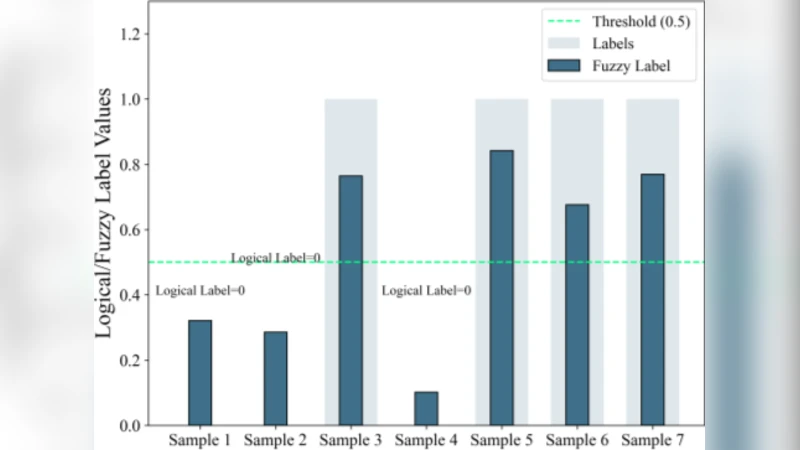
본 연구는 라벨 학습의 근본적인 가정인 “라벨은 명확히 정의된 이진 값이다”라는 전제를 비판하고, 실제 데이터 수집·주석 과정에서 발생하는 잡음, 모호성, 주관성 등을 정량화할 필요성을 강조한다. 이를 위해 퍼지 집합 이론을 도입해 라벨을 0과 1 사이의 연속적인 멤버십 값으로 표현한다는 아이디어는 기존의 확률적 접근과 차별화된다. 퍼지 라벨은 ‘이 라벨에 속할 가능성’이라는 의미를 내포하며, 이는 라벨 불확실성을 직접 모델에 전달함으로써 학습 단계에서 보다 풍부한 정보를 활용하게 만든다.
논문에서 제안한 퍼지 라벨 생성 방법은 원본 데이터와 기존 이진 라벨을 이용해 각 라벨에 대한 멤버십 함수를 추정한다. 구체적으로, K‑Nearest Neighbors 기반의 지역적 밀도 추정과 라벨 간 상관관계를 고려한 가중 평균을 통해 각 인스턴스‑라벨 쌍에 대한 퍼지 값 μ∈
댓글 및 학술 토론
Loading comments...
의견 남기기