소프트웨어 신뢰성 공학 50년 역사
초록
본 논문은 1967년 최초 소프트웨어 신뢰성 모델 등장부터 2018년까지의 50년간 SRE(Software Reliability Engineering)의 이론·모델·실천을 연대기적으로 조명한다. 전산 이전의 신뢰성 개념, 초기 모델과 주요 인물 인터뷰, 1980‑1990년대의 성숙 단계, 애자일·스마트폰 시대의 새로운 도전과 향후 연구 과제를 포괄적으로 정리한다.
상세 분석
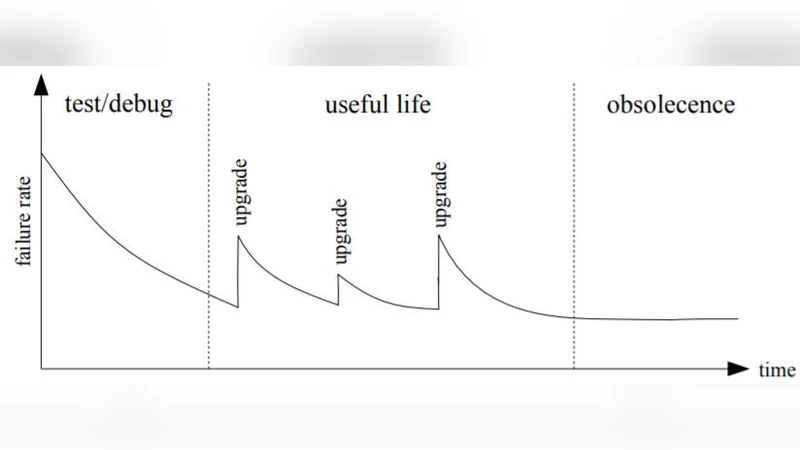
논문은 소프트웨어 신뢰성 공학을 “전산 이전의 전자·기계 신뢰성 연구”와 연결시켜, 1950‑대의 군사·우주 프로젝트에서 사용된 고장률(Failure Rate) 개념이 소프트웨어에 적용될 수 있는 이론적 토대를 제공했음을 강조한다. 1967년 제시된 최초의 소프트웨어 신뢰성 모델은 “고장 간격(Inter‑Failure Time) 분포”를 이용해 소프트웨어 고장 발생을 확률적으로 기술했으며, 이는 이후 Jelinski‑Moranda, Musa‑Basic, Goel‑Okumoto 등 다수 모델의 전신이 된다. 논문은 이들 모델이 가정하는 “고장 독립성”, “고정 결함 수” 등 기본 가정이 실제 개발 환경에서 어떻게 위배되는지를 인터뷰 자료와 함께 비판적으로 분석한다.
1980‑대에는 신뢰성 성장 모델이 등장하면서 테스트 단계에서 누적 결함 수를 추정하고, 신뢰성 목표(Reliability Goal)를 정량화하는 방법론이 정립되었다. 특히 NASA와 DoD 프로젝트에서 적용된 “신뢰성 할당(Reliability Allocation)” 기법은 시스템 수준에서 소프트웨어 신뢰성을 관리하는 최초 사례로, 논문은 해당 사례를 상세히 재구성한다.
1990‑대와 2000‑대 초반에는 소프트웨어 공학과 통합된 SRE가 등장한다. 애자일 방법론이 보편화되면서 “스프린트 별 신뢰성 측정”, “지속적 통합(CI) 환경에서의 고장 데이터 수집” 등이 새로운 실천 지표로 부상했으며, 논문은 이를 선구적으로 도입한 몇몇 기업(예: IBM, Microsoft)의 인터뷰를 통해 실무적 난관과 해결책을 조명한다.
최근 스마트폰, 사물인터넷(IoT), 클라우드 네이티브 서비스 등에서 요구되는 “실시간 신뢰성 보증”은 전통적인 고장‑시간 모델만으로는 설명이 어려워, 머신러닝 기반 고장 예측, 베이지안 업데이트, 포스트-디플로이먼트 모니터링 등 복합 기법이 도입되고 있다. 논문은 이러한 최신 접근법을 기존 이론과 비교 분석하며, 데이터 품질, 프라이버시, 모델 검증 비용 등 새로운 제약조건을 제시한다.
마지막으로, 저자는 “신뢰성 엔지니어링은 이제 ‘예측’이 아니라 ‘증명(proof)’ 단계에 와 있다”는 통찰을 제시하고, 형식 검증(formal verification)과 신뢰성 모델링을 결합한 하이브리드 프레임워크, 그리고 인간‑기계 상호작용(HMI)에서의 신뢰성 평가 필요성을 강조한다. 전체적으로 논문은 50년간 SRE가 이론적 탐구에서 실무 적용, 그리고 현재의 데이터‑드리븐 시대까지 어떻게 진화했는지를 풍부한 일인칭 인터뷰와 문헌 메타‑분석을 통해 설득력 있게 서술한다.
댓글 및 학술 토론
Loading comments...
의견 남기기