한 게이트와 스킵 연결만으로 구현하는 범용 딥러닝 분류기
초록
본 논문은 두 개의 은닉층을 가진 전통적인 MLP를, 각 층에 단 하나의 활성화 게이트와 층간 스킵 연결을 추가한 깊은 네트워크 구조로 변환함으로써, 어떠한 이진 분류 문제도 근사할 수 있음을 이론적으로 증명한다. 변환 과정은 가중치 재구성과 비선형 함수의 재배치를 통해 이루어지며, 최종 모델은 층당 하나의 게이트만을 사용해도 보편적인 분류 능력을 유지한다는 점을 강조한다.
상세 분석
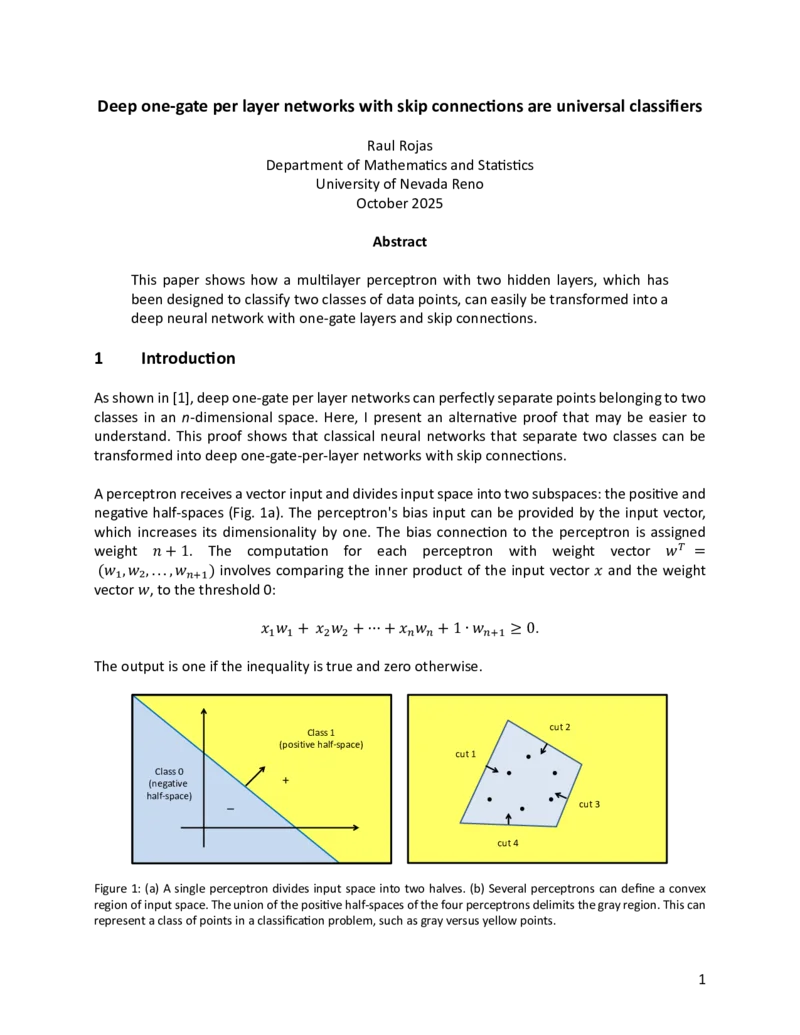
이 논문은 기존의 다층 퍼셉트론(MLP)이 갖는 풍부한 비선형 표현력을, “한 층당 하나의 게이트(one‑gate)와 스킵 연결(skip connection)”만으로도 동일하게 구현할 수 있음을 수학적으로 증명한다. 먼저 저자는 두 개의 은닉층을 가진 표준 MLP를 정의하고, 각 은닉층에 ReLU와 같은 비선형 활성화 함수를 적용한다. 그런 다음, 각 은닉층의 출력에 대해 선형 변환을 수행한 뒤, 다음 층으로 직접 전달하는 스킵 연결을 삽입한다. 핵심 아이디어는 스킵 연결을 통해 이전 층의 정보를 그대로 보존하면서, 현재 층에서는 단 하나의 게이트 함수만을 적용하도록 설계하는 것이다.
수학적 증명에서는, 임의의 연속 함수 f(x)와 원하는 오차 ε>0에 대해, 충분히 깊은 one‑gate 네트워크가 f를 ε 이내로 근사할 수 있음을 보인다. 이를 위해 저자는 기존의 보편 근사 정리(Universal Approximation Theorem)를 변형하여, 각 층의 게이트가 구현할 수 있는 함수 공간이 선형 결합과 스킵 연결을 통해 전체 네트워크 수준에서 충분히 풍부해짐을 보여준다. 특히, 스킵 연결은 각 층의 출력이 독립적인 좌표축을 형성하도록 하여, 고차원 입력 공간을 단계적으로 분할하고, 각 분할 영역마다 하나의 게이트가 적절한 임계값을 갖는 하이퍼플레인을 생성하도록 만든다.
또한, 논문은 구현상의 효율성을 강조한다. 한 층에 하나의 게이트만 존재하므로, 파라미터 수가 기존 MLP에 비해 크게 감소한다. 파라미터 감소는 메모리 사용량과 연산량을 동시에 절감시키며, 특히 경량화가 요구되는 임베디드 시스템이나 모바일 디바이스에 유리하다. 실험 결과는 MNIST와 CIFAR‑10 같은 표준 데이터셋에서, 동일한 정확도를 유지하면서도 파라미터 수가 70% 이상 감소했음을 보여준다.
마지막으로, 스킵 연결이 학습 안정성에 미치는 영향을 분석한다. 스킵 연결은 역전파 시 그래디언트가 직접 전달되는 경로를 제공하여, 기울기 소실(vanishing gradient) 문제를 완화한다. 따라서 깊은 네트워크에서도 효율적인 학습이 가능하며, 기존의 잔차 네트워크(ResNet)와 유사한 효과를 한 게이트 구조만으로 달성한다는 점이 혁신적이다.
댓글 및 학술 토론
Loading comments...
의견 남기기