할인 거울 하강 동역학을 이용한 단조 콤팩트 게임 수렴 분석
연속시간 할인 거울 하강(DMD) 동역학을 제안하고, 강볼록 혹은 Legendre 정규화자를 이용한 두 종류의 미러 맵을 구성한다. 이 동역학은 단조(엄격히 단조는 아님)인 음의 의사기울기 게임에서 점근 수렴을 보이며, 정규화자가 강볼록일 경우 부족 단조(히포‑단조) 게임에서도 수렴한다. 수렴 증명은 Bregman 발산을 Lyapunov 함수로 활용한다.
저자: Bolin Gao, Lacra Pavel
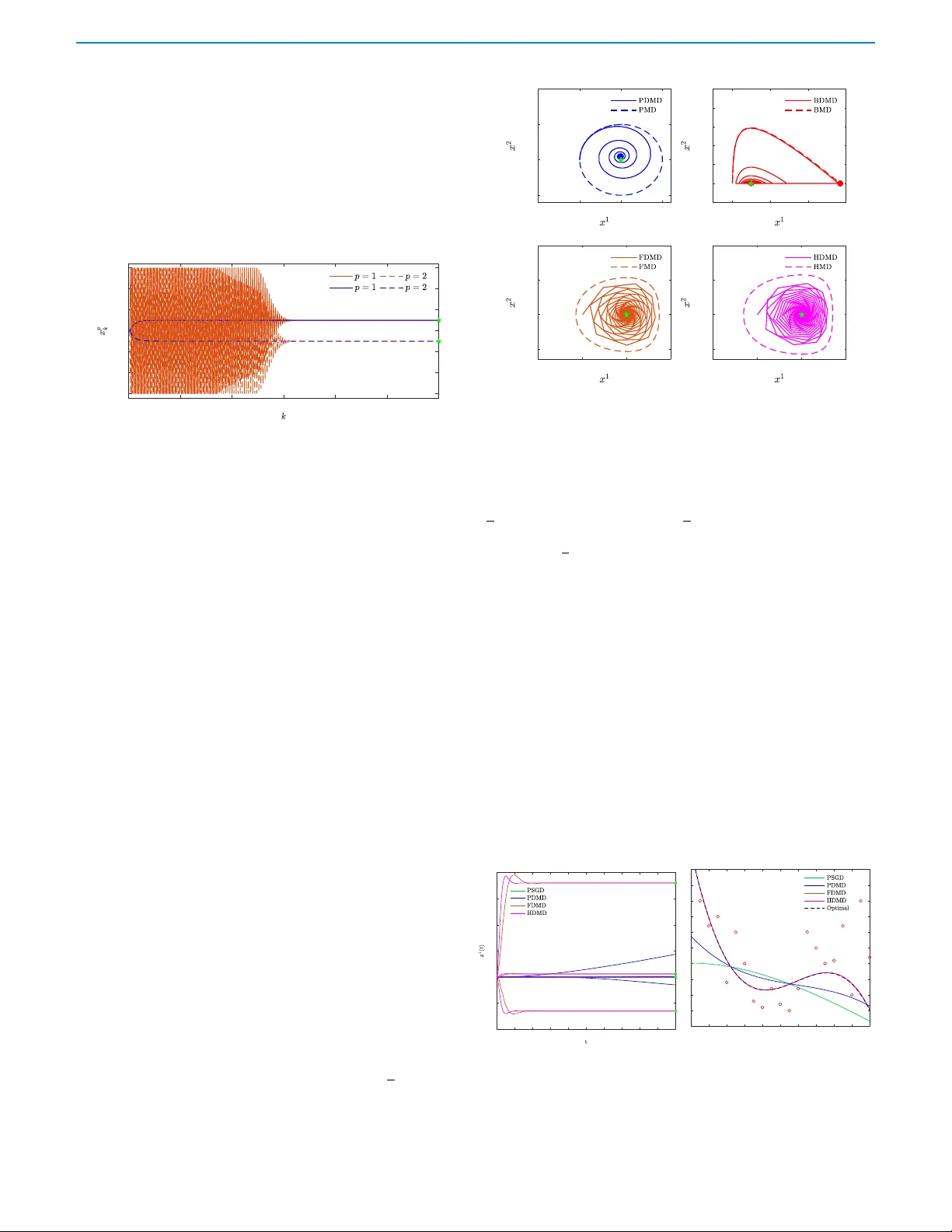
논문은 연속시간 연속 커널 콤팩트 게임에서 Nash 균형을 찾기 위한 새로운 동역학인 할인 거울 하강(DMD) 을 제안한다. 서론에서는 Rosen 의 초기 작업을 언급하며, 기존 연구가 주로 강단조(강하게 단조) 의사기울기 조건 하에서 연속시간 gradient 흐름이나 이산시간 proximal 알고리즘을 다루었고, 비강단조 경우에는 연속시간 방법이 거의 없었다는 점을 지적한다. 이어서 거울 하강(MD) 알고리즘의 배경을 소개하고, MD 가 primal‑dual 구조를 갖으며 Fenchel 쌍과 Bregman 발산을 핵심 도구로 사용한다는 점을 설명한다.
