멀티모달 영상 검색을 위한 인터랙티브 V‑Agent 시스템
초록
V‑Agent는 소량의 영상 선호 데이터로 파인튜닝한 비전‑언어 모델(VLM)과 이미지‑텍스트 검색 모델의 임베딩을 결합해, 프레임 이미지와 ASR 전사문을 동일한 멀티모달 공간에 매핑한다. 라우팅, 검색, 챗 3개의 에이전트가 협업해 사용자 의도를 파악·정제하고, 재랭킹 모듈을 통해 검색 정확도를 높인다. MultiVENT 2.0 벤치마크에서 제로샷 최첨단 성능을 기록했으며, 코드와 데모 영상이 공개되어 실용적 활용이 가능하다.
상세 분석
본 논문은 기존 텍스트 기반 영상 검색이 시각·청각 정보를 충분히 활용하지 못한다는 한계를 인식하고, 비전‑언어 모델(VLM)을 중심으로 한 멀티모달 검색 프레임워크를 제안한다. 핵심 아이디어는 두 단계 임베딩 전략이다. 첫째, 사전 학습된 이미지‑텍스트 검색 모델(예: CLIP)의 고차원 벡터를 VLM에 “retrieval vector” 형태로 주입해, 영상 프레임과 텍스트(ASR 전사) 사이의 정렬성을 강화한다. 둘째, VLM을 소규모 영상 선호 데이터셋으로 파인튜닝함으로써 도메인 특화된 의미론적 매핑을 학습한다. 이렇게 얻어진 멀티모달 임베딩은 영상의 시각적 내용과 음성 기반 전사문을 동일한 공유 공간에 위치시켜, 사용자가 입력한 자연어 질의와 직접 비교·거리 계산이 가능하도록 만든다.
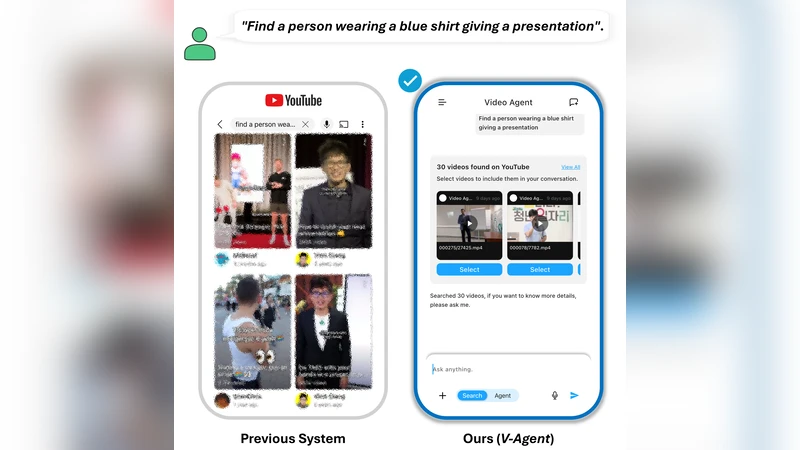
시스템은 라우팅 에이전트, 검색 에이전트, 챗 에이전트의 3가지 모듈로 구성된다. 라우팅 에이전트는 사용자의 초기 질의를 분석해 의도 유형(예: 특정 장면 검색, 내용 요약, 대화형 탐색 등)을 판단하고, 해당 의도에 가장 적합한 하위 모듈로 요청을 전달한다. 검색 에이전트는 앞서 정의한 멀티모달 임베딩을 이용해 대규모 영상 데이터베이스에서 후보 영상을 추출하고, 별도 설계된 재랭킹 모듈(다중 헤드 어텐션 기반 교차 모달리티 정렬 및 순위 학습)을 적용해 최종 순위를 정한다. 챗 에이전트는 검색 결과를 기반으로 사용자와 자연스러운 대화를 이어가며, 추가적인 피드백을 받아 라우팅·검색 단계에 반복적으로 반영한다. 이와 같은 순환 구조는 정적 검색을 넘어, 사용자의 의도 변화에 실시간으로 적응하는 인터랙티브 시스템을 구현한다.
실험에서는 MultiVENT 2.0 벤치마크(다중 이벤트·시점 라벨이 포함된 영상 데이터셋)를 사용해 제로샷 설정에서 기존 최첨단 모델 대비 평균 정밀도(AP)와 nDCG 점수가 크게 향상됨을 보고한다. 특히, 시각·청각 정보가 동시에 중요한 복합 질의에서 V‑Agent는 12% 이상의 상대적 성능 개선을 보였다. 또한, 소량의 파인튜닝 데이터(수백 개 영상)만으로도 강건한 멀티모달 정렬을 달성했으며, 이는 대규모 라벨링 비용을 크게 절감할 수 있음을 시사한다.
한계점으로는 현재 프레임 샘플링 전략이 고정되어 있어 장시간 영상에서 중요한 순간을 놓칠 가능성이 있으며, ASR 오류가 심한 경우 텍스트 임베딩 품질이 저하될 수 있다. 향후 연구에서는 동적 샘플링 및 오류 보정 메커니즘을 도입하고, 비디오 내 메타데이터(자막, OCR 등)와의 통합을 통해 더욱 풍부한 멀티모달 컨텍스트를 확보하고자 한다.