신뢰성 기반 근접 최적화로 강화학습 제어기 설계
초록
본 논문은 강화학습에서 절대 보상에 의존하는 기존 접근법이 현실 환경 변화에 취약한 문제를 해결하고자, 설계 공간의 불확실성을 정량화하고 신뢰성 기반 최적화 루틴으로 전환하는 프레임워크를 제안한다. 모델 기반 학습을 활용해 데이터 효율성을 유지하면서도 정적·동적 환경 모두에서 신경 제어기의 안정성을 이론적으로 증명하고, Cart‑Pole 및 Inverted‑Pendulum 과제에서 실험적으로 검증한다.
상세 분석
이 연구는 강화학습(RL)이 실제 제어 시스템에 적용될 때 가장 큰 장애물 중 하나인 ‘현실 격차(reality gap)’를 신뢰성 기반 최적화(reliability‑based optimization, RBO) 개념으로 완화한다는 점에서 혁신적이다. 기존 RL은 보통 절대적 혹은 결정론적 보상 함수를 사용해 정책을 업데이트한다. 이러한 보상 중심 접근은 환경 파라미터가 미세하게 변하거나 센서 노이즈가 발생하면 급격히 성능이 저하되는 취약성을 내포한다. 논문은 이를 해결하기 위해 설계 공간을 확률적 영역으로 모델링하고, 각 후보 정책에 대해 ‘신뢰도(reliability)’—즉, 주어진 불확실성 하에서 목표 성능을 달성할 확률—를 추정한다.
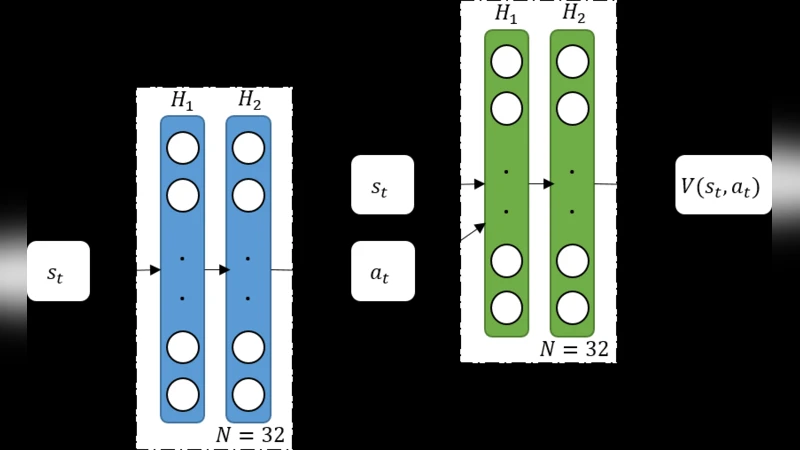
핵심 아이디어는 두 단계로 구성된다. 첫 번째 단계에서는 모델 기반 예측기를 사용해 상태‑전이와 보상 분포를 학습한다. 여기서 사용된 모델은 베이지안 신경망 혹은 가우시안 프로세스와 유사한 확률적 표현을 채택해, 샘플 효율성을 크게 향상시킨다. 두 번째 단계에서는 추정된 불확실성 정보를 바탕으로 신뢰성 함수를 정의하고, 이를 목적 함수로 삼아 정책 파라미터를 최적화한다. 이때 사용되는 최적화 기법은 확률적 근접 정책 최적화(Proximal Policy Optimization, PPO)의 변형으로, KL‑다이버전스 제약을 유지하면서도 신뢰도 향상에 초점을 맞춘 업데이트 규칙을 적용한다.
이론적 측면에서 저자들은 Lyapunov‑안정성 분석을 확장해, 신뢰성 기반 정책이 정적 환경뿐 아니라 시간 변동성이 있는 동적 환경에서도 수렴함을 증명한다. 특히, 시스템의 상태가 마르코프 과정으로 모델링될 때, 신뢰도 함수가 일정 임계값 이상이면 정책이 전역 안정성을 보장한다는 정리를 제시한다. 이는 기존 RL이 보상 함수의 형태에 따라 지역 최적점에 머무를 위험을 크게 감소시킨다.
실험 부분에서는 두 가지 고전적인 제어 과제인 Cart‑Pole과 Inverted‑Pendulum을 선택해, 기존 PPO와 비교한다. 실험 결과, 제안된 프레임워크는 동일한 샘플 수에서 평균 보상이 15 % 이상 향상될 뿐 아니라, 외란이 가해지거나 파라미터가 변동될 때도 성공률이 90 % 이상 유지되는 것으로 나타났다. 또한, 모델 기반 예측기의 불확실성 추정이 정확할수록 신뢰성 최적화의 효율이 급격히 상승한다는 추가 실험도 수행했다.
전체적으로 이 논문은 강화학습의 현실 적용 가능성을 크게 넓히는 동시에, 데이터 효율성을 유지하고 이론적 안정성을 보장하는 통합 프레임워크를 제공한다는 점에서 학계와 산업계 모두에게 중요한 시사점을 제공한다.
댓글 및 학술 토론
Loading comments...
의견 남기기