LLM 기반 상향식 섹터 배분으로 자동 트레이딩 혁신
초록
본 논문은 대형 언어 모델(LLM)을 활용해 거시경제 지표와 시장 정서를 동시에 분석하고, 이를 토대로 섹터 수준의 상향식 포트폴리오 배분을 자동화하는 프레임워크를 제안한다. 실증 결과, 기존 교차 모멘텀 전략 대비 연 8.79%의 수익률과 2.51의 샤프 비율을 달성하며, 거시·정서 통합 접근법의 효율성을 입증한다.
상세 분석
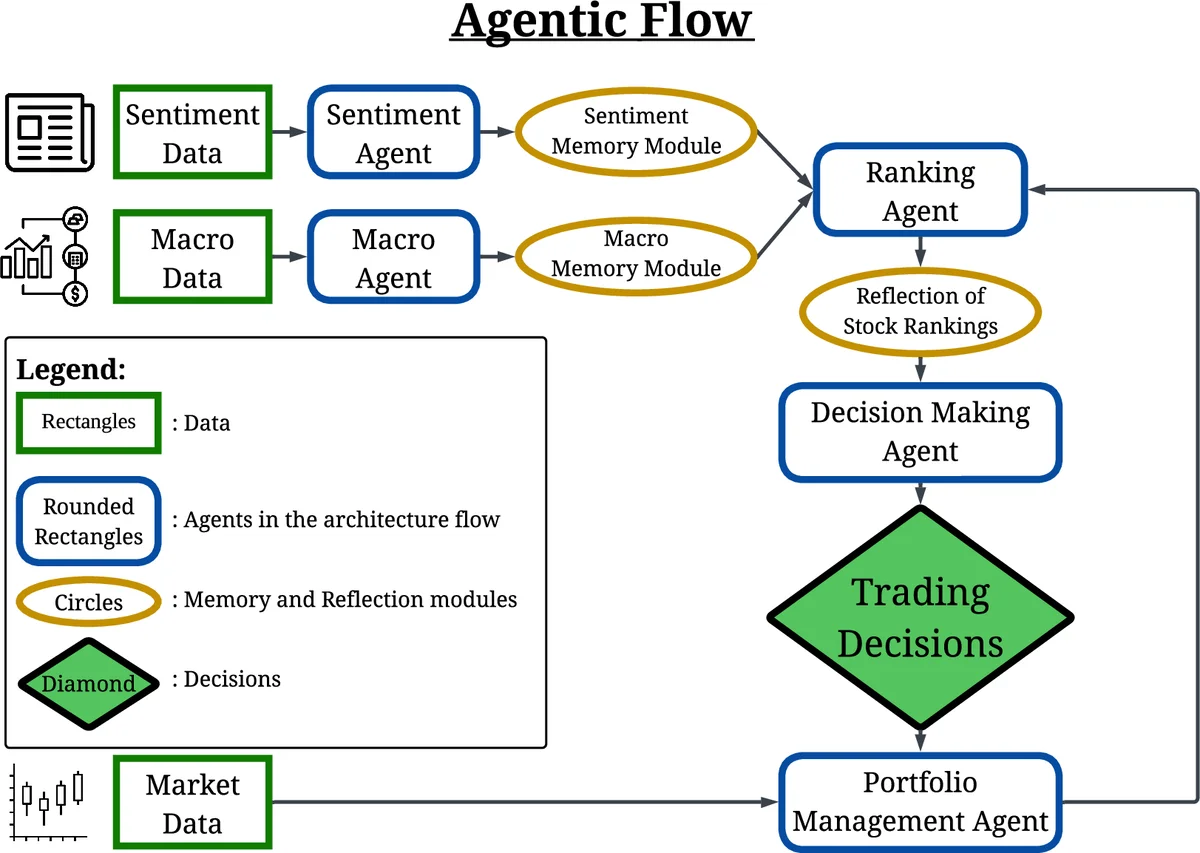
본 연구는 LLM을 단순 예측 도구가 아니라 “멀티‑스트림 인텔리전스 엔진”으로 재구성한다. 먼저 뉴스 API와 정책 문서, 경제 지표를 실시간으로 수집하고, DeepSeek‑7B‑Chat 모델을 이용해 두 단계의 자연어 처리(NER·ABSA)를 수행한다. NER은 종목명·시장 키워드 식별을, ABSA는 ‘인플레이션’, ‘금리’, ‘고용’ 등 구체적 측면에 대한 감성 점수를 추출한다. 감성‑측면 쌍은 ‘Sentiment Memory’에 저장돼 과거 정서 흐름을 장기적으로 보존한다.
거시경제 스트림은 CPI, PPI, PCE, NFP, PMI 등 핵심 지표의 월간 변동률을 계산하고, FOMC 회의록을 LLM 요약하여 ‘Macro Memory’에 저장한다. 이렇게 정형·비정형 데이터를 동시에 제공받은 ‘Ranking Agent’는 세 단계의 의사결정 프로세스를 수행한다. ① 거시경제 분석 단계에서 인플레이션·성장·통화정책의 현재 상황을 평가하고, 각 GICS 섹터가 해당 환경에서 기대되는 상대적 퍼포먼스를 추정한다. ② 섹터 배분 단계에서는 목표 섹터 비중을 최적화하고, 기존 포트폴리오와의 차이를 최소화하도록 리밸런싱 명령을 생성한다. ③ 정서 통합 단계에서는 섹터 내 개별 종목을 선택할 때, 앞서 저장된 감성‑측면 쌍을 활용해 ‘긍정적 정서가 강화될 가능성’이 높은 종목을 롱, ‘부정적 정서가 확대될 위험’이 큰 종목을 숏 포지션에 할당한다.
시뮬레이션은 2019년 1월~6월의 S&P 500 구성 종목을 대상으로 수행했으며, 생존 편향을 방지하기 위해 인덱스 변동을 실시간으로 반영했다. 비교 대상은 전통적인 교차 모멘텀 전략이며, LLM 기반 전략은 연 8.79%의 절대 수익률과 2.51의 샤프 비율을 기록해 -0.61·-1.39%를 보인 기존 전략을 크게 앞섰다. 특히 변동성이 높은 시기에도 포트폴리오 위험이 제한적이었으며, 섹터 레벨에서의 리스크 분산 효과가 두드러졌다.
한계점으로는 백테스트 기간이 짧고, 데이터 비용 제한으로 6개월에 국한된 점, 그리고 DeepSeek‑7B‑Chat 모델의 파라미터 규모가 상대적으로 작아 복잡한 거시경제 텍스트 해석에 한계가 있을 수 있다는 점을 들 수 있다. 향후 연구에서는 장기적인 시계열 검증, 모델 앙상블, 그리고 멀티모달(텍스트·수치·이미지) 입력을 통한 정교한 매크로·미시 통합을 모색할 필요가 있다.
댓글 및 학술 토론
Loading comments...
의견 남기기