다양한 선호를 위한 직접 선호 최적화와 삼항 선호의 필요성
초록
본 논문은 기존 RLHF와 DPO가 가정하는 동질적 선호를 넘어, 사용자 선호의 이질성을 모델링한다. 이론적으로 이진 비교만으로는 잠재적 선호 유형을 식별할 수 없으며, 최소 세 개 이상의 선택지를 제시하는 삼항 선호가 필요함을 증명한다. 이를 기반으로 EM‑DPO라는 기대‑최대화 기반 클러스터링 알고리즘을 제안해 숨겨진 선호 그룹을 발견하고 각 그룹에 맞는 LLM을 학습한다. 이후 최소‑최대 후회(min‑max regret) 공정성 기준으로 여러 모델을 하나의 정책으로 합치는 MMRA 알고리즘을 설계한다. 실험을 통해 삼항 선호가 이진 선호보다 더 높은 식별 정확도와 성능을 보이며, 제안된 파이프라인이 다양한 사용자에게 공정하고 개인화된 응답을 제공함을 확인한다.
상세 분석
이 논문은 크게 세 가지 과학적·공학적 기여를 제시한다. 첫째, 경제학·계량경제학에서 사용되는 선택 이론을 LLM 선호 학습에 도입해, “식별 가능성(identifiability)”이라는 개념을 정량화한다. 저자는 이론적으로 이진 비교(두 개 응답 중 선호)만으로는 잠재적 선호 유형(라틴트 팩터 Z)을 구분할 수 없으며, 각 사용자가 세 개 이상의 응답 중 하나를 선택하도록 하면 충분히 식별 가능함을 증명한다. 이는 데이터 수집 단계에서 “삼항 선호”를 요구하는 근본적인 설계 원칙을 제시한다는 점에서 혁신적이다.
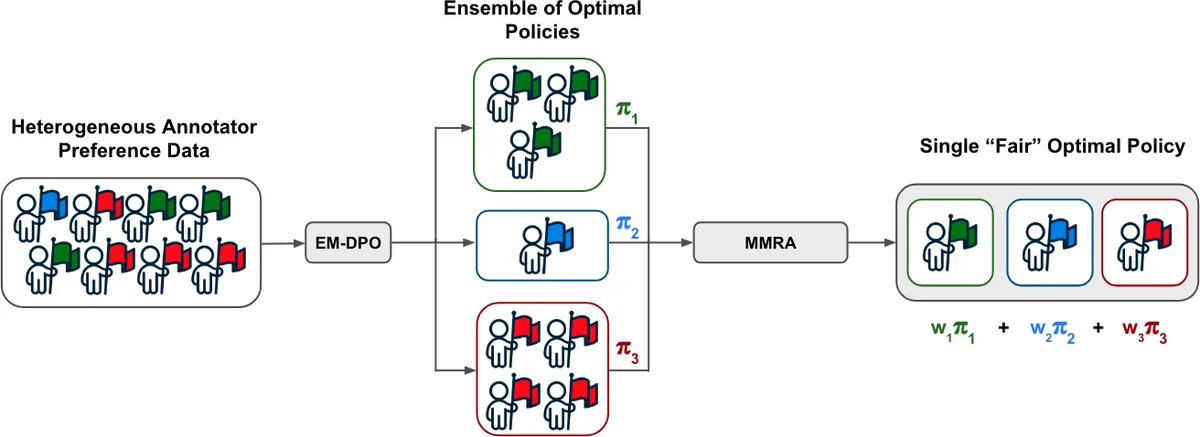
둘째, 기대‑최대화(EM) 프레임워크를 DPO에 직접 적용한 EM‑DPO 알고리즘을 설계한다. 여기서는 각 annotator의 관측된 선호 데이터를 기반으로 숨겨진 라틴트 타입에 대한 posterior γᵢₖ를 계산하고, 이를 가중치로 사용해 각 타입별 정책 πₖ를 별도로 최적화한다. EM‑DPO는 기존의 hard‑clustering 기반 방법보다 부드러운 확률적 클러스터링을 제공하므로, 데이터가 희소하거나 노이즈가 있을 때도 안정적인 그룹 추정이 가능하다. 또한, 정책 파라미터를 타입별로 완전히 독립시키거나 일부 공유하도록 설계할 수 있어, 연산 효율성과 모델 용량 사이의 트레이드오프를 조절한다.
셋째, 다수의 타입‑전용 정책을 하나의 공정한 정책으로 통합하는 Min‑Max Regret Aggregation(MMRA) 방식을 제안한다. 여기서는 각 타입 k에 대해 최적 정책 π*ₖ와 현재 후보 정책 π 사이의 기대 후회 Rₖ(π)를 정의하고, 최악의 후회를 최소화하는 min‑max 목표를 설정한다. 이 목표는 “최소‑최대 후회”라는 공정성 기준을 구현함으로써, 어떤 소수 집단도 과도하게 희생되지 않도록 보장한다. 실제 구현에서는 다중 정책을 선형 결합하거나 multiplicative weight 업데이트를 이용해 근사 최적화를 수행한다.
실험 부분에서는 이진 대비 삼항 선호 데이터셋을 구축하고, EM‑DPO가 라틴트 타입을 정확히 복구하는지 정량적으로 평가한다. 또한, MMRA를 적용한 단일 정책이 각 타입별 별도 정책에 비해 후회가 크게 증가하지 않으며, 전체 사용자 만족도와 안전성 지표에서도 우수함을 입증한다. 전체적으로 이 논문은 “선호 이질성”을 정량적 모델링하고, 이를 실용적인 학습·배포 파이프라인으로 연결한 최초의 연구라 할 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기