패시비티 기반 강화학습과 고차원 학습의 다중 에이전트 게임 수렴 분석
본 논문은 연속시간 지수 할인 강화학습(EXP‑D‑RL) 알고리즘을 패시비티 이론에 기반하여 분석하고, 부정적 보상이 단조(monotone)인 다중 에이전트 유한 게임에서 Nash 분포(로그잇 균형)로의 수렴을 증명한다. 또한, 패시비티를 활용한 고차원(2차) 학습 구조를 제안하여 수렴 속도를 향상시키고, 1차 스킴이 수렴하지 못하는 경우에도 수렴하도록 설계한다. 이론적 결과는 다양한 게임(잠재 게임, 제로섬, RPS 등)과 시뮬레이션을 통해 …
저자: Bolin Gao, Lacra Pavel
1. 서론
다중 에이전트 강화학습은 각 에이전트가 다른 에이전트의 행동에 의존하는 보상을 반복적으로 관찰하며 전략을 조정하는 과정을 다룬다. 기존 연구는 주로 이산시간 확률 과정과 ODE 근사법을 이용해 잠재 게임이나 제로섬 게임에서의 수렴을 분석했으며, 연속시간 모델은 상대적으로 적게 다루었다. 본 논문은 연속시간 지수 할인 강화학습(EXP‑D‑RL) 방식을 출발점으로, 패시비티 이론을 활용해 보다 일반적인 ‘단조 게임(monotone games)’에서도 Nash 분포(로그잇 균형)로의 수렴을 증명한다. 또한, 고차원(2차) 학습 구조를 설계해 수렴 속도 향상 및 기존 1차 스킴이 실패하는 경우를 보완한다.
2. 배경 이론
논문은 먼저 convex optimization과 monotone 연산자 이론을 정리한다. 함수 f 가 convex이면 그 gradient ∇f 는 단조이며, 강단조(μ‑strongly monotone)와 코코시브(β‑cocoercive) 개념을 소개한다. 이어 equilibrium‑independent passivity(EIP)와 output‑strict EIP(OSEIP)의 정의를 제시하고, 시스템 Σ: \dot z = f(z,u), y = h(z,u) 가 저장함수 V(z) 를 통해 입력‑출력 간 에너지 관계 \dot V ≤ (y−y*)ᵀ(u−u*) 또는 \dot V ≤ (y−y*)ᵀ(u−u*)−β‖y−y*‖² 를 만족하면 EIP/OSEIP라 정의한다. 이러한 특성은 정적 비선형 맵에 대해 단조성·코코시브와 동등함을 언급한다.
3. 게임 모델
유한 행동 집합을 가진 N 명의 플레이어와 보상 함수 U_p 을 정의하고, 혼합 전략 x_p ∈ Δ_p 을 사용한다. Nash 균형은 변분 부등식 −(x−x*)ᵀU(x*) ≥ 0 또는 변분 부등식 VI(−U,Δ) 로 표현된다. ‘단조 게임’은 −U 가 단조(즉, (−U(x) + U(x′))ᵀ(x−x′) ≥ 0)인 경우이며, 이는 기존의 잠재 게임, 제로섬 게임, 그리고 RPS와 같은 진화 게임을 포함한다.
4. EXP‑D‑RL 알고리즘
각 플레이어 p 는 점수 z_p ∈ ℝ^{n_p} 를 \dot z_{p,i}=γ( U_{p,i}(x)−z_{p,i}) 로 업데이트한다. 점수는 소프트맥스(soft‑max) 함수 σ_p(z_p)=exp(z_p/τ)/∑exp(z_p/τ) 를 통해 확률 전략 x_p=σ_p(z_p) 로 변환된다. 여기서 τ 는 온도 파라미터이며, τ→0 이면 최적 행동을 거의 확정적으로 선택하고, τ→∞ 이면 균등 무작위 선택이 된다. 이 스키마는 연속시간 버전의 exponential‑weight 알고리즘이며, Q‑learning의 연속시간 근사와도 일치한다.
5. 수렴 분석 (1차 스킴)
점수 동역학을 ‘전달‑피드백’ 형태로 재구성한다. 전방 시스템은 \dot z = −γz + γU(x) 이며, 출력은 y = σ(z) 이다. 이 시스템은 저장함수 V(z)=∑ x_i log(x_i/σ_i(z)) (즉, Bregman 발산)로 OSEIP를 만족한다. 게임 측면에서 −U 가 단조이면, U 는 코코시브이며, 소프트맥스의 코코시브성(β=τ)과 결합해 전체 폐루프가 OSEIP를 유지한다. 따라서 Lyapunov 함수 V 의 시간 미분이 비양수이며, 유일한 평형점인 Nash 분포에 전역 수렴한다. 특히, τ 가 충분히 크면 ‘하이포‑단조’(코코시브가 음수인) 게임에서도 수렴을 보장한다.
