RISC‑V 확장으로 FPGA에서 희소 DNN 가속을 구현하는 하드웨어·소프트웨어 공동 설계
초록
본 논문은 FPGA 기반 RISC‑V 코어에 맞춤형 명령어와 전용 연산 유닛을 추가해, 반구조적(2:4 등) 및 비구조적 희소성을 동시에 활용하는 DNN 가속기를 설계한다. 비트‑레벨 가중치 인코딩과 가변 사이클 MAC을 통해 각각 최대 4배·3배, 그리고 두 기법을 결합해 최대 5배의 속도 향상을 달성하면서도 FPGA 자원 오버헤드를 최소화한다.
상세 분석
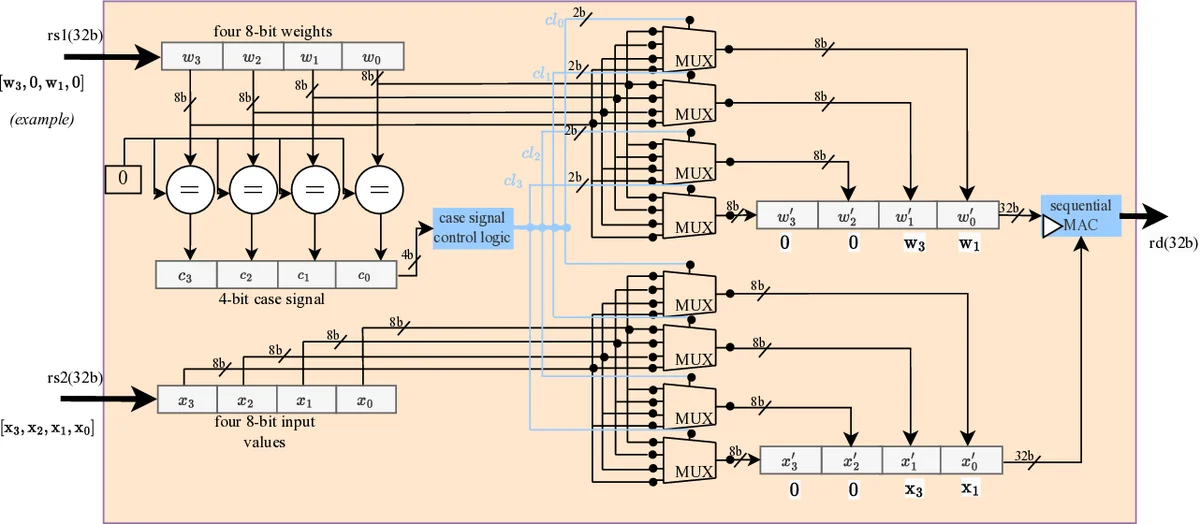
이 연구는 세 가지 핵심 아이디어를 통해 RISC‑V 기반 FPGA 가속기의 효율성을 크게 끌어올렸다. 첫째, 반구조적(세미‑스트럭처드) 희소성을 활용하기 위해 가중치 블록에 “look‑ahead” 비트를 삽입한다. 구체적으로 4개의 INT8 가중치를 하나의 블록으로 묶고, 그 뒤에 연속된 전부 0인 블록 수(0~15)를 4비트로 인코딩한다. 이 비트는 가중치의 LSB에 추가되며, 연산 유닛은 실행 시 해당 비트를 추출해 루프 인덱스를 한 번에 건너뛰게 함으로써 소프트웨어 수준의 조건 검사 비용을 완전히 제거한다. FPGA의 비트‑레벨 프로그래머블 특성을 활용해 인코딩 로직을 하드웨어에 직접 매핑함으로써, 추가 레지스터나 메모리 접근 없이도 높은 스루풋을 유지한다.
둘째, 비구조적(언스트럭처드) 희소성을 위한 가변 사이클 MAC 유닛을 설계했다. 기존 SIMD MAC은 고정된 4‑연산을 수행하지만, 제안된 유닛은 비제로 가중치 개수에 따라 곱셈 반복 횟수를 동적으로 조절한다. 이를 위해 가중치와 활성값을 스트리밍하면서 비제로 마스크를 생성하고, 마스크가 1인 경우에만 곱셈·누적을 수행한다. 이 방식은 희소 비율이 높을수록 사이클 수가 비례적으로 감소해, 평균 3배 정도의 가속을 제공한다.
셋째, 두 희소성 모델을 동시에 지원하는 복합 설계를 제시한다. 반구조적 인코딩 비트를 유지하면서, 가변 사이클 MAC 내부에 비제로 마스크 로직을 삽입해 두 종류의 스킵 메커니즘을 병행한다. 실험 결과, 이 복합 설계는 최고 5배의 속도 향상을 달성했으며, FPGA 자원 사용량은 전체 LUT·DSP 증가율이 10% 이하에 그쳐 소형 FPGA에서도 구현 가능함을 보여준다.
핵심적인 하드웨어/소프트웨어 공동 설계 흐름은 다음과 같다. (1) 모델 단계에서 희소화(2:4 혹은 비구조적 프루닝)를 적용하고, 가중치 전처리 파이프라인에서 인코딩을 수행한다. (2) 컴파일러 단계에서 새로운 RISC‑V 명령어(예: cfu_sparse_mac, cfu_varmac)를 삽입하고, 인라인 어셈블리 매크로를 통해 기존 C/C++ 코드와 연결한다. (3) FPGA 합성 단계에서는 CFU Playground와 VexRiscv를 이용해 커스텀 유닛을 삽입하고, 자동 파이프라인 삽입 및 핸드쉐이킹(valid/ready) 신호를 통해 CPU와 CFU 간의 저지연 인터페이스를 구현한다.
비교 대상인 NVIDIA 2:4 프루닝 가속, SNAP, DANN‑A 등과 달리, 이 설계는 (i) ISA 수준에서 직접 지원해 소프트웨어 이식성을 유지하고, (ii) 압축 저장 포맷을 사용하지 않으면서도 메모리 대역폭 절감 효과를 얻으며, (iii) FPGA 비트‑레벨 재구성을 활용해 가중치 자체에 메타데이터를 삽입한다는 점에서 차별화된다. 또한, 정확도 손실을 최소화하기 위해 INT8 대신 INT7(부호 비트 제외) 표현을 사용했으며, 실험에선 TinyML 대표 워크로드(KWS, 이미지 분류, 사람 검출)에서 0.5% 이하의 Top‑1 정확도 저하만을 기록했다.
한계점으로는 (a) 인코딩 과정이 가중치 재배열을 요구해 모델 업데이트 시 재컴파일이 필요하고, (b) 현재 설계는 8비트 정수 연산에 최적화돼 있어 FP16/FP32 기반 대형 모델에는 직접 적용하기 어려우며, (c) 희소 비율이 낮은 경우(예: 30% 이하)에는 스킵 메커니즘의 오버헤드가 오히려 성능을 저하시킬 수 있다. 향후 연구에서는 동적 인코딩, 다중 정밀도 지원, 그리고 메모리 인터페이스와의 협업을 통해 이러한 제약을 완화할 계획이다.
댓글 및 학술 토론
Loading comments...
의견 남기기