임상 예측모델 개발을 위한 개인 위험 추정 정확도 기반 표본 크기 설계
** 본 논문은 임상 예측모델을 개발할 때 개별 환자 수준의 위험 추정치가 충분히 정확하도록 표본 크기를 산정하는 새로운 방법을 제시한다. Fisher 정보 행렬을 이용해 위험 추정치의 분산을 예측 변수와 전체 표본 크기로 분해하고, 이를 통해 개별 위험 추정치의 불확실성 구간과 분류 불안정성을 사전에 평가한다. 다섯 단계 절차와 시각화 도구를 제공해 연구자가 목표 정확도와 공정성을 만족하는 최소 표본 크기를 손쉽게 결정하도록 돕는다. *…
저자: Richard D Riley, Gary S Collins, Rebecca Whittle
**
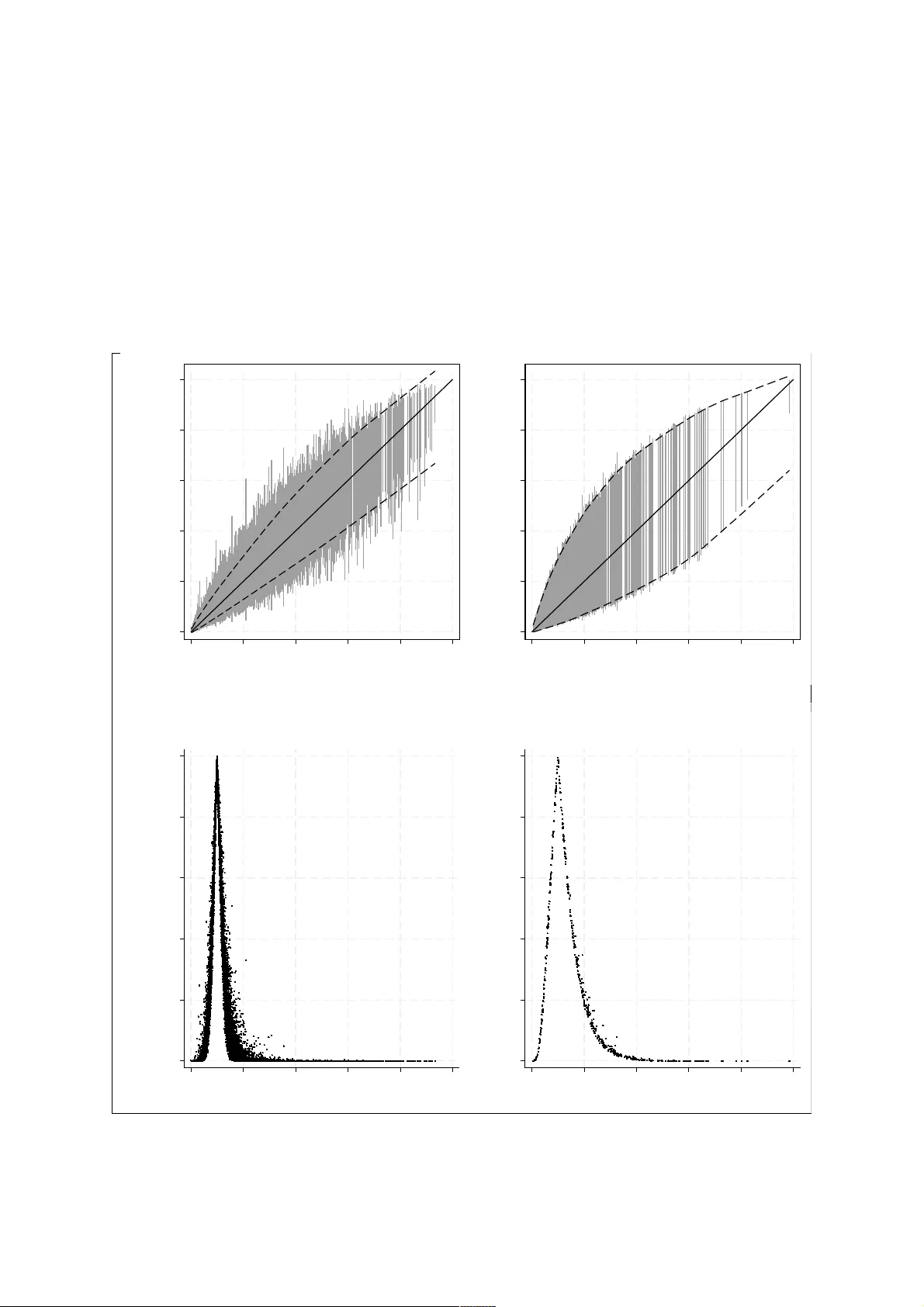
이 논문은 임상 예측모델을 개발할 때 흔히 간과되는 “개인 수준 위험 추정치의 정확도”에 초점을 맞추어, 표본 크기 설계에 새로운 통계적 프레임워크를 제시한다. 기존 연구는 주로 모델 전반의 과적합을 방지하고 전체 위험을 정확히 추정하기 위한 최소 사건 수(EPP)나 shrinkage factor와 같은 지표를 사용해 왔다. 그러나 이러한 지표는 모델이 전체적으로는 안정적이더라도 개별 환자에게 제공되는 위험 점수가 크게 변동할 수 있음을 충분히 반영하지 못한다. 특히, 위험 추정치가 임계값(예: 치료 시작 기준) 근처에 위치할 경우 작은 표본 변동에 의해 분류가 바뀌는 “분류 불안정성”이 발생하고, 이는 임상 의사결정의 신뢰성을 저하시켜 공정성 문제를 야기한다.
### 이론적 배경
저자들은 로지스틱 회귀 모델을 전제로 하여, Fisher 정보 행렬 \(I(\beta)\) 의 역행렬이 회귀계수 \(\hat\beta\) 의 공분산을 제공한다는 사실을 활용한다. 위험 추정치 \(\hat p_i = \text{logit}^{-1}(x_i^\top\hat\beta)\) 에 대한 1차 근사식은 다음과 같다.
\
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기