LyriCAR 난이도 인식 커리큘럼 강화학습 기반 가사 번역 프레임워크
초록
LyriCAR는 가사 번역을 위해 음악적 제약(리듬·라임·형식)과 의미 전달을 동시에 고려하는 완전 비지도 학습 프레임워크이다. 난이도 기반 커리큘럼 설계와 보상 수렴을 감지하는 적응형 스테이지 전환 전략을 도입해 학습 효율을 높이고, 다중 차원 보상을 이용해 강화학습으로 모델을 최적화한다. EN‑ZH 가사 번역 실험에서 BLEU·COMET 등 기존 지표와 자체 설계한 리듬·라임·텍스트 품질 점수 모두에서 최첨단 성능을 달성했으며, 학습 단계 수를 약 40 % 절감했다.
상세 분석
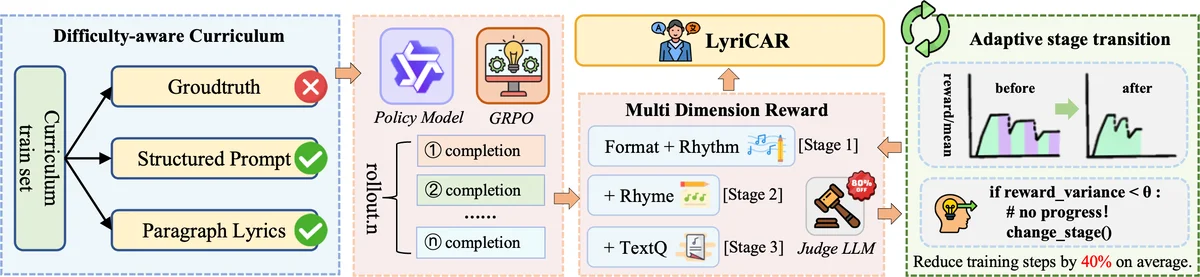
LyriCAR는 기존 가사 번역 연구가 안고 있던 네 가지 주요 한계를 체계적으로 해결한다. 첫째, 수작업 규칙이나 히ュー리스틱 디코딩에 의존하지 않고, 원시 영어 가사 단락만을 이용해 난이도를 자동 측정한다. 난이도 평가는 BERT‑perplexity와 LIWC‑기반 어휘·구문·라임 밀도 지표를 결합해 Easy·Medium·Hard 세 단계로 데이터셋을 계층화한다. 이렇게 계층화된 데이터는 커리큘럼 학습의 ‘쉬운 → 어려운’ 순서를 자연스럽게 제공한다.
둘째, 강화학습 단계에서는 Qwen‑3‑8B 대형 언어 모델을 베이스로 사용하고, 네 가지 보상 함수를 정의한다. 포맷 보상(R_fmt)은 특수 토큰 유지 여부를, 리듬 보상(R_rtm)은 목표 음절 수와 출력 길이의 차이를, 라임 보상(R_rym)은 인접 구절 간 라임 유사도, 텍스트 품질 보상(R_txtQ)은 프롬프트 기반 Judge LLM을 통해 얻은 3‑레벨(‑1,0,1) 점수를 각각 측정한다. 각 보상의 가중치 λ_i는 사전 실험을 통해 조정되며, 최종 보상은 가중합으로 결합된다.
셋째, 보상 신호를 외부 패널티가 아니라 정책 자체가 학습하도록 설계한 점이 핵심이다. LyriCAR는 Group Relative Policy Optimization(GRPO)을 적용해 동일 그룹 내 후보들의 평균 보상과 비교해 상대적 어드밴티지를 계산한다. 이는 다중 목표 간 트레이드오프를 모델이 스스로 파악하도록 유도한다. 수식 (6)·(7)에서 보이는 바와 같이, 후보 k의 어드밴티지는 R_k − (1/|g|)∑_j R_j 로 정의되고, 정책 파라미터 θ는 이 어드밴티지를 최대화하도록 업데이트된다.
넷째, 학습 효율을 극대화하기 위해 보상 수렴을 실시간 모니터링한다. 일정 에폭마다 검증 보상의 슬라이딩 윈도우 분산을 계산하고, 분산이 사전 설정된 임계값 τ 이하로 일정 기간(k epochs) 지속되면 현재 커리큘럼 스테이지를 종료하고 다음 난이도 단계로 전이한다. 이 적응형 스테이지 전환 메커니즘은 ‘쉬운 단계에서 빠르게 수렴 → 어려운 단계에서 충분히 학습된 뒤 전이’라는 인간 교사의 교육 방식을 모방한다.
실험에서는 DALI 데이터셋에서 EN‑ZH 가사 6,984곡을 추출해 각 스테이지당 9,600문단을 구성하였다. 학습은 8×A800 GPU에서 진행됐으며, 난이도별 학습률을 1e‑6, 5e‑7, 1e‑7 로 점진적으로 감소시켰다. 결과적으로 LyriCAR‑Full(전체 데이터)보다 스테이지 기반 LyriCAR‑SS(정적)와 LyriCAR‑SD(동적)에서 BLEU 20.45→21.37, COMET 79.82→81.12 등 모두 향상되었으며, 특히 동적 커리큘럼은 학습 스텝을 34 % 절감하면서도 보상 점수(Rhythm 0.70, Rhyme 0.77, Text 0.7)에서 최고치를 기록했다.
요약하면, LyriCAR는 (1) 난이도 기반 데이터 계층화, (2) 다중 차원 보상 설계, (3) 그룹 상대 정책 최적화, (4) 보상 수렴 기반 적응형 커리큘럼이라는 네 축을 결합해, 비지도 환경에서도 가사 번역의 음악적·언어적 품질을 동시에 끌어올렸다. 이는 기존 규칙 기반·문장 수준 접근법이 갖는 확장성·효율성 한계를 근본적으로 타파한 혁신적 접근이라 할 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기