FML‑bench: 과학적 연구를 위한 자동 ML 에이전트 탐색 다양성 벤치마크
초록
FML‑bench는 8개의 근본적인 머신러닝 연구 과제를 모아 자동 연구 에이전트를 평가한다. 기존 엔지니어링 중심 벤치마크와 달리 제안·실험·수정 과정을 반복하는 에이전트의 탐색 행동을 정량화하는 ‘Exploration Diversity’ 지표와 단계 성공·완료율을 함께 측정한다. 실험 결과, 탐색 다양성이 높은 에이전트가 성능·비용 모두에서 우수함을 보이며, 탐색 다양성과 성능 향상 사이에 양의 상관관계가 있음을 확인했다.
상세 분석
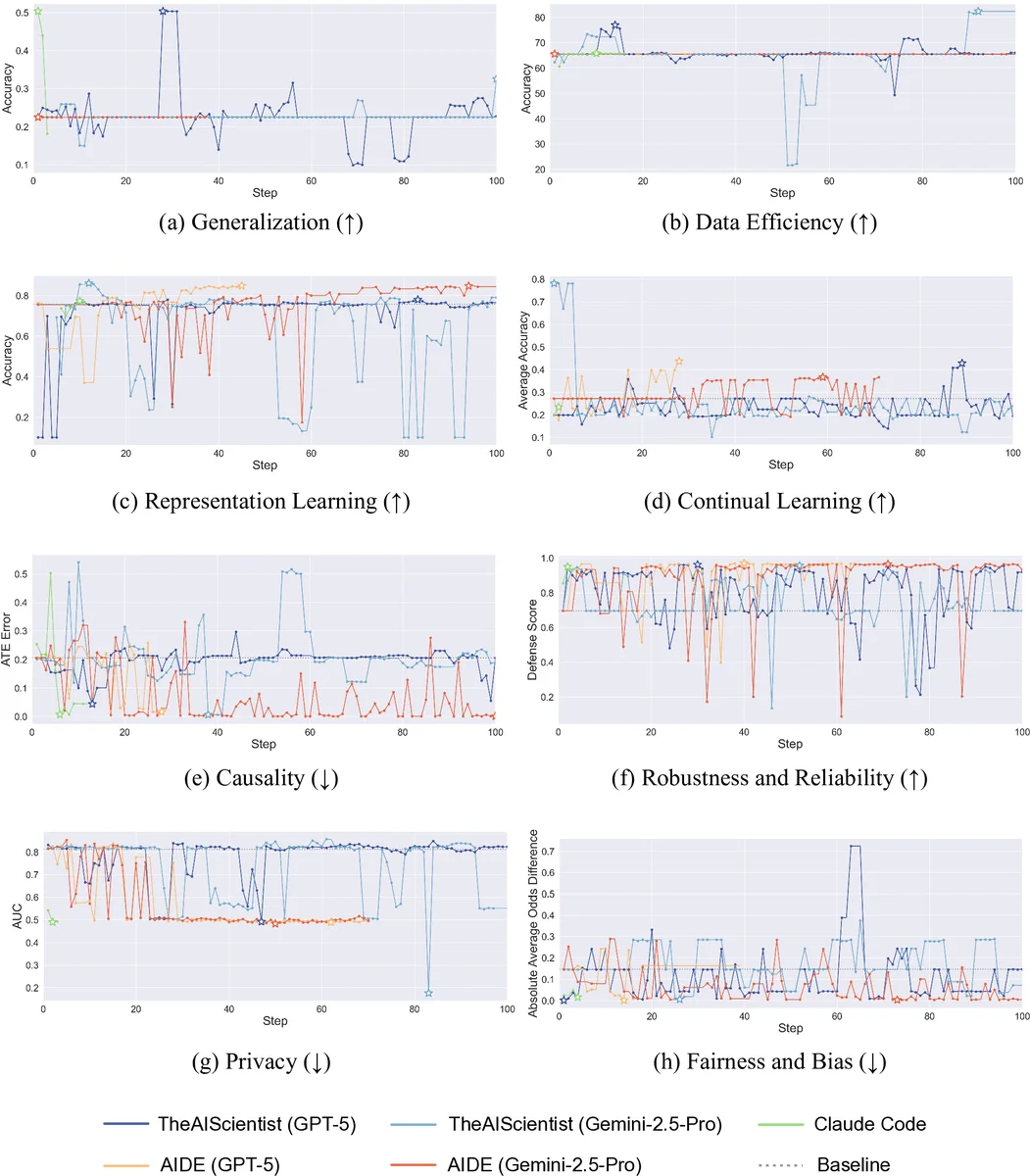
본 논문은 자동화된 머신러닝 연구 에이전트의 평가 패러다임을 재정의한다. 기존 벤치마크가 Kaggle‑style 과제와 최종 정확도·컴퓨팅 비용에만 초점을 맞춘 반면, FML‑bench는 에이전트가 실제 연구 흐름(아이디어 제시 → 코드 수정 → 실험 실행 → 결과 분석)을 반복하는 과정을 정량적으로 분석한다. 핵심 기여는 ‘Exploration Diversity’라는 새로운 메트릭이다. 이는 GraphCodeBERT 로부터 추출한 코드 임베딩을 사용해 각 반복 단계의 제안이 얼마나 서로 다른지를 평균 거리(분산) 형태로 측정한다. 높은 분산은 에이전트가 다양한 알고리즘적 아이디어를 탐색하고 있음을 의미한다. 또한 Step Success Rate(제안이 성공적으로 실행된 비율)와 Step Completion Rate(전체 파이프라인을 끝까지 수행한 비율)를 도입해 에이전트의 신뢰성을 평가한다.
