가우시안 크로스: 가우시안 스플래팅 기반 교차모달 자기지도 3D 표현 학습
초록
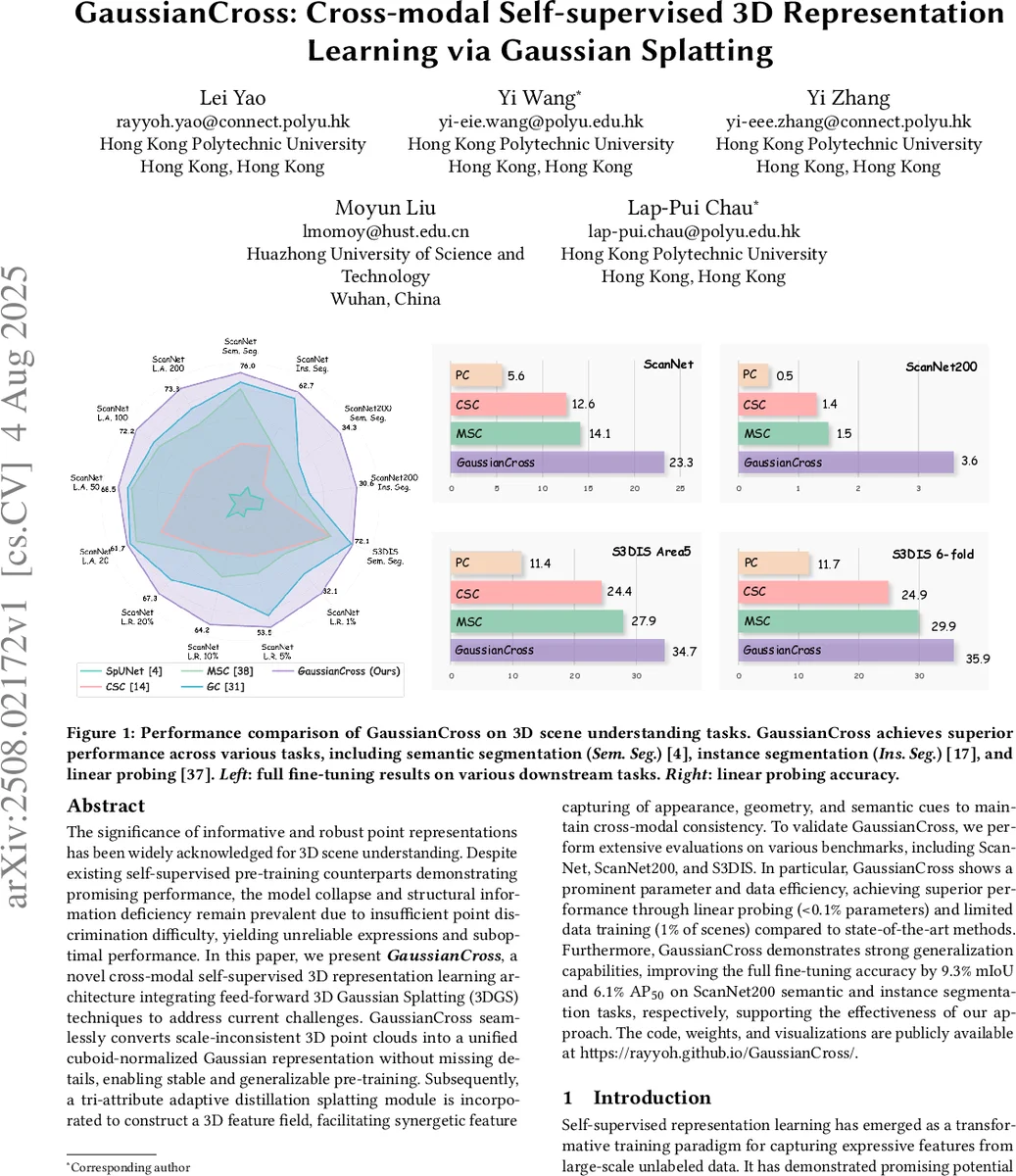
GaussianCross는 3D 포인트 클라우드를 정규화된 큐보이드 가우시안 형태로 변환하고, 외관·기하·시맨틱 3가지 속성을 동시에 학습하는 적응형 디스틸레이션 스플래팅 모듈을 도입해 2D 비전 파운데이션 모델과의 교차모달 지식을 전달한다. 이를 통해 모델 붕괴와 구조 정보 손실을 완화하고, 1 % 데이터와 <0.1 % 파라미터만으로도 ScanNet·ScanNet200·S3DIS에서 뛰어난 성능을 달성한다.
