계층형 위치 인코딩 기반 연속 초해상도 모델 HIIF
초록
HIIF는 기존 MLP 기반 INR의 한계를 극복하기 위해 다중 스케일 계층형 위치 인코딩과 멀티헤드 선형 어텐션을 결합한 연속 이미지 초해상도 프레임워크이다. 이를 기존 EDSR, RDN, SwinIR 등 백본에 적용했을 때 PSNR이 최대 0.17 dB 향상되었으며, 인코더와 디코더가 계층적으로 정보를 공유해 고주파 디테일을 효과적으로 복원한다.
상세 분석
본 논문은 연속 초해상도(continuous ISR) 분야에서 INR(Implicit Neural Representation)의 표현력을 한 단계 끌어올리는 방법을 제시한다. 기존 LIIF, LTE 등은 좌표와 로컬 특징을 MLP에 입력해 연속적인 RGB 값을 예측했지만, 좌표 인코딩이 단일 스케일에 머물러 주변 샘플 간의 계층적 관계를 충분히 활용하지 못한다는 한계가 있었다. HIIF는 이 문제를 두 가지 핵심 아이디어로 해결한다. 첫째, 계층형 위치 인코딩을 도입한다. 입력 좌표 (x, y)를 여러 레벨 l (0 ~ L‑1)에서 정수화·정규화하여 서로 다른 해상도 격자를 만든 뒤, 각 레벨별 인코딩 δ_h(x,q,l)을 순차적으로 MLP에 결합한다. 이렇게 하면 같은 레벨의 이웃 샘플은 동일한 네트워크 파라미터를 공유하고, 더 높은 레벨에서는 더 미세한 위치 정보를 제공해 다중 주파수 대역을 동시에 학습할 수 있다. 둘째, **멀티헤드 선형 어텐션(Multi‑Head Linear Attention, MHA)**을 디코더에 삽입한다. 기존의 전통적인 self‑attention은 O(N²) 복잡도로 좌표 수가 많아지면 비효율적이며, 지역적인 컨볼루션만으로는 전역 정보를 포착하기 어렵다. 선형 어텐션은 키와 밸류를 저차원으로 투사해 연산량을 크게 줄이면서도 여러 헤드가 서로 다른 표현 서브스페이스를 학습하도록 하여, 고주파 디테일과 전역 구조를 동시에 강화한다.
구조적으로 HIIF는 (1) 인코더 E_φ: 기존 ISR 백본(EDSR, RDN, SwinIR)을 그대로 사용해 저해상도 이미지에서 동일한 공간 해상도의 특징 맵 z∈ℝ^{H×W×C_enc}을 추출한다. (2) 디코더 D_ρ: 각 좌표마다 4개의 가장 가까운 latent code를 선택하고, 계층형 인코딩을 적용한 후 MLP와 MHA를 순차적으로 통과시켜 최종 RGB 값을 얻는다. 마지막으로 bilinear upsampled LR 이미지와 결과를 skip‑connection으로 합산해 최종 HR 이미지를 생성한다.
