GCC: 효율적인 3D 가우시안 스플래팅을 위한 교차‑단계 조건 처리와 가우시안‑단위 렌더링 아키텍처
초록
본 논문은 3D Gaussian Splatting(3DGS) 추론 가속기에 존재하는 전처리·렌더링 분리와 타일 기반 중복 로딩 문제를 해결하기 위해, 전처리와 렌더링을 동적으로 교차 수행하는 교차‑단계 조건 처리와 가우시안을 깊이 순서대로 한 번만 로드하는 가우시안‑단위 렌더링을 도입한 GCC 아키텍처를 제안한다. 알파 기반 경계 식별 기법으로 사용되는 가우시안 영역을 압축하고, 28 nm 공정 구현을 통해 기존 최첨단 가속기 GSCore 대비 평균 5.24× 속도와 3.35× 에너지 효율 향상을 입증한다.
상세 분석
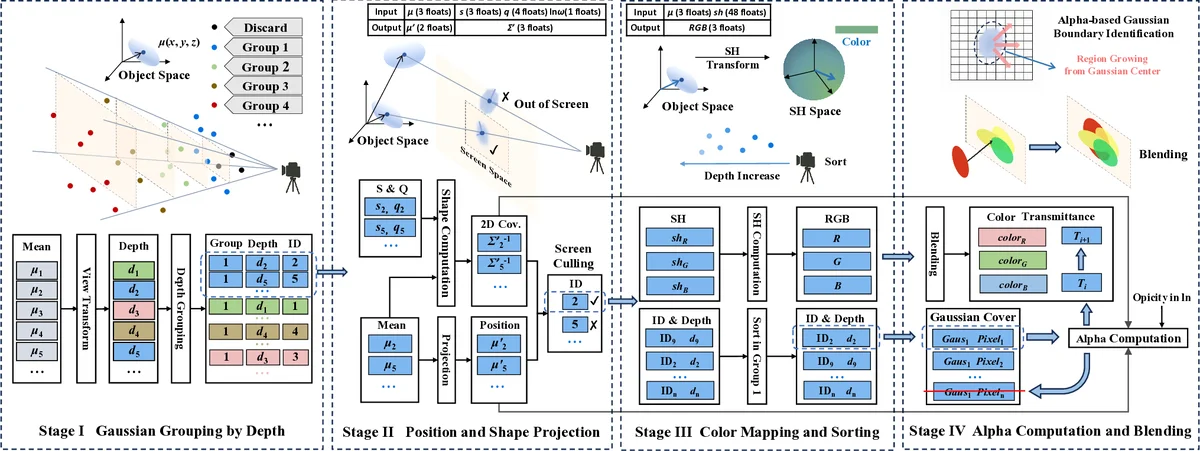
GCC는 3DGS 파이프라인의 두 가지 근본적인 비효율성을 정밀히 분석하고, 이를 구조적으로 제거한다. 첫 번째 비효율은 전처리 단계에서 모든 가우시안을 일괄 변환하고, 실제 렌더링에 사용되지 않는 가우시안이 60 % 이상 존재한다는 점이다. 기존 가속기(GSCore)는 전처리 비용이 전체 실행 시간의 40 %를 차지하면서도, 대부분의 결과가 α‑블렌딩 조기 종료에 의해 폐기된다. GCC는 교차‑단계 조건 처리를 통해 전처리와 렌더링을 런타임에 교차 실행한다. 구체적으로, 가우시안이 프러스텀에 포함되는지와 α‑값이 임계치 이상인지 즉시 판단하여, 필요 없는 가우시안은 전처리 자체를 건너뛴다. 이는 메모리 대역폭과 연산량을 크게 감소시킨다.
두 번째 비효율은 타일 기반 렌더링에서 동일 가우시안이 여러 타일에 겹쳐 있을 경우 매 타일마다 재로드되는 현상이다. 실험에 따르면 평균 3.2 ~ 6.5배까지 중복 로드가 발생한다. GCC는 가우시안‑단위 렌더링을 도입해, 가우시안을 깊이 순서대로 완전 처리하고, 해당 가우시안이 차지하는 모든 픽셀을 한 번에 계산한다. 이렇게 하면 가우시안 파라미터는 메모리에서 한 번만 읽히며, 타일 경계 관리 비용도 사라진다.
또한, GCC는 알파 기반 경계 식별 기법을 제안한다. 기존 방법은 고정된 타일 격자와 AABB를 사용해 과도하게 큰 영역을 할당한다. GCC는 각 가우시안의 α‑값을 이용해 실제 기여도가 있는 픽셀 영역을 동적으로 추정하고, 이를 기반으로 최소한의 바운딩을 생성한다. 이 과정은 α‑블렌딩 조기 종료와 결합돼 불필요한 픽셀 연산을 크게 줄인다.
하드웨어 측면에서는 28 nm CMOS 공정으로 구현된 GCC가 전처리·렌더링 연산 유닛, 깊이 정렬 전용 라디스 소트, 고대역폭 온칩 SRAM을 효율적으로 배치한다. 전처리와 렌더링을 교차 수행하도록 파이프라인 스케줄러를 설계했으며, 가우시안‑단위 접근을 지원하기 위해 가우시안 인덱스 테이블을 온칩에 유지한다. 결과적으로, GSCore 대비 평균 5.24배의 스루풋 향상(최대 667 FPS, Lego 데이터셋)과 3.35배의 면적 정규화 에너지 효율을 달성한다.
이러한 설계는 3DGS가 요구하는 고밀도 행렬 연산, SH 색상 계산, α‑블렌딩을 데이터 흐름 수준에서 최소화하고, 메모리 접근 패턴을 최적화함으로써 모바일 및 AR 헤드셋 같은 제한된 전력·연산 환경에서도 실시간 고품질 뷰 합성을 가능하게 만든다.
댓글 및 학술 토론
Loading comments...
의견 남기기