상세 분석
본 논문은 3D 장면 이해에 필수적인 “점(point)” 표현의 한계를 극복하기 위해 두 가지 핵심 기법을 제시한다. 첫 번째는 Cuboid‑Normalized Gaussian Initialization이다. 기존 3D Gaussian Splatting(3DGS)은 씬 별 최적화에 머물러 스케일이 다른 장면에 일반화하기 어려웠지만, 저자들은 원시 포인트 클라우드를 단위 큐브(1×1×1)로 정규화하고, 이를 균일한 voxel grid에 매핑함으로써 모든 씬을 동일한 좌표계에 배치한다. 각 voxel의 중심을 가우시안의 초기 평균(μ)으로 사용하고, voxel에 집계된 특징을 가우시안의 색·불투명도·스케일 파라미터의 초기값으로 활용한다. 이렇게 하면 스케일 변동에 강인하면서도 세밀한 디테일을 보존하는 “구조화된 가우시안 프리미티브”를 얻을 수 있다.
두 번째는 Tri‑attribute Adaptive Distillation Splatting 모듈이다. 여기서는 가우시안의 위치 보정(offset), 불투명도 기반 프루닝(opacity‑driven pruning), 그리고 3D feature field를 동시에 예측한다. 위치 보정은 MLP G_q를 통해 학습된 offset을 평균에 더해 미세한 정렬을 가능하게 하고, 불투명도는 가우시안의 존재 여부를 동적으로 조절해 메모리와 연산을 효율화한다. 가장 혁신적인 부분은 3D feature field(F_d)를 2D 비전 파운데이션 모델(VFM)의 이미지 임베딩과 정렬시키는 cross‑modal knowledge distillation이다. 렌더링된 가우시안 이미지와 VFM이 추출한 고차원 특징을 프로젝션 헤드로 매핑해 L2 손실 및 대비 학습을 수행함으로써, 2D 이미지에 내재된 풍부한 의미 정보를 3D 포인트 클라우드에 주입한다.
학습 목표는 view reconstruction이다. 무작위로 선택된 카메라 뷰에 대해 가우시안 프리미티브를 렌더링하고, 실제 RGB‑D 이미지와 색·깊이·시맨틱 맵을 비교한다. 색 재구성 손실, 깊이 손실, 그리고 VFM 특징 정렬 손실을 가중합한 복합 손실(L_total)로 최적화한다. 이 과정은 2D 라벨이 전혀 필요 없으며, 뷰 간 다양성을 자연스럽게 제공해 기존 대비‑학습 기반 방법에서 흔히 발생하던 model collapse를 효과적으로 억제한다.
실험에서는 ScanNet, ScanNet200, S3DIS 등 세 가지 대표적인 실내 씬 데이터셋을 사용했다. Linear probing(전체 파라미터의 <0.1 %만 학습)에서 GaussianCross는 기존 최첨단 방법들을 크게 앞서며, 특히 ScanNet200에서 mIoU +9.3 %와 AP₅₀ +6.1 %를 기록했다. 또한 데이터 효율성 측면에서 전체 씬의 1 %만 사용해도 경쟁 모델 대비 동일하거나 우수한 성능을 보였다. 파라미터 수는 기존 3D 백본 대비 30 % 정도 감소했으며, 추론 속도는 실시간 수준(≈30 fps)으로 유지된다.
이러한 결과는 가우시안 스플래팅이 단순히 고품질 렌더링을 위한 도구를 넘어, 교차모달 자기지도 학습의 강력한 프레임워크가 될 수 있음을 입증한다. 특히, 정규화된 큐보이드 초기화와 삼속성 적응 디스틸레이션이 결합되어 스케일 불변성, 구조 보존, 의미 전달을 동시에 달성한다는 점이 혁신적이다. 향후 연구에서는 더 복잡한 실외 씬, 동적 객체, 그리고 텍스트‑이미지‑3D 멀티모달 정합을 확장하는 방향이 기대된다.
댓글 및 학술 토론
Loading comments...
의견 남기기