휴머노이드 로봇을 위한 확산 트랜스포머 기반 표현형 얼굴 제어 시스템
초록
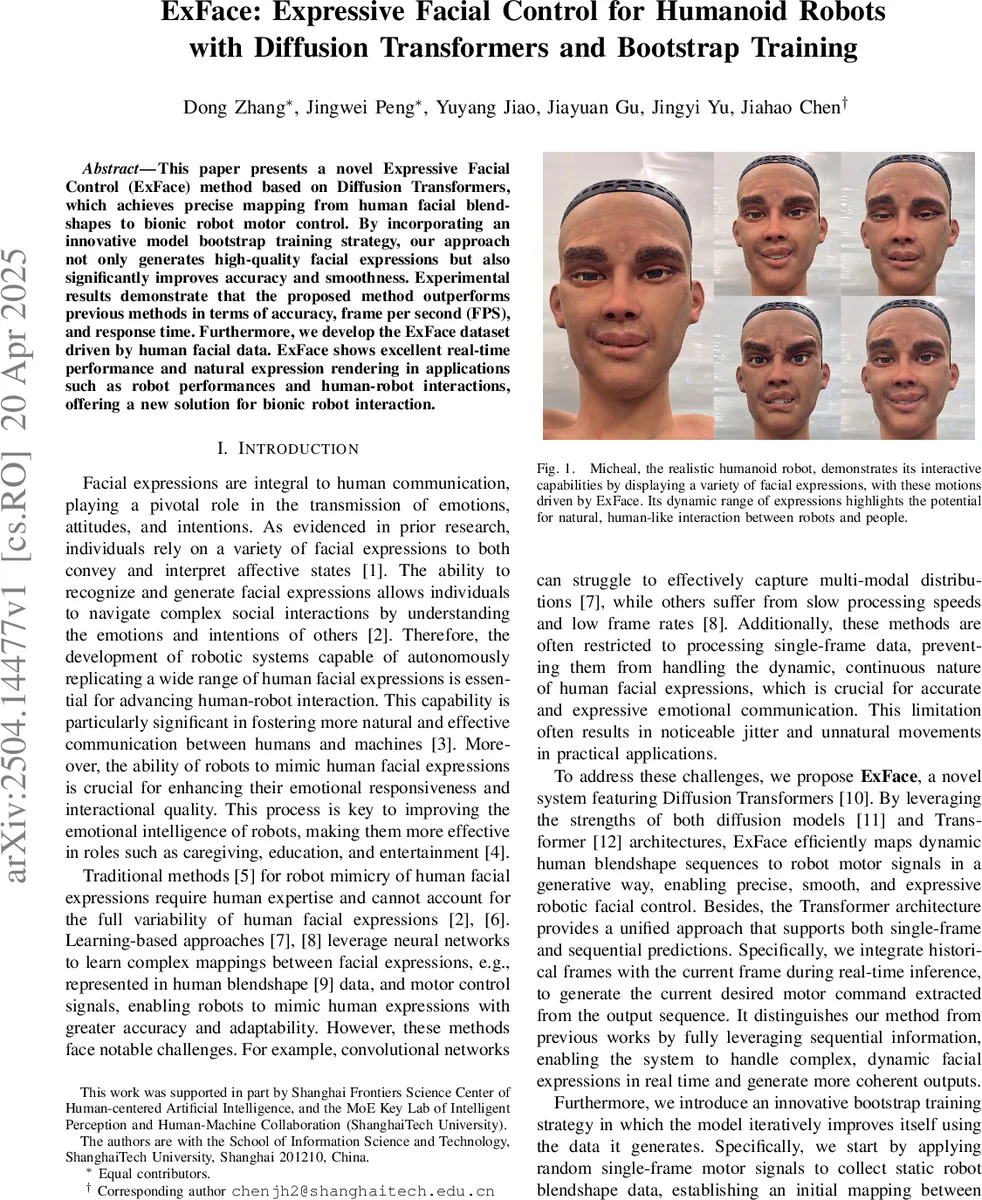
ExFace는 인간의 블렌드쉐이프 데이터를 로봇 모터 제어값으로 정밀 매핑하기 위해 확산 트랜스포머와 부트스트랩 학습 전략을 결합한 새로운 프레임워크이다. 60 FPS 실시간 구동, 0.15 s 응답시간, 그리고 기존 MLP·Transformer 대비 낮은 MSE를 달성했으며, 두 종류의 로봇(Michael, Hobbs)와 공개 데이터셋을 통해 일반화 가능성을 입증한다.
