안전한 강화학습을 위한 NMPC 기반 확률정책 기법
본 논문은 안전 제약을 하드 제약 형태로 직접 정책에 포함시키는 방법을 제시한다. 확률적 정책 그래디언트와 actor‑critic 구조를 활용하면서, 정책을 강인 비선형 모델예측제어(NMPC) 최적화 문제의 해로 근사한다. 선형 강인 MPC를 중심으로 안전 집합 정의, 샘플링 효율성, 내부점법 기반 파라메트릭 NLP 활용, 학습 과정 전반에 걸친 안전 유지 기법을 상세히 설명한다.
저자: Sebastien Gros, Mario Zanon
논문은 안전 강화 학습을 목표로, 정책을 강인 비선형 모델예측제어(NMPC) 최적화 문제의 해로 근사하는 프레임워크를 제시한다. 서론에서는 기존 딥러닝 기반 정책이 안전 검증과 제약 적용에 한계가 있음을 지적하고, 직접 정책 파라미터 θ를 최적화 문제에 삽입함으로써 하드 제약을 구현할 수 있음을 소개한다.
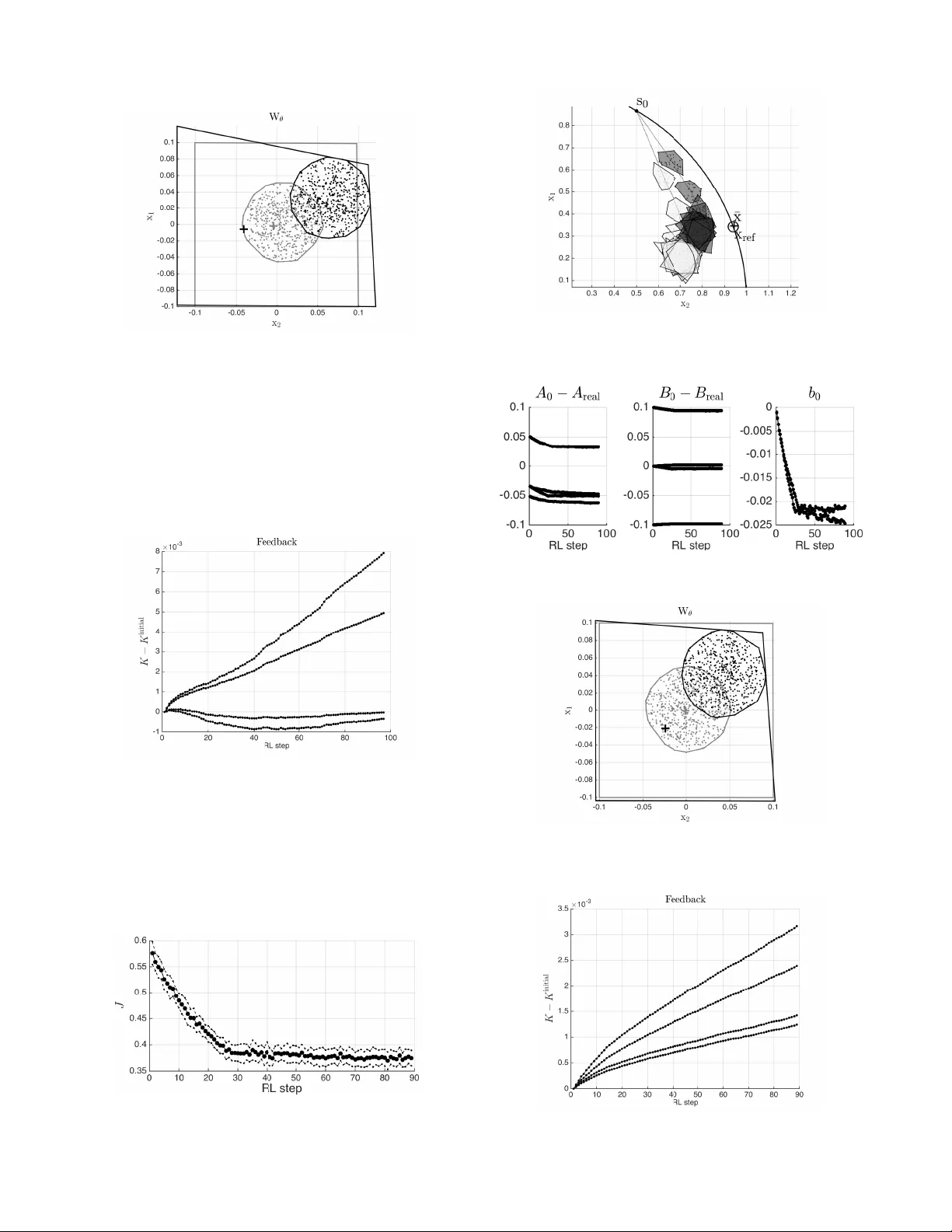
배경 섹션에서는 마코프 결정 과정(MDP)과 확률적 정책 πθ(a|s)의 정의, 기대 비용 J(π)와 정책 그래디언트 ∇θJ(πθ)의 표준 형태(12‑13식)를 정리한다. 특히, 안전 집합 S(s)⊂ℝⁿᵃ를 상태‑입력 제약 h_s(s,a)≤0 로 정의하고, 안전 입력은 모든 미래 궤적이 안전 제약을 만족하는 경우로 규정한다. 이를 위해 튜브 기반, 다항 혼합, 타원체/다각형 근사 등 기존 검증 기법을 언급한다.
안전 확률 정책 파트에서는 정책의 지원이 안전 집합에 완전히 포함되도록 하는 요구(19)를 제시한다. 그러나 지원을 제한하면 샘플링과 로그밀도 평가가 복잡해지는 문제를 지적하고, 두 가지 직관적 방법(단순 교란, 재샘플링)과 그 비효율성을 논한다.
