안전 강화 강화 학습을 위한 NMPC 기반 결정론적 정책 기울기
본 논문은 안전 제약을 하드 제약식으로 명시한 강인 선형 MPC를 정책 함수로 활용하고, 이를 결정론적 정책 그래디언트(Deterministic Policy Gradient, DPG)와 결합해 안전성을 유지하면서 학습하는 방법을 제시한다. 연속 입력 공간에서 탐색이 제약을 받는 문제를 분석하고, 탐색 분포의 왜곡을 보정하는 최적화 기반 기법과 내부점법을 이용한 효율적인 구현 방안을 제시한다. 또한, 학습 과정 전반에 걸쳐 안전을 보장하는 절차를…
저자: Sebastien Gros, Mario Zanon
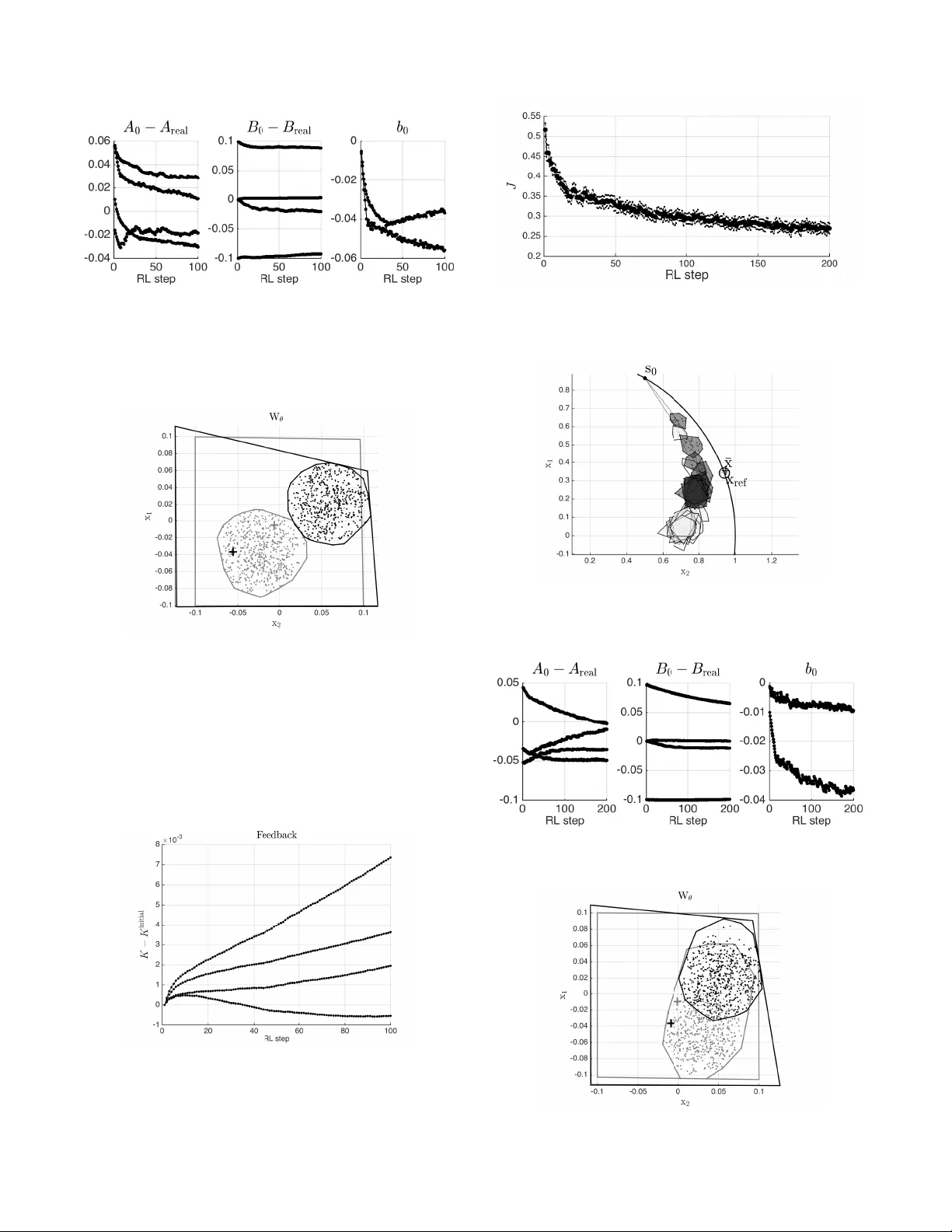
본 논문은 안전 제약을 하드 제약식으로 명시하고, 이를 만족하는 정책을 직접 최적화 문제 형태로 구현함으로써 결정론적 정책 그래디언트(Deterministic Policy Gradient, DPG) 기반 강화학습에 안전성을 부여하는 방법론을 제시한다. 먼저, 강화학습의 기본 개념인 마코프 결정 과정(MDP)과 정책 그래디언트 이론을 간략히 정리하고, 안전 제약이 존재할 때 탐색(Exploration) 과정이 어떻게 왜곡되는지를 분석한다. 기존 DPG는 정책 파라미터 θ에 대한 그래디언트를 ∇θJ(πθ)=Eπθ
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기