상세 분석
ExFace 논문은 인간 얼굴 블렌드쉐이프와 로봇 모터 제어 사이의 비선형 매핑 문제를 해결하기 위해 두 가지 핵심 기술을 제안한다. 첫 번째는 확산 모델(Denoising Diffusion Probabilistic Model, DDPM)의 원리를 트랜스포머 구조와 결합한 ‘Diffusion Transformer’이다. 기존 CNN 기반 혹은 단일 프레임 Transformer는 멀티모달 분포를 포착하거나 시계열 정보를 충분히 활용하지 못한다는 한계를 지적하고, 확산 과정에서 단계별 노이즈를 제거하면서 시퀀스 전체의 연속성을 보존한다. 트랜스포머의 self‑attention 메커니즘은 현재 프레임과 과거 119 프레임을 동시에 고려해 조건부 생성(c)으로 블렌드쉐이프를 입력하고, 역확산 단계에서 모터값(x₀)을 점진적으로 복원한다. 이는 고차원 55‑dim 블렌드쉐이프를 33‑dim 모터값으로 매핑할 때 발생하는 복잡한 비선형 관계를 효과적으로 학습한다는 점에서 의미가 크다.
두 번째는 ‘Bootstrap Training’ 전략이다. 초기에는 무작위 단일 프레임 모터 신호를 로봇에 적용해 정적 블렌드쉐이프–모터 쌍(600개)을 수집하고, 이를 기반으로 초벌 모델을 학습한다. 이후 이 모델을 사용해 인간 블렌드쉐이프 입력에 따라 동적 표현 시퀀스를 생성하고, 로봇이 실제로 수행한 결과 블렌드쉐이프를 다시 수집한다. 이렇게 얻은 동적 데이터(매 반복 4,000~8,000 프레임)를 기존 데이터에 추가해 모델을 재학습함으로써 점진적으로 매핑 정확도와 시퀀스 일관성을 향상시킨다. 실험에서는 부트스트랩 과정을 거칠수록 Motor Distance와 Blendshape Distance가 지속적으로 감소함을 그래프로 제시, 데이터 효율성과 자기 개선 능력을 입증한다.
데이터 수집은 Apple ARKit을 이용해 인간과 로봇 양쪽의 55‑dim 블렌드쉐이프를 실시간 캡처하고, 로봇은 42 DOF 중 얼굴 표현에 해당하는 33 DOF만을 사용한다. 두 로봇 플랫폼(Michael – 케이블 구동, Hobbs – 관절 구동)에서 동일한 파이프라인을 적용해 일반화 성능을 검증하였다.
성능 평가는 MSE 기반 Motor Distance와 Blendshape Distance, 그리고 실시간 처리 속도(FPS)와 응답시간을 포함한다. ExFace는 기존 MLP(0.0465, 0.0039)·Transformer(0.0383, 0.0029) 대비 각각 0.0353, 0.0025의 최저값을 기록했고, 60 FPS, 0.15 s 응답시간을 달성했다. 이는 로봇 표정이 인간 표정에 거의 실시간으로 동기화될 수 있음을 의미한다.
한계점으로는 현재 120 프레임(≈2 s) 길이의 고정 시퀀스에 최적화돼 장시간 연속 표현이나 급격한 표정 전환에 대한 일반화가 미흡할 수 있다. 또한 ARKit 기반 블렌드쉐이프는 조명·포즈 변화에 민감하므로, 다양한 환경에서의 견고성 검증이 추가로 필요하다.
전반적으로 ExFace는 확산 모델과 트랜스포머의 장점을 결합해 로봇 얼굴 제어의 정확도·부드러움·실시간성을 동시에 달성한 혁신적 접근이며, 부트스트랩 학습을 통한 데이터 효율성 증대는 향후 로봇‑인간 상호작용 시스템에 중요한 설계 원칙이 될 전망이다.
댓글 및 학술 토론
Loading comments...
의견 남기기