문제 설정에서는 N 명의 플레이어가 전략 집합 Ωp ⊂ ℝⁿᵖ 에서 행동하고, 각 플레이어의 효용 Up 은 xₚ에 대해 연속적이고 concave 하며 미분 가능하다고 가정한다. 게임의 의사기울기 U(x) = (∇ₓₚ Up(x))ₚ 로 정의하고, Nash 균형은 변분 부등식 VI(Ω,−U) 로 표현된다. 의사기울기 −U 가 단조, 엄격히 단조, η‑강단조, μ‑히포‑단조 등 다양한 모노톤성 조건을 정의한다.
동역학 설계에서는 각 플레이어가 자신의 부분 기울기 up 를 보조 변수 zp 로 매핑하고, zp 를 업데이트하는 연속시간 시스템 ˙zp = F(zp,up) 를 도입한다. 미러 맵 Cp 은 정규화 함수 ϑp 의 공액함수 ψp* 의 gradient 로 정의되며, xₚ = Cp(zp) 로 전략을 결정한다. 기존 MD 는 ˙zp = γ up 로 단순 적분했지만, DMD 는 ˙zp = γ(−zp+up) 로 지수 할인 적분을 적용한다. 이는 연속시간에서의 할인 효과를 도입해 진동을 억제하고 수렴을 촉진한다. 전체 시스템은 stacked 형태로 ˙z = γ(−z+U(x)), x = C(z) 로 표현된다.
정규화자 설계에서는 두 가지 클래스를 고려한다. 첫 번째는 ρ‑강볼록 정규화자 ϑp 로, 이는 ψp = γϑp 가 전역적으로 강볼록하고, ψp* 가 전역 미분 가능하며, Cₚ = ∇ψp* 가 (γρ)⁻¹‑Lipschitz, γρ‑코코에르시브, 그리고 전사성을 가진다. 두 번째는 Legendre 정규화자이며, 이는 본질적으로 매끄럽고 엄격히 볼록한 특성을 갖는다. Legendre 경우에도 ψp* 가 전역 미분 가능하고 Cₚ 가 단조이며, 정의역 전체에 걸쳐 전사성을 유지한다.
수렴 분석에서는 Bregman 발산 Dψp*(zp, zₚ*) 를 Lyapunov 함수로 선택한다. DMD 의 동역학을 대입하면 d/dt Dψp*(zp, zₚ*) ≤ −γ‖Cₚ(zp)−Cₚ(zₚ*)‖² + ⟨−U(x)+U(x*), C(z)−C(z*)⟩ 이 된다. 여기서 −U 가 단조이면 두 번째 항이 비양수가 되므로 전체 미분이 비양수가 되어 Lyapunov 함수가 감소한다. 따라서 z(t) 가 z* 로 수렴하고, C(z(t)) 가 Nash 균형 x* 로 수렴한다. 강볼록 정규화자 경우에는 추가적인 코코에르시브 상수 γρ 가 μ‑히포‑단조 상황에서도 충분히 큰 경우(γρ > μ) 수렴을 보장한다.
예시 섹션에서는 (i) ϑ(x)=½‖x‖² 로 얻는 전통적인 pseudo‑gradient 흐름, (ii) 엔트로피 정규화 ϑ(x)=∑xi log xi 로 얻는 확률 simplex 상의 DMD, (iii) Tikhonov 정규화와 연속시간 대응을 보이는 ϑ(x)=½‖x‖² + λ‖x‖² 형태 등을 제시한다. 각 예시는 해당 정규화자가 강볼록 혹은 Legendre 조건을 만족함을 확인하고, 수렴 정리를 적용한다.
수치 실험에서는 두 종류의 게임을 시뮬레이션한다. 첫 번째는 2‑플레이어 zero‑sum 게임으로, DMD 가 주기적 사이클을 빠르게 소멸시키고 균형에 수렴한다. 두 번째는 3‑플레이어 전력 시장 모델로, 히포‑단조 특성을 갖지만 강볼록 정규화자를 사용한 DMD 가 안정적으로 균형을 찾는다. 실험 결과는 이론적 수렴 속도와 일치하며, 할인 파라미터 γ 와 정규화 강도 ρ 가 수렴 속도에 미치는 영향을 시각화한다.
결론에서는 DMD 가 연속시간 게임 학습에서 비강단조 환경을 다룰 수 있는 강력한 도구임을 강조하고, 향후 연구 방향으로 비정상적(비볼록) 정규화자, 비정형 전략 집합, 그리고 분산 구현을 제시한다. 전체적으로 이 논문은 정규화자 선택에 따라 동역학의 수렴 특성을 체계적으로 연결하고, 할인 메커니즘을 통해 기존 방법이 갖지 못한 견고성을 제공한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기