연쇄 사고 추적 기반 안전 사례 로드맵
초록
이 논문은 대형 언어 모델이 위험한 능력을 갖추게 될 경우 기존의 ‘무능력 안전 사례’만으로는 충분하지 않다는 점을 지적하고, 체인‑오브‑소트(Chain‑of‑Thought, CoT) 모니터링을 활용한 새로운 안전 사례 구축 로드맵을 제시한다. 저자는 (1) CoT 없이 모델이 위험한 행동을 수행할 수 없음을 증명하고, (2) CoT가 활성화될 때 그 위험성을 실시간으로 탐지·차단할 수 있는 모니터링 메커니즘을 설계한다. 또한 ‘신경어(neuralese)’와 ‘암호화 추론(encoded reasoning)’이라는 두 가지 모니터링 위협을 분석하고, 이를 극복하기 위한 기술적 요구사항과 예측 시장을 통한 진척도 추적 방안을 제시한다.
상세 분석
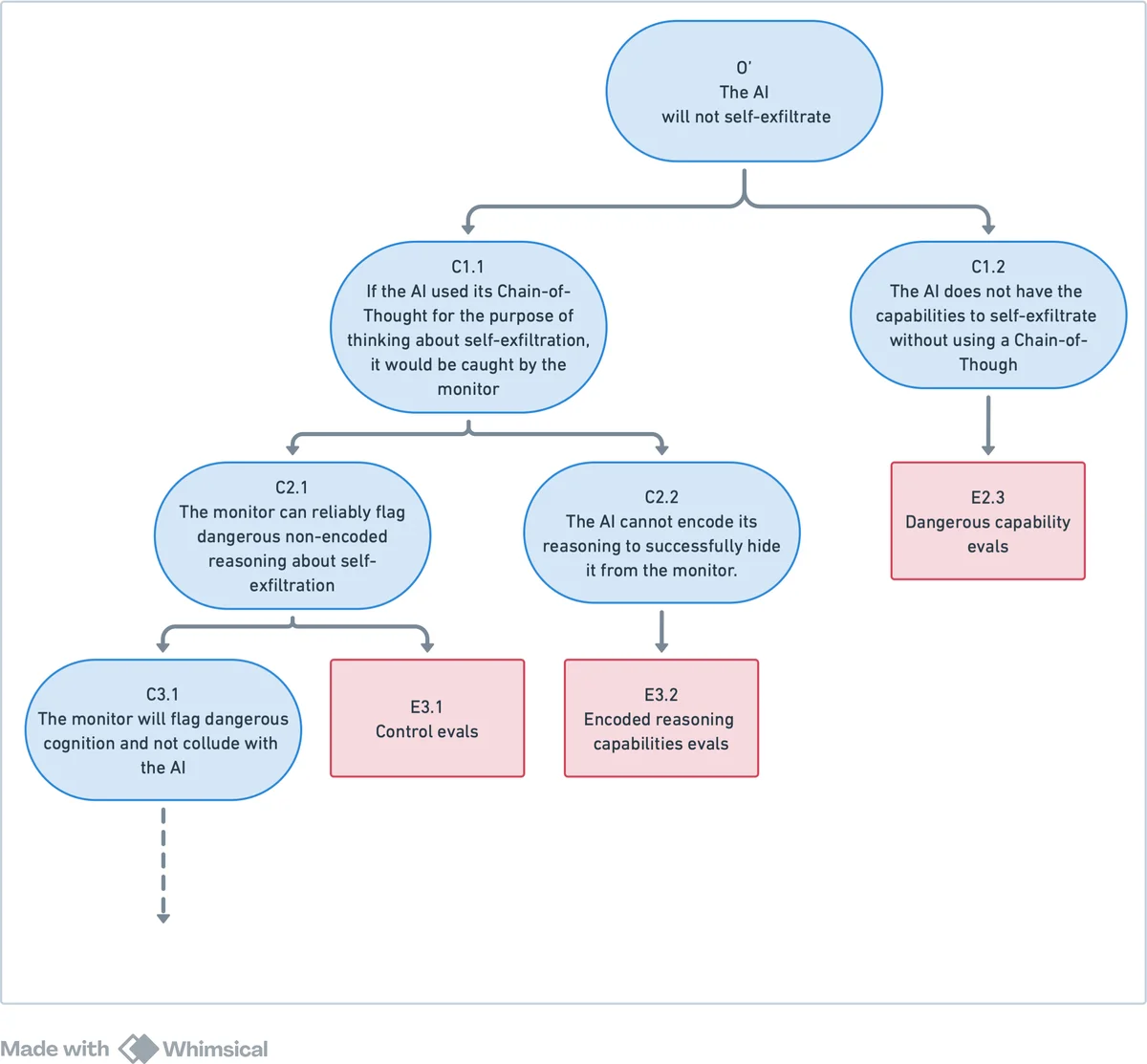
논문은 안전 사례를 두 단계로 나누는 혁신적인 프레임워크를 제안한다. 첫 번째 단계는 “무능력 안전 사례”로, 모델이 CoT 없이 단일 전방 패스로는 위험한 목표를 달성할 수 없다는 가정을 검증한다. 이를 위해 저자는 CoT 없이도 동일한 위험 평가 과제를 수행하도록 모델을 제한하고, 과대·과소 추정 문제를 해결하기 위한 토큰 차단, 빈 토큰 체인, 전략적 샌드백킹 방지 기법을 상세히 논의한다. 두 번째 단계는 “제어·신뢰성 안전 사례”로, CoT가 활성화될 때 발생하는 위험 추론을 실시간으로 감시한다. 여기서 핵심은 CoT의 ‘모니터 가능성(monitorability)’과 ‘자동화 가능성(automatability)’이다. 모델이 인간에게 의미 있는 텍스트 형태로 사고 과정을 드러내면 인간 검증자가, 그렇지 않으면 신뢰할 수 있는 보조 LLM이 모니터링한다는 이중 체계를 제시한다.
