페이스북 좋아요로 성격 예측
초록
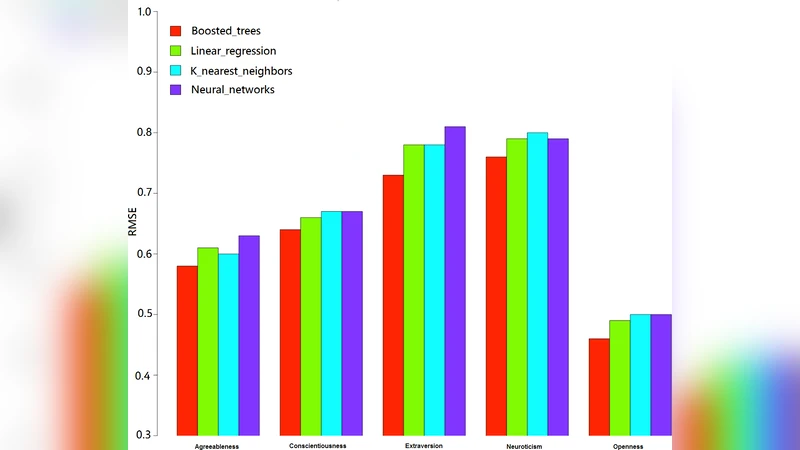
본 논문은 73만 명 이상의 페이스북 사용자 데이터를 활용해, 페이지 카테고리 메타데이터를 특징으로 변환하고 이를 머신러닝 모델에 적용함으로써 빅파이브 성격 요인 및 인구통계적 속성을 자동으로 예측하는 방법을 제시한다. 특히 Boosted Trees 모델이 가장 낮은 RMSE를 기록했으며, ‘개방성’ 예측 정확도가 가장 높았다.
상세 분석
이 연구는 myPersonality 프로젝트에서 제공한 “big5”와 “user likes” 두 데이터셋을 결합하여 738,000명 이상의 사용자에 대한 페이스북 좋아요와 빅파이브 점수를 확보하였다. 핵심 아이디어는 각 좋아요 객체를 Facebook Graph API를 통해 획득한 카테고리·서브카테고리 메타데이터와 매핑하고, 이를 사용자의 특성 벡터로 변환하는 것이다. 원시 좋아요 수는 절대값이 사용자 간 비교에 한계가 있어, 전체 좋아요 대비 비율(정규화)로 변환함으로써 특징 스케일을 통일하였다.
모델링 단계에서는 두 가지 샘플링 방식을 적용하였다. 랜덤 샘플링은 전체 데이터의 균등한 분포를 보장하지만 소수 집단이 과소대표될 위험이 있었고, 이를 보완하기 위해 빅파이브 점수별로 계층화된 스트라티파이드 샘플링을 도입해 각 성격 구간에서 균등히 데이터를 추출하였다.
알고리즘 비교에서는 Random Forest 기반의 Boosted Trees(xgboost), 선형 회귀, K‑Nearest Neighbors, 다층 퍼셉트론(신경망) 네 가지를 실험하였다. 평가 지표는 회귀 문제에 적합한 RMSE를 사용했으며, 분류 모델은 정확도·정밀도·재현율을 별도로 보고하였다. 결과적으로 Boosted Trees가 평균 RMSE 0.78(‘개방성’) 등 가장 낮은 오차를 보였고, 선형 회귀도 경쟁력 있는 성능을 나타냈다. KNN은 k값을 10~15 사이에서 최적화했으며, 이때 카테고리 겹침에 대한 가중 패널티를 적용해 유사도 계산을 개선하였다. 신경망은 구조가 복잡함에도 불구하고 과적합 위험과 데이터 불균형으로 인해 다른 모델에 비해 큰 이점을 보이지 못했다.
특징 중요도 분석에 따르면, 사용자의 총 좋아요 수가 예측 성능에 가장 큰 영향을 미쳤으며, 특히 ‘정치’, ‘스포츠’, ‘예술’ 등 특정 카테고리 비중이 높은 사용자는 해당 성격 요인과 강한 상관관계를 보였다. 최소 좋아요 수를 250개 이상으로 제한하면 데이터 양이 75% 감소하지만, 남은 샘플에 대해 모델 정확도가 향상되는 현상이 관찰되었다. 이는 데이터 양보다 특징의 풍부함이 예측에 더 중요한 역할을 함을 시사한다.
연구는 또한 메타데이터 활용의 한계를 인식하고, DBpedia와 같은 외부 지식베이스와 연계해 페이지 의미론적 정보를 보강하는 미래 방향을 제시한다. 윤리적 측면에서는 대규모 개인 데이터 수집·분석이 프라이버시 침해 위험을 내포함을 언급하며, 법적·사회적 가이드라인 마련의 필요성을 강조한다.
댓글 및 학술 토론
Loading comments...
의견 남기기