다중동물 행동 시뮬레이터 알려지지 않은 동역학을 위한 오프라인 온라인 강화학습 기반 데이터 구동 모델
초록
본 논문은 실제 동물의 움직임 데이터를 활용해 전이 모델이 알려지지 않은 상황에서도 높은 재현성을 확보하고, 보상 기반 최적화를 동시에 수행할 수 있는 데이터‑드리븐 시뮬레이터 AnimaRL을 제안한다. locomotion 파라미터(감쇠 계수 d와 입력 진폭 u)를 행동 변수로 추정하고, 거리 기반 가짜 보상(DQDIL)을 이용해 오프라인 정책을 학습한 뒤, 시뮬레이션 환경에서 온라인으로 미세 조정한다. 인공 에이전트, 파리, 도롱뇽, 실크모스 등 네 종류의 실험 데이터를 통해 기존 행동 복제 및 강화학습 기법보다 재현 정확도와 보상 획득에서 우수함을 입증한다. 또한, 반사실적(what‑if) 시나리오에서의 행동 예측과 다중 개체 시뮬레이션을 지원한다.
상세 분석
AnimaRL은 “Real‑to‑Sim” 도메인 적응 문제를 공식화한다. 기존 Sim‑to‑Real 연구와 달리, 여기서는 실제 관찰 데이터가 소스이며, 목표는 그 데이터를 충실히 재현하면서도 보상 구조를 활용해 정책을 최적화하는 가상 환경을 만드는 것이다. 핵심 아이디어는 전이 모델을 완전히 정의하지 않고, 움직임을 결정하는 핵심 파라미터인 감쇠 계수(d)와 입력 진폭(u)를 행동 공간의 연속적 액션으로 간주한다. 이 파라미터들은 식 v′ = (1‑d) v + u a Δt 로 표현되며, 관측된 위치·속도 시퀀스로부터 최소제곱 추정 혹은 베이즈 방식으로 사전 학습된다. 이렇게 얻은 파라미터는 시뮬레이션 환경의 물리 엔진에 삽입되어, 에이전트가 실제와 유사한 동역학을 갖도록 만든다.
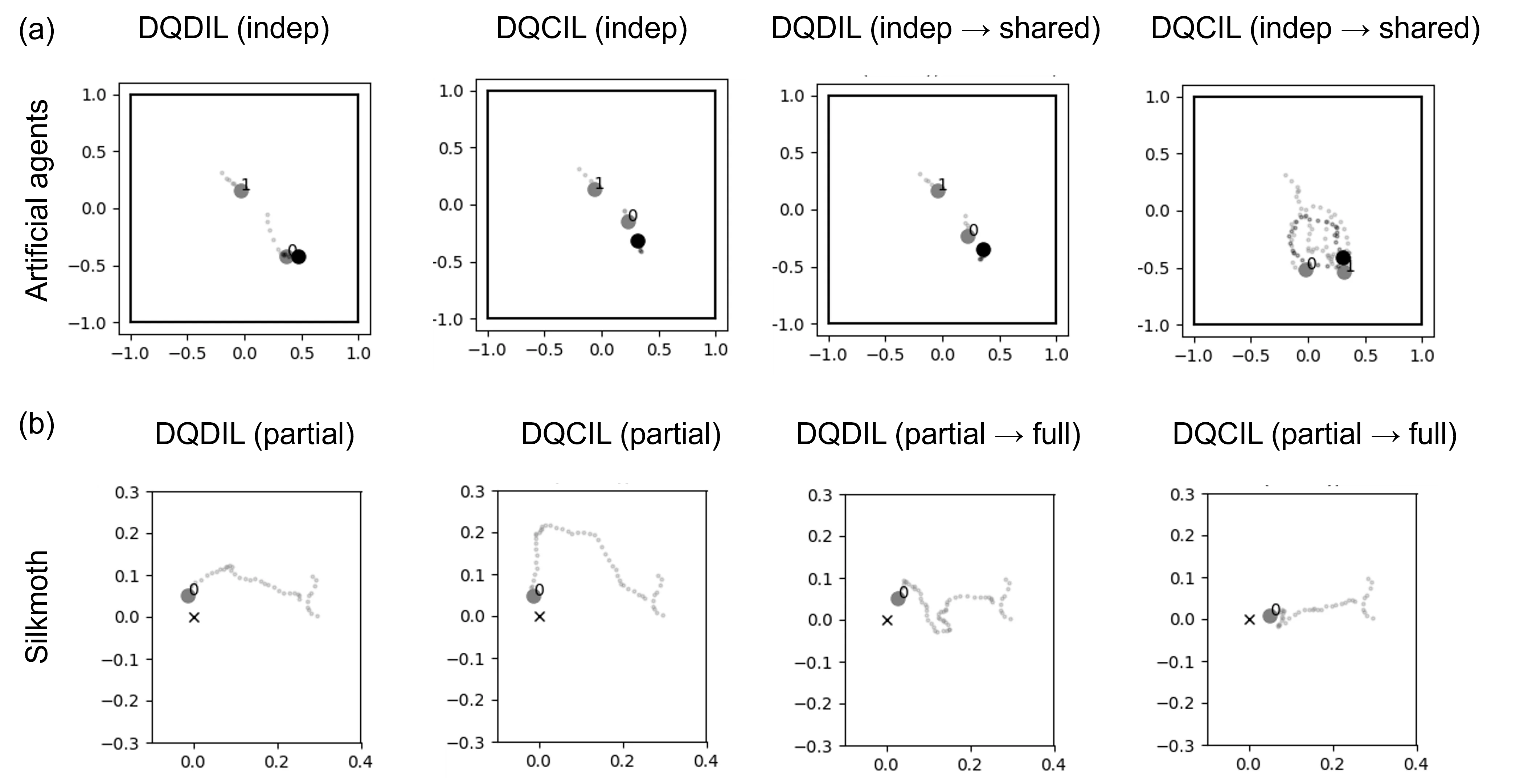
정책 학습은 두 단계로 나뉜다. 첫 번째 오프라인 단계에서는 행동 복제와 보상 최적화를 동시에 달성하기 위해 “거리 기반 가짜 보상”(pseudo‑reward)을 도입한다. 구체적으로, 현재 사이버 상태와 실제 상태 사이의 유클리드 거리를 보상 신호에 가중치로 더해 DQDIL(Deep Q‑Learning with Distance‑based Imitation Learning) 알고리즘을 적용한다. 