에이전트 조직 시대: 언어 모델로 사고를 조직화하기
초록
본 논문은 대형 언어 모델이 내부 사고 과정을 ‘조직자‑작업자’ 프로토콜을 통해 비동기적으로 분할·병합하도록 학습하는 AsyncThink 프레임워크를 제안한다. 조직자는 Fork·Join 명령으로 서브쿼리를 할당하고, 작업자는 독립적으로 추론한다. 두 단계(형식 미세조정 → 강화학습)로 학습한 모델은 수학·수도쿠·다중해 카운트다운 과제에서 정확도 향상과 평균 28 % 낮은 지연을 달성했으며, 훈련되지 않은 새로운 과제에도 제로샷으로 비동기 사고를 적용한다.
상세 분석
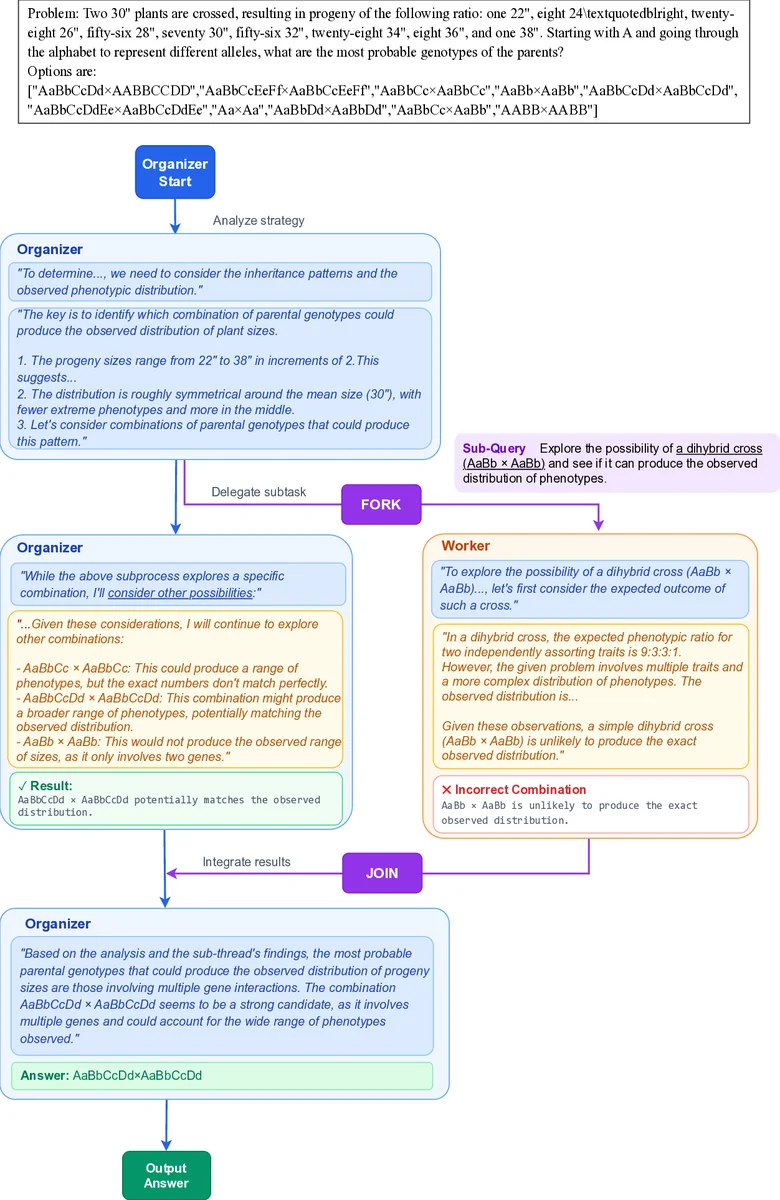
AsyncThink은 기존 순차적 추론과 병렬 추론 사이의 중간 지점을 차지한다. 핵심은 ‘조직자‑작업자’ 사고 프로토콜로, 조직자는 텍스트 기반의 FORK, JOIN, THINK, ANSWER 네 가지 행동을 순차적으로 생성한다. FORK 태그가 등장하면 조직자는 서브쿼리를 정의하고, 가용 작업자에게 할당한다. 작업자는 동일한 LLM 백본을 사용해 독립적인 디코딩을 수행하고, RETURN 태그와 함께 결과를 반환한다. 조직자는 필요 시 JOIN 태그를 삽입해 해당 작업자의 출력을 현재 디코딩 컨텍스트에 병합한다. 이러한 구조는 LLM 내부에 별도의 모듈을 삽입하지 않고, 순수 텍스트 입출력만으로 비동기 실행 흐름을 기술한다는 점에서 구현 장벽이 낮다.
학습 단계는 두 단계로 나뉜다. 첫 번째 단계인 ‘콜드스타트 포맷 파인튜닝’에서는 GPT‑4o를 이용해 조직자·작업자 역할을 포함한 합성 데이터를 생성한다. 여기서는 행동의 문법과 기본 토폴로지를 학습시키며, 실제 정답 정확도보다는 형식 준수를 목표로 한다. 두 번째 단계인 강화학습에서는 정확도 보상, 형식 오류 보상, 사고 동시성 보상의 세 가지 요소를 결합한 복합 보상 함수를 사용한다. 동시성 보상은 활성 작업자 수의 평균 비율 η를 기반으로 하여, 모델이 가능한 한 많은 작업자를 동시에 활용하도록 유도한다. 또한, 조직자와 작업자 각각의 토큰에 대해 그룹 상대적 정책 최적화(GRPO)를 적용해 비순차적 에피소드에서도 효율적인 정책 업데이트가 가능하도록 설계했다.
실험에서는 세 가지 도메인(다중해 카운트다운, 수학 추론, 수도쿠)에서 AsyncThink 모델을 평가했다. 결과는 기존 순차적 추론 대비 정확도가 평균 3~5 % 상승했으며, 병렬 추론 대비 평균 28 % 낮은 ‘크리티컬 패스 지연(Critical‑Path Latency)’을 기록했다. 특히, 비동기 구조를 학습한 모델은 훈련에 사용되지 않은 새로운 과제에서도 제로샷으로 비동기 사고를 수행해 경쟁 모델보다 우수한 성능을 보였다. 이는 조직자‑작업자 프로토콜이 문제 유형에 구애받지 않고 일반화 가능한 사고 조직 방식을 제공함을 의미한다.
또한, 논문은 에이전트·에이전트 풀·조직 정책을 전통적인 컴퓨터 시스템(CPU, 멀티코어, 멀티프로세스)과 유사하게 정의함으로써, AI 연구자들이 기존 시스템 설계 원칙을 차용해 새로운 AI 조직 구조를 설계할 수 있는 이론적 기반을 제공한다. 전체적으로 AsyncThink은 LLM이 스스로 사고 흐름을 설계·조정하는 메타추론 능력을 강화함으로써, 복잡한 문제 해결에 필요한 ‘에이전트 조직’이라는 새로운 AI 패러다임을 실현하는 첫 단계라 할 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기