비정형 행렬 시계열의 공적분 관계 탐지
본 논문은 행렬 형태의 비정상 시계열에 대해 행과 열 각각에 별도의 공적분 차원을 부여하는 Matrix Error Correction Model(MECM)을 제안한다. 정보 기준(AIC, BIC)을 이용해 행과 열의 공적분 순위(r₁, r₂)를 선택하고, 시뮬레이션 및 12개 변수(3개 지표×4개 국가) 거시경제 데이터에 적용해 하나의 공적분 관계가 존재함을 확인한다.
저자: Alain Hecq, Ivan Ricardo, Ines Wilms
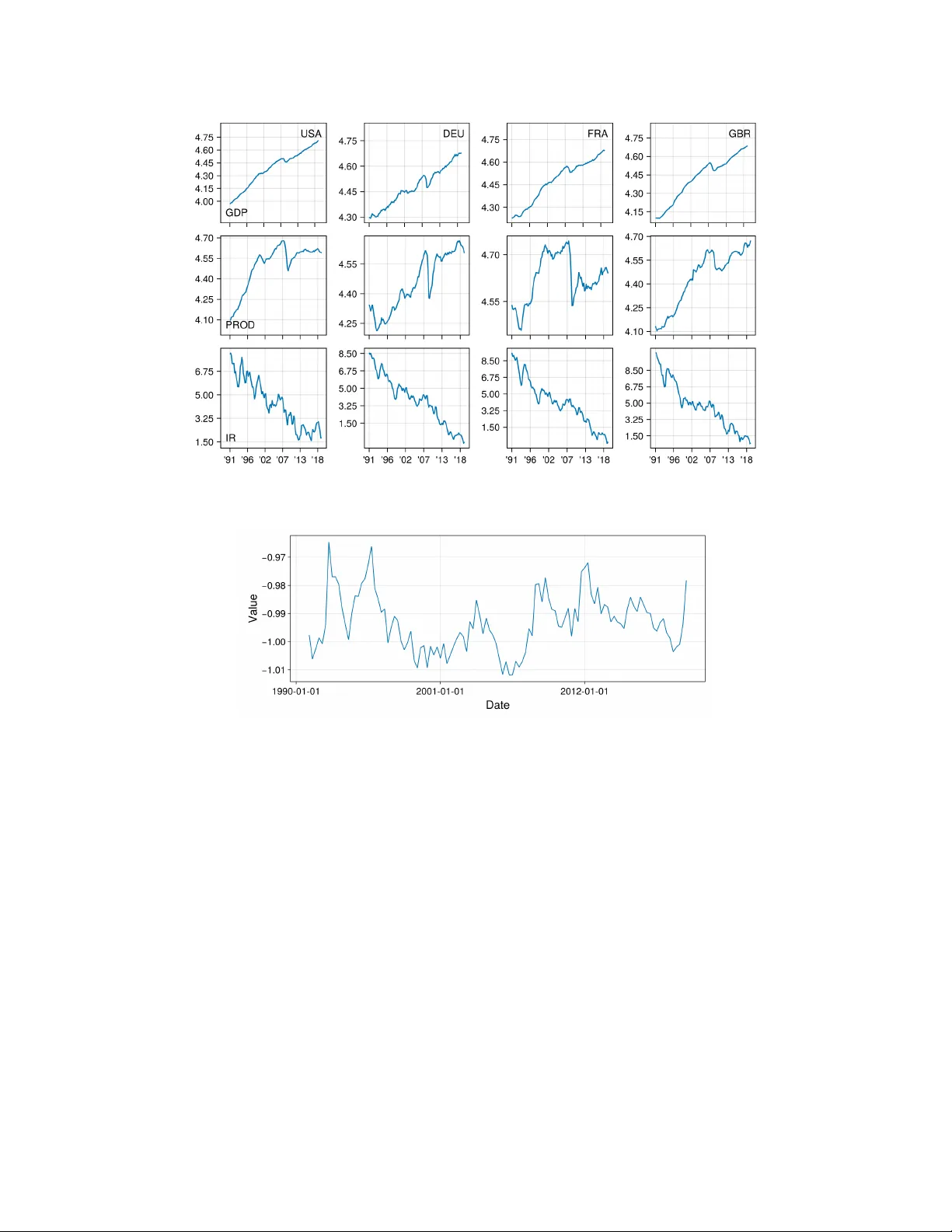
본 논문은 행렬 형태의 비정상 시계열 데이터를 분석하기 위한 새로운 프레임워크인 Matrix Error Correction Model(MECM)을 제시한다. 기존의 Vector Error Correction Model(VECM)은 변수 수가 증가하면 차원 폭발과 파라미터 과다 추정 문제에 직면한다. 이를 해결하고자 저자들은 N₁×N₂ 형태의 데이터에 대해 행과 열 각각에 독립적인 공적분 차원(r₁, r₂)을 부여하고, α, β, Φₖ에 Kronecker 구조를 강제하는 모델을 설계한다. 구체적으로 식(2)에서는 ΔYₜ = D + U₁U₃'Yₜ₋₁U₄U₂' + Σ_{j=1}^p Φ₁,j ΔYₜ₋ⱼ Φ₂,j' + Eₜ 로 표현되며, 여기서 U₃∈ℝ^{N₁×r₁}, U₄∈ℝ^{N₂×r₂}는 행·열의 공적분 행렬, U₁, U₂는 조정 계수 행렬이다. 오류항 Eₜ는 행렬 정규분포 MVN(0, Σ₁, Σ₂)를 가정해, 행·열 각각의 공분산 구조를 명시한다.
