듣는 법을 배우다: 소리 이벤트 탐지를 위한 시공간‑주파수 주의 모델
본 논문은 소리 이벤트 탐지(Sound Event Detection)에서 언제, 어디를 집중해야 하는지를 학습하는 두 단계의 주의 메커니즘을 제안한다. 시간 축의 중요 구간을 강조하는 **시간 주의 모델**과 주파수 축의 핵심 대역을 강조하는 **주파수 주의 모델**을 CRNN 구조에 결합해 DCASE 2017 Task 2(희귀 소리 이벤트)에서 경쟁력 있는 성능을 달성하였다.
저자: Yu-Han Shen, Ke-Xin He, Wei-Qiang Zhang
본 논문은 소리 이벤트 탐지(Sound Event Detection, SED) 분야에서 “언제 듣고, 어디서 듣는가”를 학습하는 새로운 주의 메커니즘을 제안한다. DCASE 2017 Challenge의 Task 2(희귀 소리 이벤트)에서 제공된 데이터셋을 활용해, 아기 울음, 유리 파손, 총성 등 세 종류의 희귀 이벤트를 탐지한다. 기존 최고 성능 모델들은 주로 Conv‑RNN(CRNN) 구조를 사용했으며, 일부는 앙상블 기법을 통해 성능을 끌어올렸다. 저자는 이러한 흐름을 이어가면서도, 단일 모델만으로도 경쟁력 있는 결과를 얻고자 두 단계의 주의 모델을 설계하였다.
**1) 시스템 개요**
전체 구조는 CNN‑RNN‑FC(fully‑connected) 형태의 CRNN에 시간 주의와 주파수 주의 두 모듈을 추가한 형태다. 입력은 44.1 kHz 샘플링된 오디오를 40 ms 프레임(20 ms 홉)으로 나눈 뒤, 128개의 멜‑필터를 적용해 로그 필터뱅크(Fbank) 특성을 추출한다. 추출된 Fbank은 평균 0, 표준편차 1로 정규화된다.
**2) 시간 주의 모델**
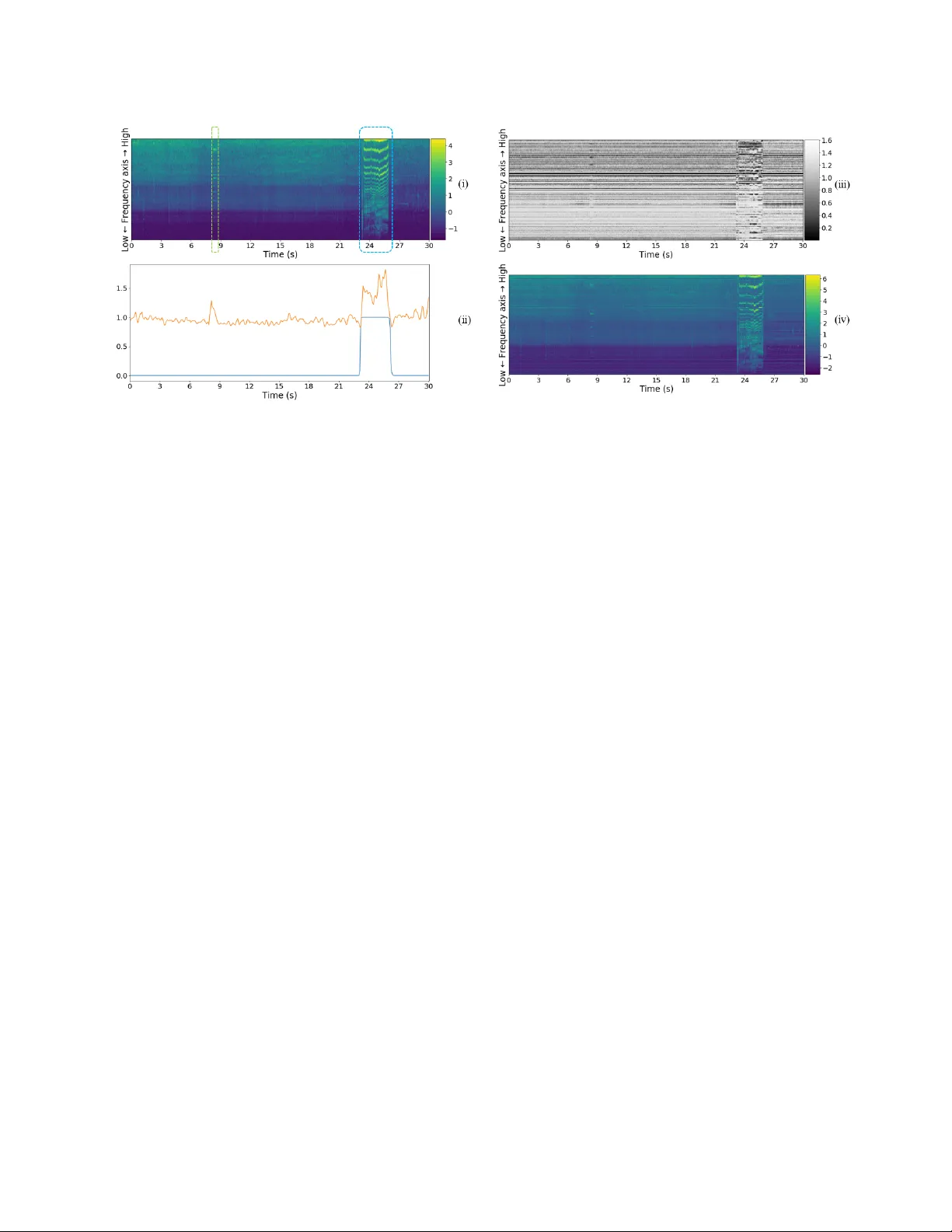
CNN 출력(시간 × 주파수 × 채널) 뒤에 전결합 레이어(Nt = 32)를 두고, 시그모이드·ReLU·소프트맥스 중 ReLU를 활성화 함수로 사용한다. 전결합 결과는 주파수 축에 대해 전역 맥스 풀링을 수행해 각 시간 구간에 대한 스칼라 가중치 \(\hat a_t\)를 만든다. 이 가중치는 전체 구간 수 T로 정규화해 \(a_t\)를 얻고, Bi‑GRU 출력 \(h_t\)와 요소별 곱해져 최종 확률 \(y_t\)를 산출한다. 이 과정은 “positive segment”와 “hard negative segment” 모두에 높은 가중치를 부여하도록 설계돼, 배경음 중에서도 이벤트와 혼동될 가능성이 큰 구간을 강조한다.
**3) 주파수 주의 모델**
입력 Fbank 자체에 전결합 레이어(Nf = 128)와 활성화 함수를 적용해 각 멜 필터에 대한 가중치 \(\hat M_{n,t}\)를 만든다. 주파수 축으로 정규화해 \(M_{n,t}\)를 얻고, 원본 Fbank \(F_t\)와 요소별 곱해 \(\tilde F_t = M_t \otimes F_t\)를 만든다. 이렇게 가중된 스펙트럼은 CNN에 전달되며, 저주파 대역에 높은 가중치를 부여해 고주파 노이즈를 억제한다.
