과학 머신러닝을 위한 공통 과제 프레임워크 제안
초록
**
본 논문은 물리·생물·공학 분야의 동적 시스템에 특화된 머신러닝 알고리즘을 객관적으로 비교·평가하기 위한 “Common Task Framework (CTF)”를 설계한다. Kuramoto‑Sivashinsky와 Lorenz 시스템을 이용해 예측·재구성·노이즈·데이터 제한·파라미터 일반화 등 12가지 세부 과제를 정의하고, 각각을 RMSE와 스펙트럼 기반 점수로 정량화한다. 다중 점수 체계와 레이더 플롯을 통해 알고리즘의 강점·약점을 시각화하고, Kaggle 기반 대회와 GitHub 패키지를 제공해 커뮤니티 참여를 촉진한다.
**
상세 분석
**
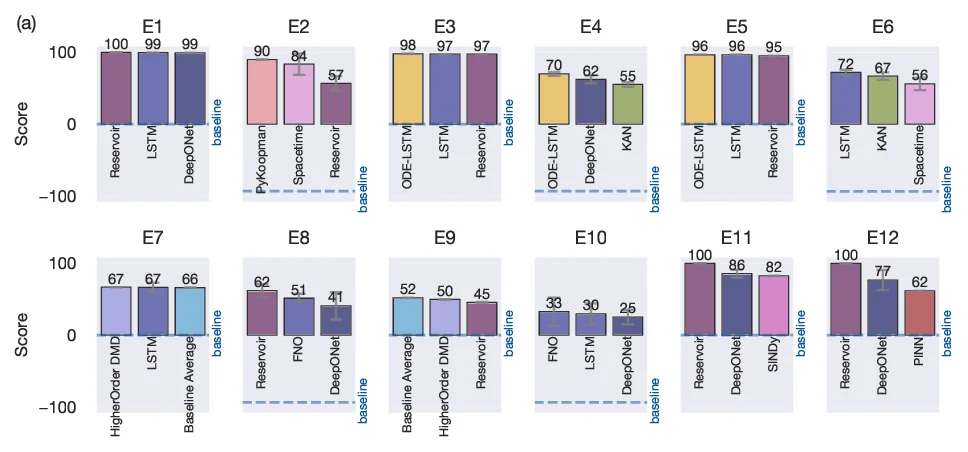
이 논문은 과학·공학 분야에서 머신러닝 모델의 성능을 일관되게 측정할 수 있는 표준 벤치마크가 부재함을 지적하고, 이를 해결하기 위한 CTF를 제안한다. 핵심 아이디어는 “다중 메트릭” 접근법이다. 단일 정확도 점수 대신 12개의 세부 점수를 정의해, 단기 예측(RMSE), 장기 예측(스펙트럼 오류), 노이즈 복원, 제한된 데이터 상황, 파라미터 변동에 대한 일반화 능력 등을 각각 별도 점수(E₁E₁₂)로 환산한다. 점수는 0100 사이의 백분율 형태로 표현되며, 0점은 제로 베이스라인(예: 모든 값을 0으로 예측)과 동일함을 의미한다.
데이터셋은 두 개의 대표적인 비선형 동적 시스템, Kuramoto‑Sivashinsky(KS)와 Lorenz 방정식으로 구성된다. KS는 1차원 공간에 대한 4차 비선형 PDE로, 혼돈적 스펙트럼 특성을 갖는다. Lorenz는 3차원 ODE로, 전형적인 카오스 어트랙터를 제공한다. 각각에 대해 훈련·테스트 데이터를 10배 시간 길이로 제공하고, 테스트는 다음 네 가지 시나리오로 나뉜다: (1) 기본 예측, (2) 노이즈가 섞인 데이터 복원·예측, (3) 스냅샷 수가 제한된 상황, (4) 파라미터 값이 변하는 일반화 테스트.
점수 계산식은 간단하면서도 투명하게 설계되었다. 단기 예측 점수(E₁, E₃, E₇, E₁₁ 등)는 예측 행렬과 실제 행렬 사이의 Frobenius norm 비율을 사용하고, 장기 예측 점수(E₂, E₄, E₈ 등)는 파워 스펙트럼의 L2 차이를 기반으로 한다. 파라미터 일반화는 인터폴레이션과 엑스트라폴레이션 두 경우를 각각 단기 RMSE로 평가한다.
다중 점수를 종합해 “복합 점수”를 산출하고, 레이더 플롯으로 시각화한다. 이는 특정 알고리즘이 어느 과제에서 강하고 어느 과제에서 약한지를 한눈에 파악하게 해준다. 논문은 또한 다양한 기존 모델(DeepONet, KAN, LSTM, ODE‑LSTM, Reservoir 등)의 성능을 실험적으로 비교하고, 평균 점수와 레이더 플롯을 통해 차이를 명확히 보여준다.
플랫폼 구현 측면에서, 저자들은 Kaggle을 활용한 대회와 GitHub에 공개된 ctf4science 파이썬 패키지를 제공한다. 패키지는 데이터 로딩, 전처리, 점수 계산을 자동화하며, 일반적인 랩톱 수준의 하드웨어에서도 실행 가능하도록 설계되었다. 이는 재현성을 크게 향상시키고, 연구자들이 손쉽게 새로운 알고리즘을 시험할 수 있게 한다.
한계점으로는 현재 두 개의 시스템에만 초점을 맞추었다는 점이다. 실제 과학·공학 문제는 고차원, 멀티스케일, 비정형 데이터 등을 포함하므로, 향후 데이터셋 확장이 필요하다. 또한 장기 예측 점수에 사용된 스펙트럼 기반 메트릭은 특정 주파수 대역에 민감하므로, 다른 분야에서는 추가적인 메트릭이 요구될 수 있다.
전반적으로 이 프레임워크는 과학 머신러닝 분야에서 “공정한 경쟁”을 가능하게 하는 중요한 인프라를 제공한다. 다중 메트릭 설계, 투명한 점수 체계, 커뮤니티 기반 대회 운영은 향후 연구 방향을 제시하고, 알고리즘 선택에 실질적인 가이드를 제공한다.
**
댓글 및 학술 토론
Loading comments...
의견 남기기