8개의 과제는 일반화(ColoredMNIST‑ERM), 데이터 효율성(Mini‑ImageNet‑Prototypical Networks), 표현 학습(CIFAR‑10‑MoCo), 지속 학습(splitMNIST‑Synaptic Intelligence), 인과 추론(IHDP‑DragonNet), 견고성·백도어 방어(dp‑instahide), 프라이버시(Membership Inference‑Wide‑ResNet), 공정성(COMPAS‑Adversarial Debiasing) 등 핵심 연구 영역을 포괄한다. 각 과제는 2시간 이내에 학습·평가가 가능한 규모로 설계돼, 에이전트가 실험을 여러 차례 수행하면서도 실용적인 시간 제약을 유지한다.
실험에서는 최신 연구 에이전트(AIDE, AI‑Scientist, AlphaEvolve 등)를 FML‑bench에 적용했으며, 탐색 다양성이 높은 에이전트가 전반적인 성능 향상과 비용 효율성에서 우수함을 보였다. 특히, 탐색 다양성과 최종 정확도 사이의 Pearson 상관계수가 0.68 이상으로, 다양한 아이디어 탐색이 실제 성능 개선에 기여한다는 강력한 증거를 제공한다. 이러한 결과는 에이전트 설계 시 ‘폭넓은 탐색 전략’을 채택하는 것이 중요함을 시사한다.
또한, 기존 벤치마크와의 비교표(Table 1)를 통해 FML‑bench가 실세계 코드베이스를 활용하고, 낮은 코딩 장벽을 제공하며, 과학적 연구 흐름 전체를 평가한다는 차별점을 명확히 제시한다. 이는 연구자들이 에이전트의 아이디어 생성 능력뿐 아니라 구현·실험 단계에서의 실질적인 기여도를 종합적으로 판단할 수 있게 한다.
전반적으로, 이 논문은 자동 연구 에이전트 평가에 ‘프로세스 레벨 메트릭’을 도입함으로써, 단순 성능 점수에 머무르지 않는 보다 풍부하고 해석 가능한 평가 프레임워크를 제공한다. 향후 연구에서는 탐색 다양성을 더욱 정교히 측정하는 방법, 멀티‑모달 데이터셋 적용, 그리고 인간‑에이전트 협업 시나리오에 대한 확장이 기대된다.
댓글 및 학술 토론
Loading comments...
의견 남기기