일관성을 활용한 견고한 테스트 시점 LLM 앙상블
초록
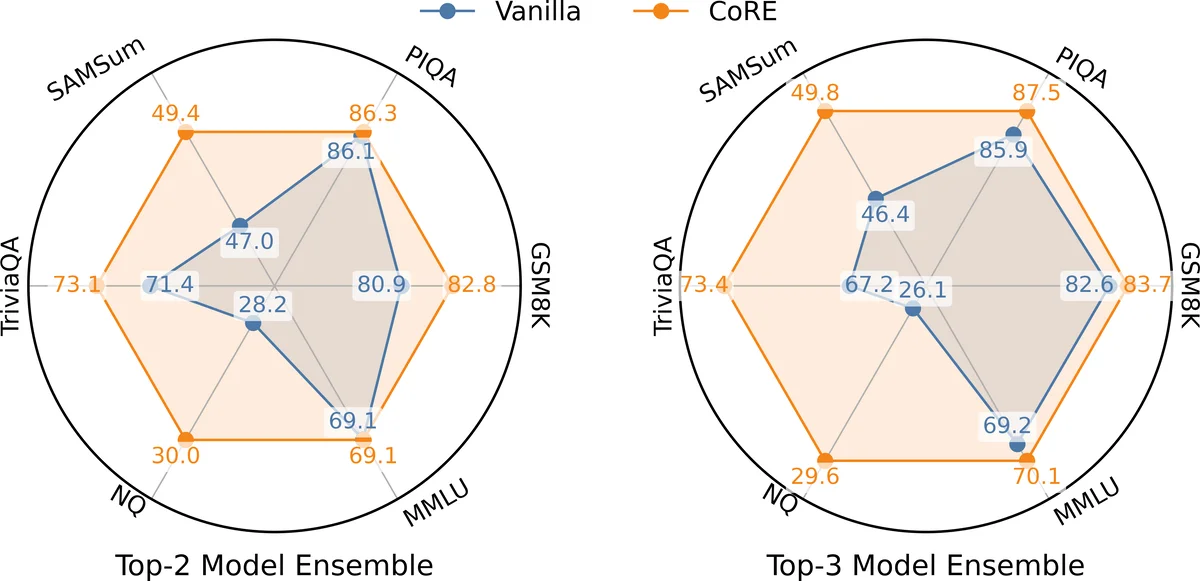
본 논문은 서로 다른 토크나이징 방식과 모델 전문성 차이에서 발생하는 오류 신호에 대비해, 토큰 수준과 모델 수준의 일관성을 동시에 활용하는 플러그인 방식인 CORE를 제안한다. 토큰 일관성은 확률 불일치를 저역통과 필터로 억제하고, 모델 일관성은 자체 신뢰도와 상호 일치도를 결합해 가중치를 재조정한다. 다양한 베이스 모델과 앙상블 전략에 적용했을 때 평균 1.3%~2.8%의 성능 향상과 로버스트성을 입증하였다.
상세 분석
CORE는 LLM 앙상블의 두 핵심 실패 요인을 정량화한다. 첫 번째는 토큰 수준에서 서로 다른 모델이 동일한 의미를 표현하지만 서로 다른 토큰으로 매핑될 때 발생하는 ‘토큰 불일치’이며, 두 번째는 모델 수준에서 특정 질문에 대해 일부 모델이 낮은 자신감(높은 엔트로피)과 다른 모델과의 큰 분산을 보이는 ‘모델 불일치’이다. 논문은 대규모 실험을 통해 토큰 확률 차이 δ_i(v)=| p̃_i(v)−p⁎(v) |가 클수록 해당 토큰이 정렬 오류를 나타내며, 엔트로피가 낮은 모델이 정답을 제공할 확률이 높다는 관찰을 제시한다. 이를 기반으로 토큰 일관성 s_t_i(v)=f(δ_i(v))를 정의하고, RBF, 파워, 시그모이드 등 다양한 커널 함수를 적용해 불일치 토큰을 저역통과 필터링한다. 모델 일관성은 s_m_i=∑_v s_t_i(v) / H(p̃_i) 로, 토큰 일관성의 총합을 모델 자체 엔트로피로 정규화함으로써 ‘높은 상호 일치도 + 낮은 불확실성’ 모델에 더 큰 가중치를 부여한다. 최종 앙상블 확률은 p_ens = s_m_main p_main + Σ_i s_m_i (s_t_i ⊙ p̃_i) 로 계산되며, 여기서 ⊙는 토큰별 가중치 곱을 의미한다. 중요한 점은 CORE가 기존 토큰‑레벨 정렬·정합 방법(MINED, GAC, DeepEn 등) 위에 레이어 형태로 삽입될 수 있어 추가 추론 비용이 거의 들지 않는다는 것이다. 실험에서는 NQ, PIQA, MMLU 등 6개 벤치마크와 5가지 사전학습 모델 조합을 사용했으며, 토큰‑레벨과 모델‑레벨 일관성을 동시에 적용했을 때 Top‑2, Top‑3 앙상블에서 각각 평균 1.3%와 2.8%의 정확도 향상을 기록했다. 특히 토큰 정렬 오류가 빈번한 상황(예: 서로 다른 서브워드 토크나이저)에서 CORE는 잘못된 토큰의 영향력을 크게 감소시켜 전반적인 로버스트성을 크게 개선한다. 이러한 결과는 일관성 기반 가중치 조정이 단순 평균이나 고정 가중치보다 더 신뢰할 수 있는 앙상블을 만든다는 강력한 증거로 해석될 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기