협대역 오디오 키워드 스팟팅을 위한 다중인스턴스 계단식 분류
본 논문은 8 kHz 협대역 음성에서 “Okay Eva”와 같은 호출어를 실시간으로 인식하기 위해, 멀티피처(MFCC·PLP)와 다중인스턴스 학습을 결합한 3단계 계단식 DNN 구조를 제안한다. 클래스 불균형을 완화하고, 초기 단계에서 부정 샘플을 빠르게 차단해 연산량을 절감한다. 실험 결과, 6 %의 누락률에 0.75 회/시간의 오탐률을 달성하였다.
저자: Ahmad AbdulKader, Kareem Nassar, Mohamed El-Geish
본 논문은 Voicera의 기업용 음성 비서 Eva가 회의 중 실시간으로 “Okay Eva”라는 호출어를 인식하도록 설계된 키워드 스팟팅(KWS) 시스템을 제시한다. 기존 상용 비서는 주로 와이드밴드(16 kHz) 음성을 대상으로 하며, 높은 샘플링 레이트와 전용 하드웨어 덕분에 높은 정확도를 유지한다. 그러나 전화망을 통한 협대역(8 kHz) 음성은 스펙트럼이 제한되고 코덱 손실이 커서 인식 성능이 크게 저하된다. 또한, 다양한 마이크, 환경, 화자, 잡음 프로파일이 존재해 데이터가 비독립동일분포(IID) 가정에서 벗어나므로 모델의 일반화가 어려워진다.
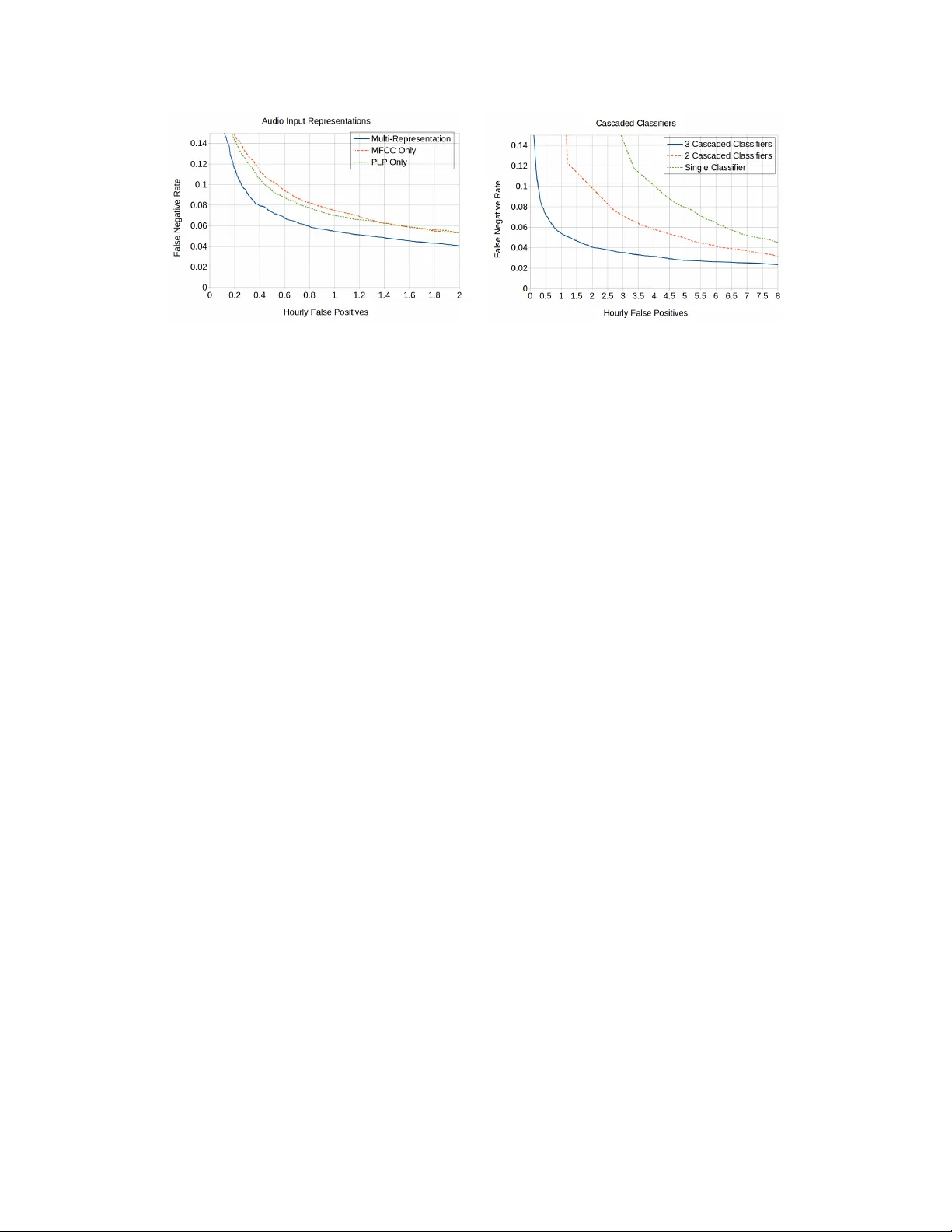
이를 해결하기 위해 저자는 다음과 같은 네 가지 핵심 기술을 결합한다. 첫째, 멀티피처 접근법으로 MFCC와 PLP 두 종류의 음성 특징을 동시에 추출한다. 두 특징은 서로 다른 스펙트럼 정보를 강조하므로, 결합 시 노벨티 탐지 문제를 완화하고 오탐률을 낮출 수 있다. 둘째, 3단계 계단식(classifier cascade) 구조를 도입한다. 각 단계는 완전 연결형 DNN(두 개의 128‑노드 은닉층)으로 구성되며, 첫 번째 단계는 부정 샘플을 1:100 비율로 학습시켜 빠르게 대부분의 비키워드 구간을 걸러낸다. 이후 단계는 이전 단계에서 남은 하드 네거티브와 양성 샘플을 2:1 비율로 재학습해 점진적으로 판별 경계를 정교화한다. 