6. 고차원 학습 설계
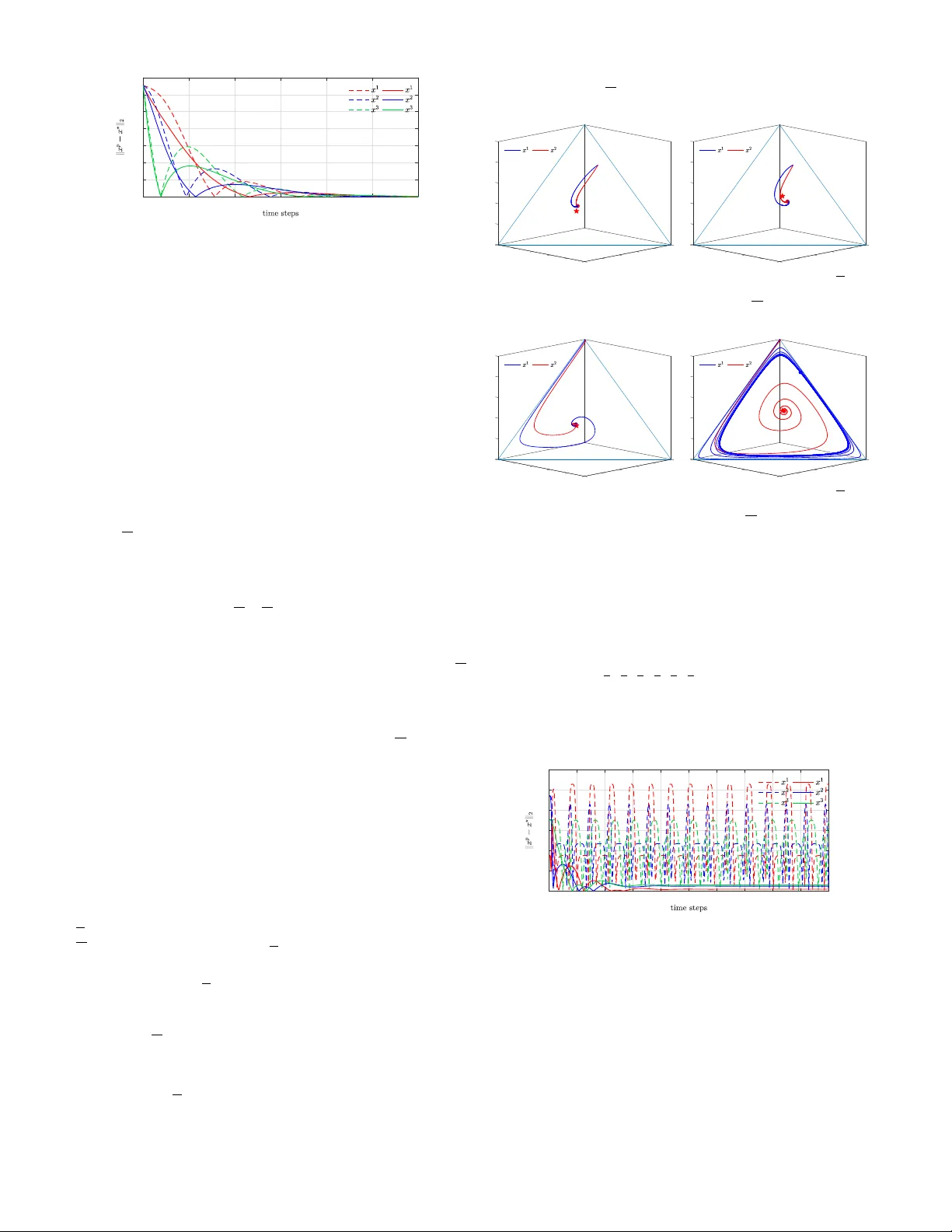
1차 스킴에 보조 상태 ξ 를 도입해 \dot ξ = Aξ + Bσ(z), u = Cξ 와 같은 LTI 시스템을 피드백에 삽입한다. 여기서 (A,B,C) 는 최소 실현이며 A 는 Hurwitz이다. 이 LTI 블록이 자체적으로 OSEIP(또는 최소한 패시비티)를 만족하도록 설계하면, 전체 고차원 시스템도 동일한 단조 게임 클래스에서 OSEIP를 유지한다. 저자는 구체적으로 A=−αI, B=I, C=I (α>0)인 2차 스킴을 제시하고, 시뮬레이션을 통해 1차 대비 수렴 속도가 2~3배 빨라짐을 확인한다. 또한, ‘불안정 RPS’와 ‘Shapley 게임’ 같은 하이포‑단조 사례에서도 2차 스킴이 수렴하는 반면 1차 스킴은 발산한다.
7. 인구 게임과의 연결
패시비티 기반 해석은 인구 게임의 ‘δ‑패시비티’와도 연관된다. 저자는 ‘전달‑피드백’ 구조가 인구 게임의 복제자 동역학과 유사함을 보이며, 기존 결과와 일관된 수렴 조건을 제공한다.
8. 실험 및 시뮬레이션
다양한 게임(잠재 게임, 제로섬, RPS, Shapley)에서 1차와 2차 스킴을 비교한다. 온도 τ 와 학습률 γ 의 파라미터 스위프를 수행해 수렴 영역을 시각화한다. 결과는 2차 스킴이 더 넓은 파라미터 영역에서 안정적으로 수렴하고, 수렴 속도도 현저히 빠름을 보여준다.
9. 결론
패시비티 이론을 활용해 연속시간 EXP‑D‑RL의 수렴을 일반적인 단조 게임까지 확장했으며, 고차원 피드백 설계를 통해 수렴 속도와 안정성을 동시에 향상시켰다. 이 접근법은 equilibrium‑independent 특성을 이용해 정확한 Nash 균형을 몰라도 수렴을 보장한다는 점에서 강화학습 이론에 새로운 시각을 제공한다. 향후 연구는 이산시간 구현, 비정상적(비‑단조) 게임에 대한 적응형 고차원 설계, 그리고 실제 네트워크 시스템에의 적용을 제안한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기