**4) CRNN 본체**
CNN은 4개의 컨볼루션 레이어(배치 정규화, ReLU, 드롭아웃, 잔차 연결 포함)와 시간·주파수 양쪽에 맥스 풀링을 적용한다. 풀링 후 특징 맵을 주파수 축으로 스택해 Bi‑GRU(32 유닛)로 전달한다. Bi‑GRU는 순방향·역방향 출력을 합산해 시계열 정보를 풍부하게 만든다. 마지막 Fully‑Connected 레이어와 시그모이드 활성화가 80 ms 해상도의 이진 확률을 출력한다.
**5) 학습 및 손실**
Adam 옵티마이저(learning rate = 0.001)를 사용하고, 데이터 불균형을 고려해 양성 샘플에 가중치 w = 10을 부여한 가중 교차 엔트로피 손실을 최소화한다. 사전 학습 단계에서 베이스라인 CRNN을 10 epoch 학습한 뒤, 그 가중치를 초기값으로 사용해 전체 모델을 200 epoch까지 학습한다. 배치 크기는 64이며, 정규화된 가중치는 각각 ReLU(시간)와 시그모이드(주파수)로 설정한다.
**6) 실험 및 결과**
3000개의 합성 믹스를 각 클래스별로 생성해 훈련에 사용했으며, 개발 세트와 평가 세트 모두에서 성능을 측정했다. 평가 지표는 이벤트 기반 오류율(ER)과 F‑score이며, 500 ms 콜라를 적용한다. 결과는 다음과 같다.
- 베이스라인 CRNN: 평균 ER = 0.14, F‑score = 88.3%
- 시간 주의 모델(CRNN+TA): 평균 ER = 0.16, F‑score = 91.8%
- 제안 모델(시간 + 주파수 주의): 평균 ER = 0.13, F‑score = 93.4%
특히 제안 모델은 단일 모델임에도 불구하고, 앙상블을 활용한 상위 2팀(1d‑CRNN, CRNN)과 비슷하거나 더 나은 성능을 보였다. 시각화 실험에서는 시간 주의가 이벤트 구간과 혼동되는 ‘beep’ 소리에 높은 가중치를 부여하고, 주파수 주의가 저주파 대역에 집중해 고주파 노이즈를 억제하는 모습을 확인했다.
**7) 결론 및 향후 연구**
시간과 주파수 두 차원에서의 주의 메커니즘을 결합함으로써, SED 시스템이 “언제”와 “어디서” 중요한 정보를 추출해야 하는지를 스스로 학습하도록 만들었다. 이 접근은 현재 DCASE 2017 Task 2에서 최고 수준의 성능을 달성했으며, 스피커 검증, 음성 인식, 오디오 태깅 등 다른 오디오 처리 분야에도 확장 가능성을 보인다. 향후 연구에서는 멀티‑헤드 주의, 어텐션 기반 포스트 프로세싱, 그리고 실시간 적용을 위한 경량화 방안을 탐색할 예정이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기