이 과정은 연산량을 크게 절감하고, 실시간 디바이스에서 전력 소모를 최소화한다. 셋째, 키워드가 정확히 언제 발생하는지 알 수 없는 상황을 다중인스턴스 학습(MIL) 프레임워크로 모델링한다. 500 ms 길이의 윈도우를 10 ms 간격으로 겹쳐 ‘bag’를 구성하고, 각 윈도우의 출력 확률을 ‘Noisy‑Or’ 연산으로 결합해 최종 트리거 결정을 내린다. 이를 통해 발화 길이와 발음 변형이 300 ms에서 900 ms까지 다양해도 robust하게 인식한다. 넷째, 데이터 수집 단계에서 19 k개의 양성 예시(200명 화자)와 다양한 회의 녹음에서 추출한 부정 예시를 확보하고, 화자 단위로 학습/평가 데이터를 분리해 스피커 독립성을 보장한다.
실험 결과, 단일 특징(MFCC 또는 PLP)만 사용했을 때는 7 % 누락률에 1.0~1.2 회/시간의 오탐률을 보였으나, 두 특징을 결합한 멀티피처 모델은 동일 누락률에서 0.55 회/시간으로 절반 이하로 감소했다. 또한, 1단계, 2단계, 3단계 계단식 구조를 순차적으로 적용했을 때 ROC 곡선이 지속적으로 개선되어 최종 3단계 모델이 가장 높은 성능을 달성했다. 최종 시스템은 6 %의 누락률에 0.75 회/시간의 오탐률을 기록했으며, 이는 기존 DNN 기반 KWS(8 % 누락, 1.2 회/시간)보다 85 % 이상의 개선이다. 논문은 또한 이 시스템이 와이드밴드 16 kHz 환경에서 Google의 DNN 기반 KWS보다도 우수한 성능을 보인다고 주장한다(데이터셋 차이로 직접 비교는 어려움).
결론적으로, 협대역 음성 환경에서 실시간 키워드 스팟팅을 구현하기 위해 멀티피처, 계단식 학습, 그리고 다중인스턴스 학습을 효과적으로 결합한 접근법을 제시한다. 향후 연구에서는 더 다양한 잡음 조건, 실시간 지연 분석, 그리고 온‑디바이스 메모리 제한을 고려한 경량화 모델 설계가 필요하다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기