μP에서 학습률 전이 증명
초록
본 논문은 선형 다층 퍼셉트론(MLP)을 μP(Maximal Update Parametrization)로 파라미터화했을 때, 모델 폭이 무한대로 커져도 최적 학습률이 양의 상수로 수렴한다는 최초의 엄밀한 증명을 제시한다. 반면 표준 파라미터화(SP)와 신경탄젠트 파라미터화(NTP)에서는 최적 학습률이 0으로 수렴하거나 발산하여 학습률 전이가 성립하지 않음을 보인다. 이론적 결과를 뒷받침하기 위해 다층 깊이와 다양한 옵티마이저에 대한 광범위한 실험을 수행하였다.
상세 분석
논문은 먼저 μP가 “특징 학습을 최대화”하도록 설계된 파라미터화임을 강조하고, 이를 통해 폭이 커질수록 초기화와 학습률 스케일링이 특정 지수(αℓ, αV, c)로 고정된다는 정의를 제시한다. μP에서는 모든 은닉층 가중치가 1/√n 스케일로 초기화되고, 출력 가중치 V는 1/n 스케일로 초기화된다. 학습률은 GD의 경우 폭에 무관한 상수 η, Adam의 경우 η·n 형태로 스케일링된다.
핵심 증명은 손실 함수 L⁽ᵗ⁾ₙ(η)를 η에 대한 다항식으로 전개하고, 각 차수의 계수 ϕₖ가 폭 n에 따라 어떻게 수렴하는지를 분석한다. 1차 계수 ϕ₁은 강법칙에 의해 거의 확정적인 양의 값으로 수렴하지만, 2차 이상 계수 ϕₖ(k≥2)는 L² 의미에서 0으로 수렴한다. 따라서 손실은 η에 대한 거의 2차 이하의 다항식 형태가 되며, 최적 η는 ϕ₁에 의해 결정되는 상수값 η* = -χ/ϕ₁(∞) 로 수렴한다. 여기서 χ는 초기 예측 오차이며, ϕ₁(∞)는 입력·출력의 2‑노름에 의해 명시적으로 계산된다.
반대로 SP에서는 출력 가중치 V가 1/√n 스케일이므로 ϕ₁ 자체가 O(1/√n)으로 사라진다. 결과적으로 최적 ηₙ은 O(√n)·η* 형태로 폭이 커질수록 0에 수렴한다. NTP는 학습률이 η·n⁻¹ 로 스케일링돼 ϕ₁이 O(1/n) 수준으로 억제돼 최적 η가 무한대로 발산하거나 의미 없는 값이 된다.
일반 단계 t에 대해서는 재귀적으로 ϕₖ(t)의 수렴성을 보이며, 각 단계마다 고차항이 사라지는 속도가 동일함을 증명한다. 따라서 모든 t에 대해 η⁽ᵗ⁾ₙ → η⁽ᵗ⁾_∞ > 0 가 성립한다.
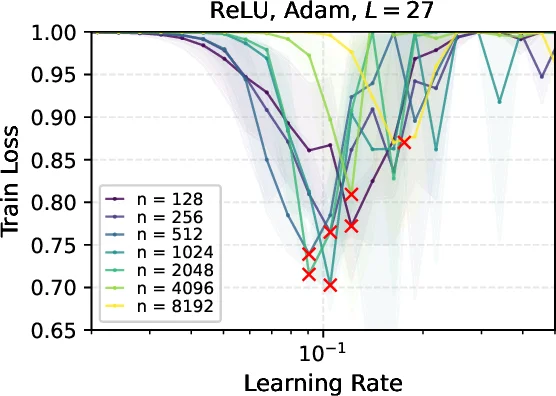
실험에서는 폭을 2¹⁰부터 2¹⁶까지 변화시키며, μP와 SP, NTP 각각에 대해 최적 학습률을 그리드 탐색했다. μP에서는 폭이 증가해도 최적 η가 거의 변하지 않으며, 학습 곡선도 겹치는 현상이 관찰되었다. 반면 SP와 NTP에서는 최적 η가 폭에 따라 급격히 감소하거나 증가해 튜닝 비용이 크게 늘어났다. 또한 ReLU, tanh, Adam, SGD 등 다양한 설정에서도 μP의 학습률 전이가 일관되게 유지됨을 확인하였다.
이 논문은 μP가 특징 학습을 유지하면서도 학습률 전이라는 실용적 현상을 이론적으로 뒷받침한다는 점에서 의미가 크다. 특히, 폭이 큰 현대 딥러닝 모델에서 작은 규모의 프리‑트레이닝을 통해 얻은 최적 하이퍼파라미터를 그대로 적용할 수 있다는 실무적 가치를 제공한다. 다만, 선형 MLP에 한정된 증명이며 비선형 활성화와 복잡한 구조(예: residual, attention)에서는 추가 연구가 필요하다.
댓글 및 학술 토론
Loading comments...
의견 남기기