초고속 비디오 이상 탐지를 위한 Mamba 기반 VADMamba
초록
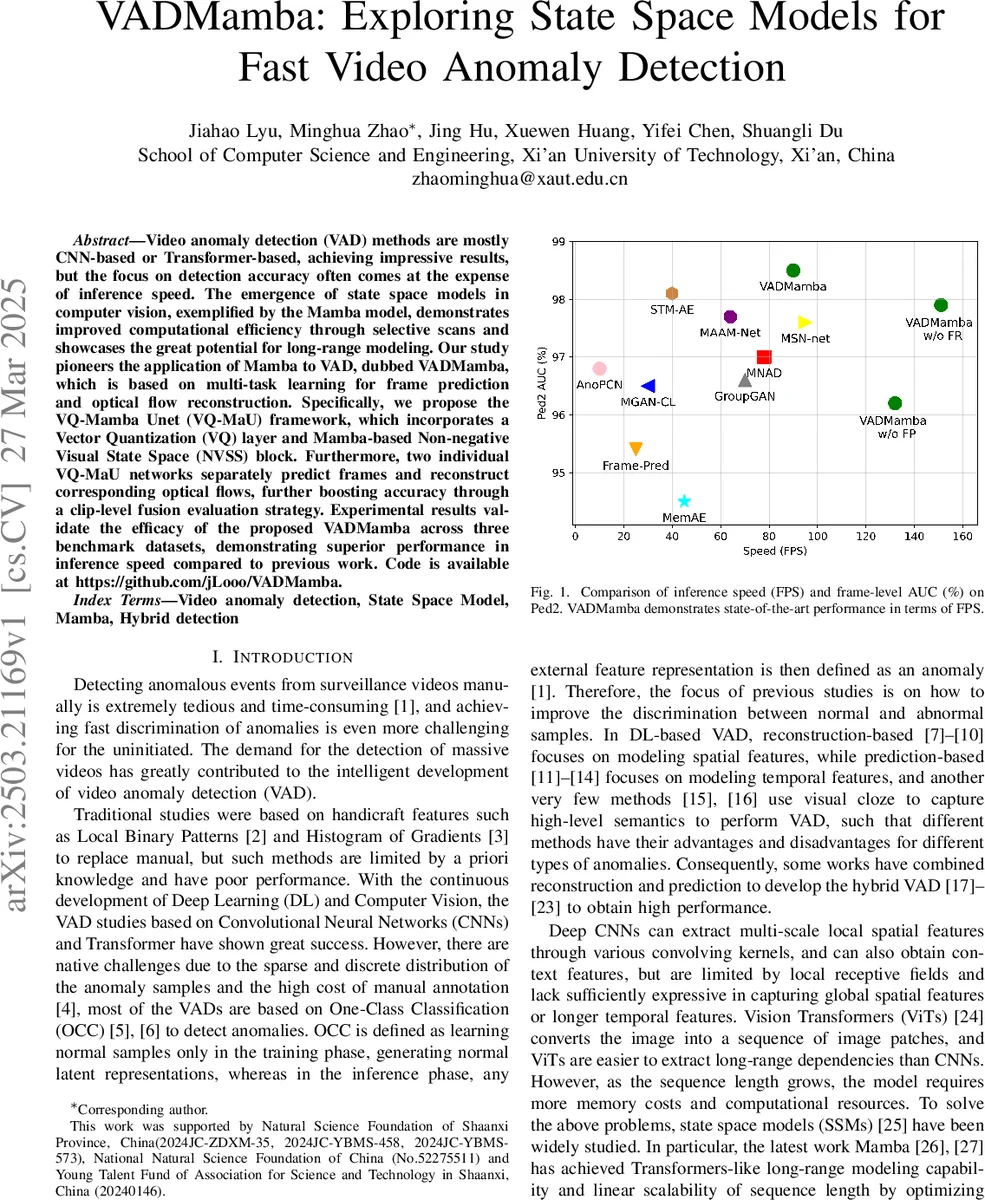
VADMamba는 최신 상태공간 모델인 Mamba를 활용해 프레임 예측과 광류 재구성을 동시에 학습하는 하이브리드 비디오 이상 탐지 프레임워크이다. VQ‑MaU(Unet) 구조에 벡터 양자화와 비음수 시각 상태공간(NVSS) 블록을 도입해 특징 압축 및 장거리 의존성 모델링을 효율화했으며, 클립‑레벨 융합 전략으로 두 작업의 점수를 결합한다. 세 가지 벤치마크에서 AUC는 최고 수준을 기록하고, 90~151 FPS의 추론 속도로 기존 방법을 크게 앞섰다.
상세 분석
본 논문은 비디오 이상 탐지(VAD) 분야에서 정확도와 실시간성을 동시에 만족시키기 어려운 기존 CNN·Transformer 기반 접근법의 한계를 Mamba 기반 상태공간 모델(SSM)로 극복하고자 한다. 핵심 기여는 세 가지로 요약된다. 첫째, VQ‑MaU라는 Unet‑형식의 인코더‑디코더에 벡터 양자화(VQ) 레이어와 NVSS 블록을 결합함으로써, 고차원 특징을 압축하면서도 비음수 활성화와 선택적 스캔(Selective‑Scan) 메커니즘을 통해 전역 수용 영역을 확보한다. 이는 기존 CNN이 갖는 제한된 수용 영역과 ViT가 초래하는 O(N²) 연산 비용을 선형적으로 대체한다. 둘째, 프레임 예측(FP)과 광류 재구성(FR)이라는 두 개의 보조 작업을 멀티태스크 학습으로 설계했으며, FP를 먼저 학습하고 그 최적 모델을 초기화로 사용해 FR을 학습함으로써 각 작업의 수렴 속도 차이를 효과적으로 조정한다. 세 번째로, 클립‑레벨 융합 전략을 도입해 프레임‑레벨 PSNR 점수와 광류‑레벨 PSNR 점수 중 AUC가 높은 쪽을 선택하고, 이를 클립 단위로 결합한다. 이는 배경 변화가 큰 데이터셋(Avenue)에서 광류가 배경 잡음을 억제하는 장점을 살려 전체 성능을 끌어올린다. 실험 결과, Ped2, Avenue, SHT 세 데이터셋에서 AUC 98.5 %·91.5 %·77.0 %를 달성했으며, 특히 90 FPS 이상의 추론 속도는 기존 최고 수준(1078 FPS)보다 29배 빠르다. Ablation 연구에서는 VQ와 비음수 강화(NE) 모듈 각각의 기여를 확인했으며, VQ가 프레임 예측에, NE가 광류 재구성에 더 큰 효과를 보이는 것을 밝혀냈다. 전체적으로, Mamba 기반 SSM을 VAD에 최초 적용하고, 효율적인 압축·전역 모델링·멀티태스크 융합을 통해 정확도와 속도 양쪽을 동시에 최적화한 점이 가장 큰 혁신이라 할 수 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기