경량 연산과 데이터 정제로 구현한 온디바이스 증분 학습 프레임워크 LODAP
초록
LODAP은 온디바이스 환경에서 새로운 클래스를 지속적으로 학습할 수 있도록 설계된 프레임워크이다. 효율적인 증분 모듈(EIM)과 어댑터 기반 경량 연산, 그리고 EL2N 기반 데이터 프루닝을 결합해 모델 복잡도는 50% 감소시키면서 기존 방법 대비 최대 4.32%의 정확도 향상을 달성한다.
상세 분석
본 논문은 자원 제한이 심한 엣지 디바이스에서 증분 학습(Incremental Learning, IL)을 수행하기 위한 두 가지 핵심 기술을 제안한다. 첫 번째는 Efficient Incremental Module(EIM)이다. EIM은 기존의 컨볼루션 레이어를 ‘Intrinsic Features(인트린식 피처)’를 추출하는 기본 연산으로 유지하고, 새로운 클래스 학습을 위해 ‘Adapter’라 불리는 경량 연산을 추가한다. Adapter는 1×1 혹은 3×3 커널을 사용해 인트린식 피처에 작은 변환을 가함으로써 ‘Incremental Features(인크리멘탈 피처)’를 생성한다. 이러한 설계는 기존 파라미터를 거의 변경하지 않으면서도 새로운 표현력을 제공한다는 점에서 파라미터 동결 기반 방법과 차별화된다.
두 번째 핵심은 구조적 재파라미터화(Structural Re‑parameterization)를 통한 Adapter Fusion이다. 증분 단계가 누적될수록 어댑터 수가 증가해 메모리 풋프린트가 커지는 문제를 해결하기 위해, 각 단계에서 학습된 어댑터 가중치를 zero‑padding 후 기존 ‘Cheap Feature’ 가중치와 합산한다. 이렇게 하면 추론 시에는 단일 컨볼루션 연산만 남게 되어 연산량과 메모리 사용량이 크게 감소한다.
데이터 측면에서는 EL2N(Error L2‑Norm) 점수를 이용한 Progressive Data Pruning을 적용한다. 학습 초기 단계에서 손실 기울기의 L2 노름을 계산해 낮은 점수를 가진 샘플을 제거함으로써, 전체 학습 데이터 양을 약 50%까지 감소시킨다. 흥미롭게도, 데이터 양을 줄였음에도 불구하고 모델 정확도가 소폭 상승하는 현상이 관찰되었으며, 이는 노이즈가 많은 샘플을 효과적으로 배제했기 때문으로 해석된다.
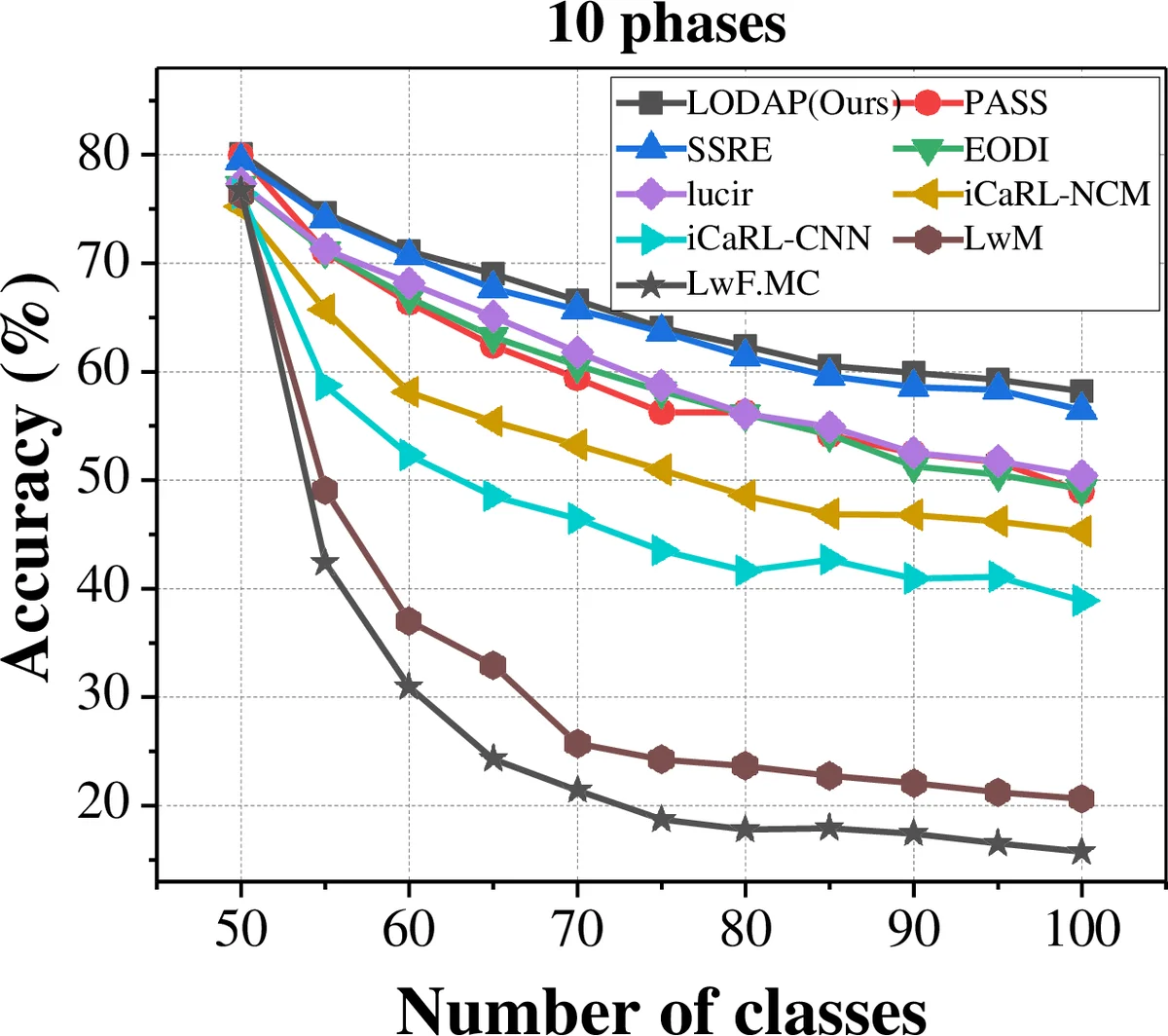
실험에서는 CIFAR‑100과 Tiny‑ImageNet 두 데이터셋을 사용해 기존 최첨단 방법들과 비교하였다. LODAP은 평균 2.1%~4.3%의 정확도 향상을 보였으며, 파라미터 수는 절반 수준으로 감소했다. 또한 실제 모바일 GPU(NVIDIA Jetson Nano, Snapdragon 845)에서의 학습 시간과 전력 소모를 측정한 결과, 기존 방법 대비 30%~45%의 효율성을 달성했다.
전체적으로 LODAP은 (1) 경량 어댑터를 통한 새로운 클래스 학습, (2) 구조적 재파라미터화를 통한 메모리·연산 효율화, (3) EL2N 기반 데이터 프루닝으로 학습 비용 절감이라는 세 축을 조화롭게 결합했다. 다만, 어댑터의 하이퍼파라미터 s와 프루닝 비율에 대한 민감도 분석이 제한적이며, 대규모 실시간 스트리밍 데이터에 대한 적용 가능성은 추가 검증이 필요하다.
댓글 및 학술 토론
Loading comments...
의견 남기기