모델 파라미터는 로그우도식(4)를 최대화함으로써 추정한다. 로그우도는 Σ₁, Σ₂의 행렬식과 트레이스 형태로 구성되어 비선형 최적화 문제를 만든다. 저자는 Wang et al. (2024)의 gradient ascent 알고리즘을 변형해, 각 파라미터를 순차적으로 업데이트하는 절차를 제시한다. 초기값은 Chen et al. (2021)의 projection 방법을 사용하고, 식별성을 위해 U₃와 U₄의 상위 r₁×r₁, r₂×r₂ 블록을 단위행렬로 고정한다. 이는 회전 불확정성을 제거하고, Σ₁은 Frobenius norm을 1로 정규화해 부호만 남도록 한다.
공적분 차원(r₁, r₂)의 선택은 AIC와 BIC를 그대로 적용한다. 여기서 자유도 ψ(r₁,r₂,p)=r₁(2N₁−r₁)+r₂(2N₂−r₂)+p(N₁²+N₂²) 를 사용해 벌점(term)으로 반영한다. 시뮬레이션에서는 두 가지 DGP(MECM(0)와 MECM(1))를 설정하고, N₁=3, N₂=4, T=100 및 T=250의 표본 크기에서 4가지 진짜 순위 조합((1,1),(3,1),(1,4),(3,4))을 검증한다. 결과는 Table 1에 요약되며, 특히 BIC가 (1,1) 순위에서 95% 이상 정확도를 보이고, 표본이 커질수록 AIC와 BIC 모두 100%에 근접한다. 이는 정보 기준이 행·열 별 독립적인 차원을 동시에 고려해도 과적합 위험이 낮으며, 작은 표본에서도 신뢰할 수 있음을 입증한다.
실증 분석에서는 1991Q1~2019Q4 기간의 12개 변수(3개 지표×4개 국가)를 사용한다. 모든 변수는 Augmented Dickey‑Fuller 검정에서 I(1)임을 확인했으며, MECM(1) 모델을 추정한 결과 AIC와 BIC 모두 (r₁,r₂)=(1,1) 을 선택했다. 이는 12변수가 하나의 장기 균형 관계에 묶인다는 의미이다. 추정된 U₃ 행렬은 GDP, 산업생산, 장기금리가 모두 양의 공동이동을 보이며, U₄ 행렬은 미국과 프랑스 간 공적분 관계가 가장 강하고, 독일·영국과는 상대적으로 약함을 나타낸다. 이러한 해석은 기존의 패널 공적분 분석보다 직관적이며, 행·열 차원의 구분된 해석을 가능하게 한다.
논문은 또한 모델의 한계와 향후 연구 방향을 제시한다. 첫째, Kronecker 구조가 실제 데이터에 적합한지 검증하는 사양 검정이 필요하다. 저자는 Chen et al. (2021) 방식의 확장을 제안한다. 둘째, 고차원 상황(N₁·N₂≫T)에서는 현재 gradient ascent가 수렴 속도와 메모리 측면에서 한계가 있으므로, sparse 혹은 low‑rank 정규화와 결합한 방법이 요구된다. 셋째, 단기 동태를 보다 유연하게 모델링하기 위해 제한 없는 AR(p) 구조를 도입할 수도 있다. 전반적으로 본 연구는 행렬 시계열의 장기 공적분 분석에 새로운 도구를 제공하고, 정보 기준을 통한 순위 선택이 실용적이며 신뢰할 수 있음을 실증과 시뮬레이션을 통해 입증한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기