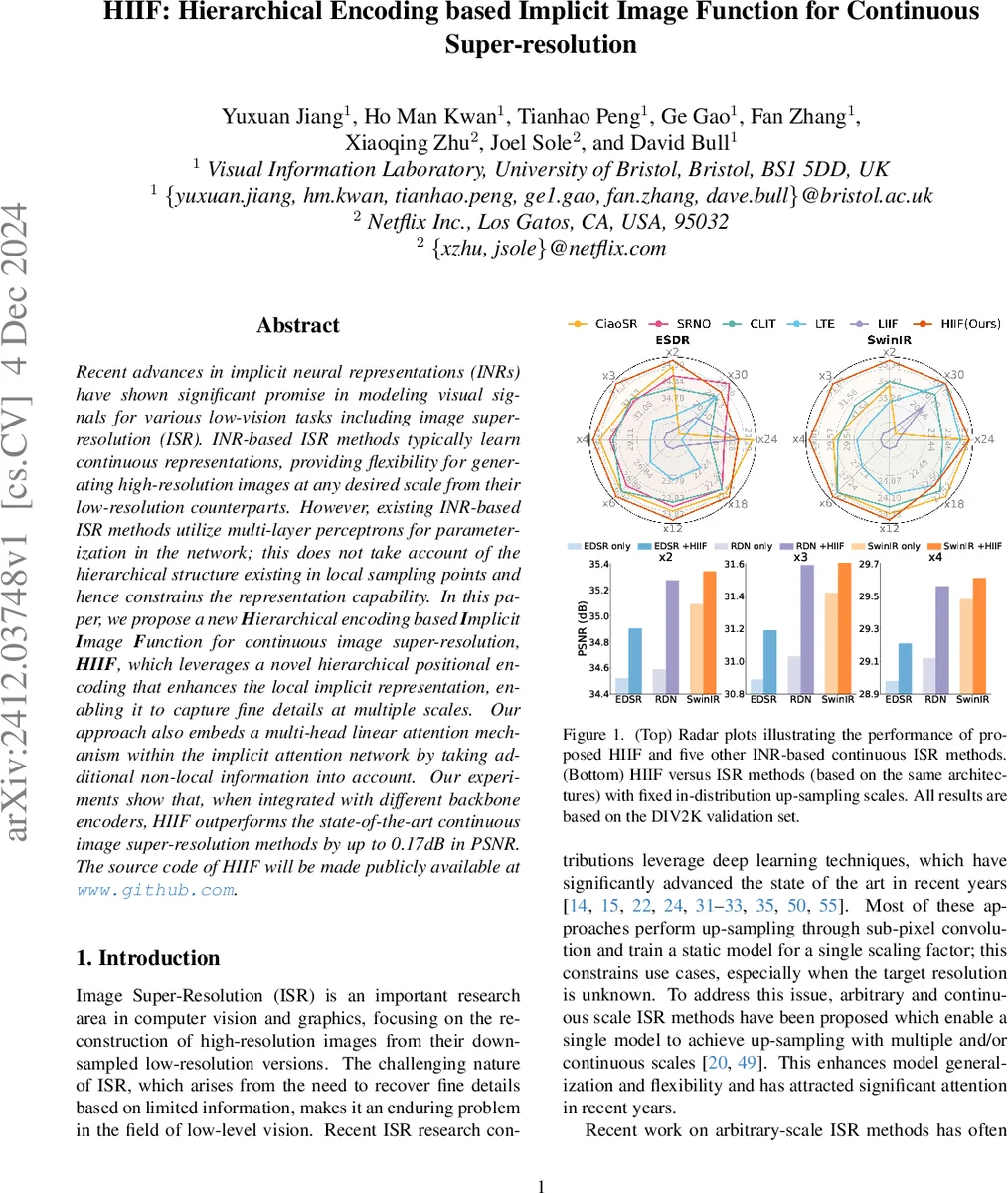
실험에서는 DIV2K 검증셋과 Set5에 대해 다양한 스케일(×2~×30)에서 in‑distribution 및 out‑of‑distribution 성능을 평가했다. 표 1에 따르면, 동일 백본에 HIIF를 적용했을 때 PSNR이 평균 0.07~0.17 dB 상승했으며, 특히 고배율(×12, ×24)에서 기존 LIIF·LTE·CiaoSR 등을 능가한다. 시각적 결과에서도 미세한 텍스처와 경계가 더 선명하게 복원되는 것을 확인할 수 있다.
이러한 설계는 다중 스케일 정보의 명시적 공유, 전역 비선형 관계의 효율적 모델링, 백본 독립적인 플러그‑인 구조라는 세 가지 장점을 제공한다. 다만, 계층형 인코딩 레벨 수와 어텐션 헤드 수에 따라 메모리·연산 비용이 증가할 수 있으며, 실시간 초해상도 적용을 위해서는 경량화가 필요하다. 향후 연구에서는 동적 레벨 선택, 하드웨어 친화적 어텐션 변형, 그리고 비디오 초해상도와 같은 시계열 데이터에의 확장이 기대된다.
댓글 및 학술 토론
Loading comments...
의견 남기기