균일에서 적응으로 PDE 신경 연산자를 위한 효율적인 스킵‑블록 메커니즘
초록
본 논문은 Transformer 기반 신경 연산자에 토큰별 연산 깊이를 동적으로 조절하는 Skip‑Block Routing(SBR) 프레임워크를 제안한다. 전역 라우터가 입력 토큰의 중요도를 사전 평가하고, 이후 레이어별 sparsity schedule에 따라 중요한 토큰만 깊게 처리함으로써 FLOPs를 약 50% 절감하고 추론 속도를 2배 가량 향상시키면서도 정확도 손실을 최소화한다.
상세 분석
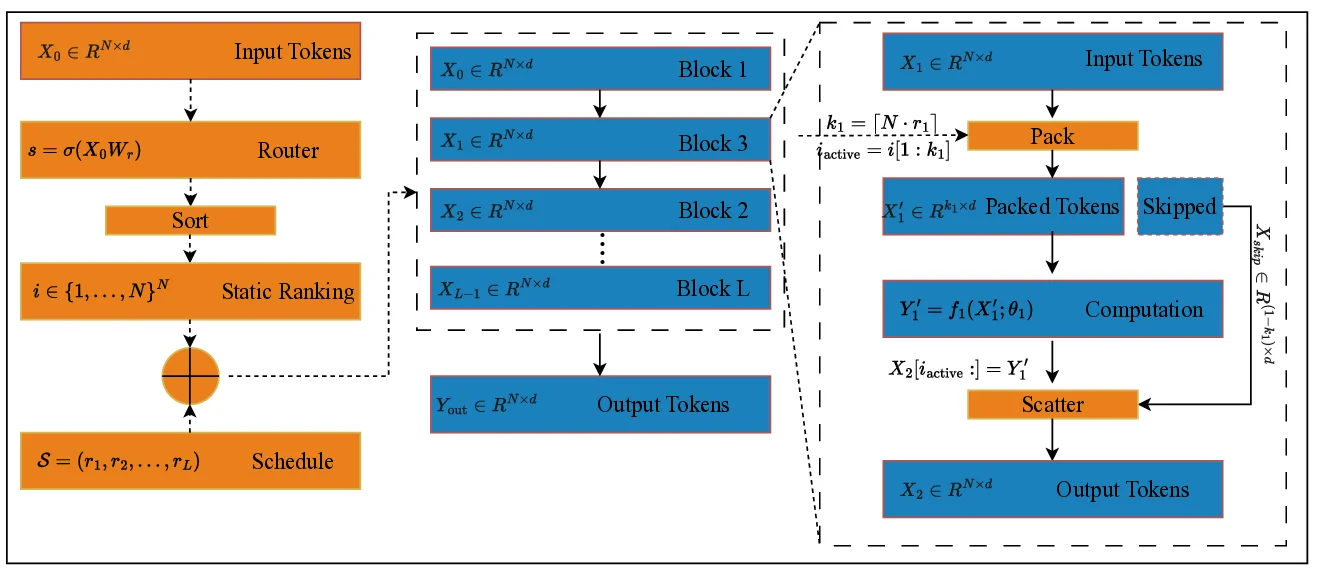
SBR은 크게 두 단계로 구성된다. 첫 번째는 Global Router Module로, 입력 토큰 행렬 X₀∈ℝ^{N×d}에 단일 선형 변환 W_r∈ℝ^{d×1}을 적용하고 시그모이드 σ를 통해 각 토큰에 0~1 사이의 중요도 점수 s를 부여한다. 이 점수는 토큰을 내림차순으로 정렬한 인덱스 벡터 i를 생성하는데, 이 정렬은 전체 순전파 과정에서 고정된다. 즉, 라우터는 한 번만 실행되어 “컴퓨팅 로드맵”을 제공한다는 점에서 기존의 레이어별 동적 라우팅과 차별화된다.
두 번째는 Adaptive Processing Backbone이다. 사용자는 레이어별 토큰 유지 비율 r_l∈(0,1]을 정의하는 sparsity schedule S=(r₁,…,r_L)를 지정한다. 각 레이어 l에서는 k_l=⌈N·r_l⌉ 개의 토큰을 i의 상위 k_l 인덱스로 선택하고, pack 연산을 통해 X’ₗ∈ℝ^{k_l×d} 로 압축한다. 이후 self‑attention, MLP 등 고비용 연산을 이 압축된 행렬에만 수행하고, 결과 Y’_ₗ를 scatter 연산으로 원래 위치에 복원한다. 이때 비활성 토큰은 residual 연결을 통해 그대로 전달되므로 정보 손실이 최소화된다.
핵심 기술적 장점은 다음과 같다. ① 라우터가 전역적이며 정적인 중요도 순위를 제공하므로, 하드웨어 측면에서 gather‑scatter 패턴이 효율적으로 구현될 수 있다. ② pack‑scatter 연산이 미분 가능하므로 별도 강화학습이나 보조 손실 없이 end‑to‑end 학습이 가능하다. ③ sparsity schedule을 사용자가 직접 설계할 수 있어, 초기 레이어에서 전역 컨텍스트를 충분히 확보하고, 깊은 레이어에서는 물리적으로 복잡한 영역에만 연산을 집중하도록 조정할 수 있다.
실험에서는 NS2D, Airfoil, Pipe, Heat2D 등 다양한 PDE 벤치마크에 OFormer, GNO‑T, Transolver, IPO‑T 등 최신 Transformer 기반 연산자를 기반으로 SBR을 적용하였다. FLOPs 기준 50% 절감, 실제 추론 시간 1.8~2.2배 가속을 달성했으며, 평균 L2 오차는 0.5% 이하로 기존 모델과 거의 동일한 수준을 유지했다. 특히, 복잡한 소용돌이 영역이나 급격한 경계 변화가 있는 데이터셋에서 SBR이 선택적으로 깊은 레이어를 할당함으로써 정확도 저하 없이 효율성을 크게 높인 것이 눈에 띈다.
한계점으로는 라우터가 한 번만 평가되므로 입력마다 동적으로 변하는 복잡도(예: 시간에 따라 급격히 변하는 현상)를 완전히 포착하지 못할 수 있다. 또한 sparsity schedule을 수동으로 설계해야 하는 부담이 존재한다. 향후 연구에서는 라우터를 다중 단계로 확장하거나, 메타‑러닝을 통해 자동으로 최적 schedule을 학습하는 방향이 제안될 수 있다.
전반적으로 SBR은 물리적 복잡도와 연산 자원을 정렬시키는 새로운 패러다임을 제시하며, 대규모 엔지니어링 시뮬레이션에서 신경 연산자의 실용성을 크게 향상시킬 잠재력을 가진다.
댓글 및 학술 토론
Loading comments...
의견 남기기