대규모 추천을 위한 Mixture of Experts와 Multi Mix Attention 통합 모델
초록
MTmixAtt은 자동 토큰화(Auto Token)와 MTmixAttBlock을 결합한 통합 Mixture‑of‑Experts 구조로, 이질적인 피처를 자동으로 군집화하고 토큰‑레벨 혼합 행렬과 공유·시나리오‑특화 전문가를 통해 전역·지역 패턴을 동시에 학습한다. 실험 결과 TRec 데이터셋 및 메이투안 실서비스에서 기존 Transformer, WuKong, HiFormer, MLP‑Mixer, RankMixer 등을 크게 앞서며, 파라미터 1 B 규모까지 확장해도 성능이 단조롭게 상승한다.
상세 분석
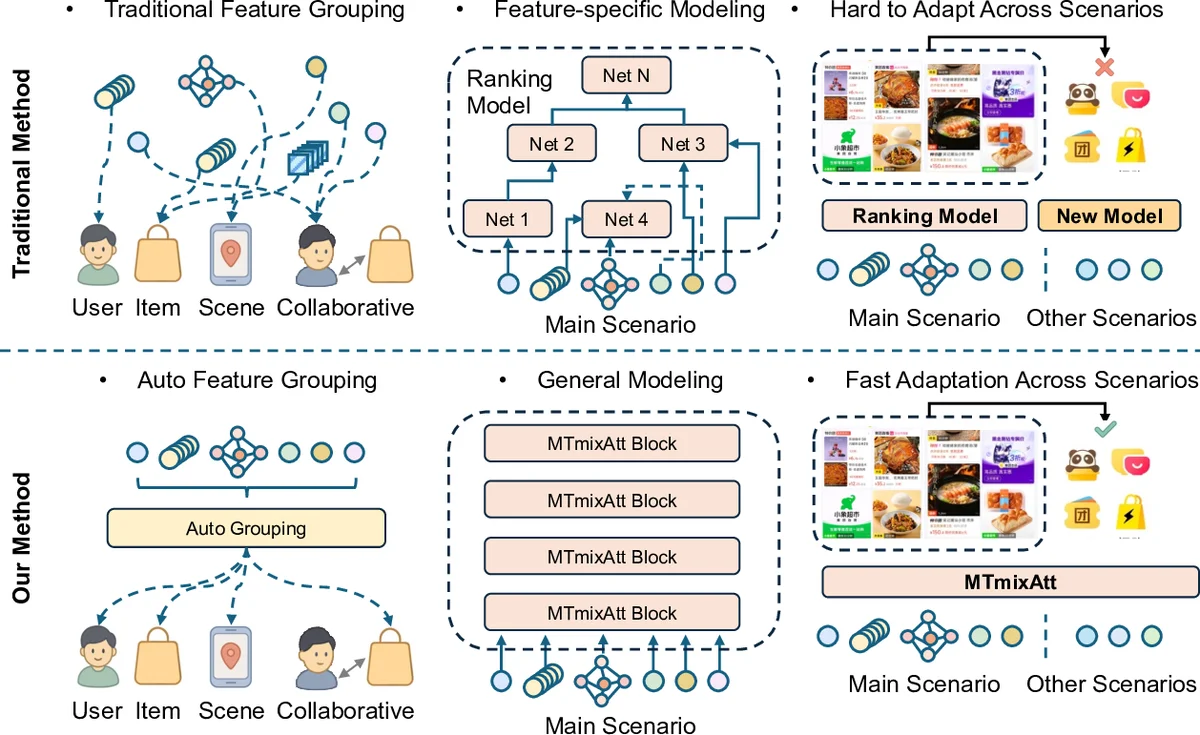
MTmixAtt은 대규모 산업용 추천 시스템이 직면한 세 가지 핵심 문제—수동 피처 그룹화, 아키텍처 이질성, 시나리오 간 일반화 부족—를 하나의 프레임워크로 해결한다. 첫 번째 모듈인 Auto Token은 각 원시 피처를 개별 DNN으로 차원 정렬한 뒤, 학습 가능한 선택 행렬 W 를 통해 top‑k 인덱스를 차별화된 가중치와 함께 선택한다. Softmax‑정규화된 Sₖ(W) 를 사용함으로써 전체 군집화 과정이 미분 가능해져 엔드‑투‑엔드 학습이 가능하다. 이 과정은 전통적인 도메인 전문가에 의한 수동 클러스터링을 대체하고, 데이터 분포 변화에 자동 적응한다.