핵심 기여는 ‘교란 파라메트릭 NLP’ 접근이다. 기존 NMPC 최적화(21‑22식)에 작은 확률적 교란 변수를 추가하고, 이를 내부점법(primal‑dual)으로 동시에 해결한다. 파라메트릭 NLP 이론을 이용해 최적해의 민감도와 라그랑주 승수를 정확히 계산함으로써 ∇θlogπθ를 저비용으로 얻는다.
선형 강인 MPC 사례에서는 분산 집합 X⁺(s,a)를 선형 모델 F₀(s,a,θ)와 폴리토프 W로 외삽(27식)하고, 시나리오 트리의 각 모델을 F_i=F₀+W_i 로 구성한다. 선형 정책 π_s는 피드백 K를 포함한 형태(29식)이며, 이를 통해 모든 단계에서 상태 집합 X_k가 다각형의 볼록 껍질에 포함됨을 보인다(30식). 안전 제약은 h≤0 로 직접 NMPC에 삽입되고, 터미널 제약은 강인 불변 집합을 이용해 장기 안전을 보장한다.
데이터 기반 안전 검증(31식)은 관측된 전이 집합 D를 이용해 파라미터 θ가 안전한지 여부를 다각형 W 안에 속하는지 검사한다. 이는 파라메트릭 제약식으로 변환되어 학습 중 실시간으로 적용 가능하다.
알고리즘 1은 재샘플링 절차를 명시한다. 상태 s에서 안전 정책 π_dθ(s) 로부터 샘플 a를 뽑고, a∈S(s) 가 될 때까지 반복한다. 이는 안전성을 보장하지만 샘플링 비용이 증가할 수 있다.
계산 효율성을 위해 내부점법 기반 파라메트릭 NLP 솔버를 활용하고, 민감도와 라그랑주 승수를 재활용해 정책 그래디언트 계산을 가속한다. 또한, 학습 과정 전반에 걸친 안전 유지 기법을 제시하여, 파라미터 업데이트 시 안전 제약을 위반하지 않도록 보장한다.
마지막으로 시뮬레이션 예시를 통해 제안된 프레임워크가 안전 제약을 만족하면서도 정책 성능을 점진적으로 향상시킴을 보여준다. 결론에서는 비선형 NMPC 확장 가능성, 안전 집합 구축의 실질적 방법론, 그리고 제한된 데이터에 대한 확률적 안전 보장의 한계를 언급하며 향후 연구 방향을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기