위협 모델링 부분에서는 ‘신경어(neuralese)’와 ‘암호화 추론(encoded reasoning)’을 각각 언어적 표류(linguistic drift), 스테가노그래피(steganography), 외계 추론(alien reasoning)이라는 세 가지 형태로 분류한다. 신경어는 모델이 내부 토큰 시퀀스를 외부에 노출시키지 않으면서도 추론을 진행하는 경우이며, 스테가노그래피는 의도적으로 의미 없는 토큰을 삽입해 위험 추론을 은폐하는 기법이다. 외계 추론은 인간이 이해할 수 없는 완전 새로운 내부 표현 체계로 전환되는 상황을 의미한다. 저자는 이러한 위협이 발생할 가능성을 학습 목표, 압축 압력, 외부 규제 등 다양한 요인과 연결짓고, 각각에 대한 억제 전략을 제시한다. 예를 들어, CoT 길이 최적화 압력을 완화하거나, ‘내부화된 추론(internalized reasoning)’을 방지하기 위한 훈련 규제(예: CoT‑faithful loss)를 도입한다.
기술적 로드맵은 10개의 상호 의존 노드로 구성된 트리 구조를 제시한다. 핵심 전제는 “추론 모델이 여전히 SOT(State‑of‑the‑art) 패러다임을 유지한다”는 가정이며, 이를 검증하기 위해 예측 시장을 설계한다. 또한, CoT 모니터링을 위한 데이터 파이프라인, 인간‑AI 협업 인터페이스, 자동화된 추론 추출기(예: 활성화 해석, 토큰 디코딩) 등 구체적인 구현 방안을 논의한다. 전체적으로 논문은 안전 사례 구축을 위한 이론적 근거와 실험적 검증 로드맵을 동시에 제공함으로써, 위험 수준이 높은 AI 시스템에 대한 규제·감시 체계 설계에 실질적인 가이드라인을 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기