두 번째 핵심인 MTmixAttBlock은 토큰‑레벨 혼합 행렬과 Mixture‑of‑Experts(MoE)를 결합한다. 입력 피처 매트릭스 X∈ℝ^{d×n_g} 를 전치하여 토큰 차원을 주축으로 만든 뒤, H개의 헤드로 분할한다. 각 헤드마다 W_h∈ℝ^{n_g×n_g} 라는 학습 가능한 혼합 행렬을 적용해 토큰 간 상호작용을 수행하고, 잔차 연결을 통해 안정성을 확보한다. 이 구조는 기존 RankMixer가 고정된 토큰 믹싱을 사용하는 것과 달리, 헤드별로 동적인 토큰 흐름을 학습하도록 설계돼 복잡한 상관관계를 효율적으로 포착한다.
그 후 공유 Dense MoE 레이어가 삽입돼, 토큰 패턴별로 서로 다른 전문가를 할당한다. 기존 MoE가 하나의 거대한 FFN을 여러 전문가에 나누는 반면, MTmixAtt은 각 FFN을 m 개의 서브‑전문가로 세분화해 전문가 수를 인위적으로 늘리면서도 연산량을 고정한다. 이는 전문가 간 전문성을 강화하고, 토큰 간 상호작용을 더욱 다양화한다.
마지막으로 시나리오‑특화 Sparse MoE가 도입돼, 메인 시나리오에서는 공유 Dense 전문가를, 보조 시나리오에서는 라우터가 선택한 희소 전문가 집합을 활성화한다. 라우터는 시나리오 라벨을 입력으로 받아 해당 시나리오에 최적화된 전문가를 동적으로 선택하므로, 동일 모델이 여러 비즈니스 시나리오에 빠르게 적응한다.
학습 측면에서 MTmixAtt은 전체 파라미터를 1 B까지 확장했음에도 GPU 메모리와 연산 효율성을 유지한다. Top‑k 선택과 혼합 행렬 연산은 모두 행렬 연산으로 구현돼, 기존 Transformer 기반 모델 대비 메모리 사용량이 크게 감소한다. 실험 결과, TRec 데이터셋에서 CTR·CTCVR 모두 2~4%p 상승을 기록했으며, 파라미터 수가 증가할수록 성능이 단조롭게 향상되는 스케일링 법칙을 확인했다.
온라인 A/B 테스트에서는 메인 페이지 시나리오에서 결제 PV가 +3.62%, 실제 결제 GTV가 +2.54% 상승하는 실질적인 비즈니스 효과를 입증했다. 이는 자동 피처 군집화와 시나리오‑특화 MoE가 현장 트래픽 변동성을 최소화하면서도 전반적인 매출을 끌어올릴 수 있음을 보여준다.
요약하면, MTmixAtt은 (1) 데이터‑주도 자동 피처 그룹화, (2) 헤드‑별 학습 가능한 토큰 믹싱, (3) 공유·희소 전문가 구조를 통한 전역·지역 패턴 학습, (4) 대규모 파라미터 확장성이라는 네 가지 혁신을 결합해, 산업용 추천 시스템의 핵심 과제를 일관된 하나의 아키텍처로 해결한다.
댓글 및 학술 토론
Loading comments...
의견 남기기