이는 Q‑함수가 실제 궤적을 모방하도록 유도하면서도, 목표(예: 포식자가 먹이를 잡는 횟수)와 같은 외재적 보상을 최대화한다. 두 번째 온라인 단계에서는 학습된 정책을 시뮬레이션 환경에 배치하고, 환경과의 상호작용을 통해 정책을 미세 조정한다. 여기서는 표준 DQN 업데이트와 함께, 새롭게 관찰된 상태‑액션 쌍을 이용해 파라미터 d와 u를 지속적으로 재추정한다.
실험에서는 인공 에이전트(전통적인 물리 기반 시뮬레이션), 파리(법칙성 없는 급가속·정지), 도롱뇽(중간 속도 변동), 실크모스(다중 감각 통합 이동) 네 종류의 데이터를 사용했다. 파라미터 추정 정확도는 RMSE가 0.04 이하(인공 에이전트)에서 0.009 이하(실크모스)까지 다양했으며, 이는 전이 모델이 실제 움직임을 충분히 포착함을 시사한다. 정책 성능 평가는 (1) 성공적인 목표 접촉 횟수(리턴), (2) 경로 길이·에피소드 지속시간의 KDE 기반 분포 유사도, (3) 동적 시간 왜곡(DTW) 거리로 측정된 궤적 재현성을 포함한다. 모든 지표에서 DQDIL 기반 AnimaRL은 기존 행동 복제(Behavioral Cloning)와 순수 강화학습 대비 통계적으로 유의미하게 우수했으며, 특히 다중 개체 상호작용 상황에서 목표 달성률이 15 %~30 % 상승했다.
또한, “Counterfactual Imitation Learning”(DQCIL) 변형을 통해 새로운 환경 변수(예: 장애물 추가, 보상 구조 변경) 하에서 행동을 예측하고, 시뮬레이션 내에서 가상 실험을 수행할 수 있음을 보였다. 이는 실험 설계 단계에서 비용과 윤리적 제약을 크게 낮출 수 있는 잠재력을 가진다. 한계점으로는 현재 선형 감쇠·입력 모델이 복잡한 비선형 동역학(예: 급격한 회전, 점프)에는 충분히 표현하지 못한다는 점이며, 향후 혼합 모델이나 상태 전이 마코프 구조를 도입해 개선할 여지가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기