비협력 다중에이전트 학습에서 비균일 학습률의 수렴 분석
연속 게임에서 각 에이전트가 자신의 비용 함수에 대한 그라디언트를 이용해 업데이트하는 알고리즘을 고려한다. 결정론적 경우와 무편향 추정기를 사용하는 확률적 경우에 대해, 최소·최대 특이값을 이용한 유한시간 수렴 보장을 제시한다. 특히 학습률이 에이전트마다 다를 때 벡터장 왜곡이 발생해 수렴 속도와 수렴 영역의 형태가 변한다는 점을 이론과 실험으로 입증한다.
저자: Benjamin Chasnov, Lillian J. Ratliff, Eric Mazumdar
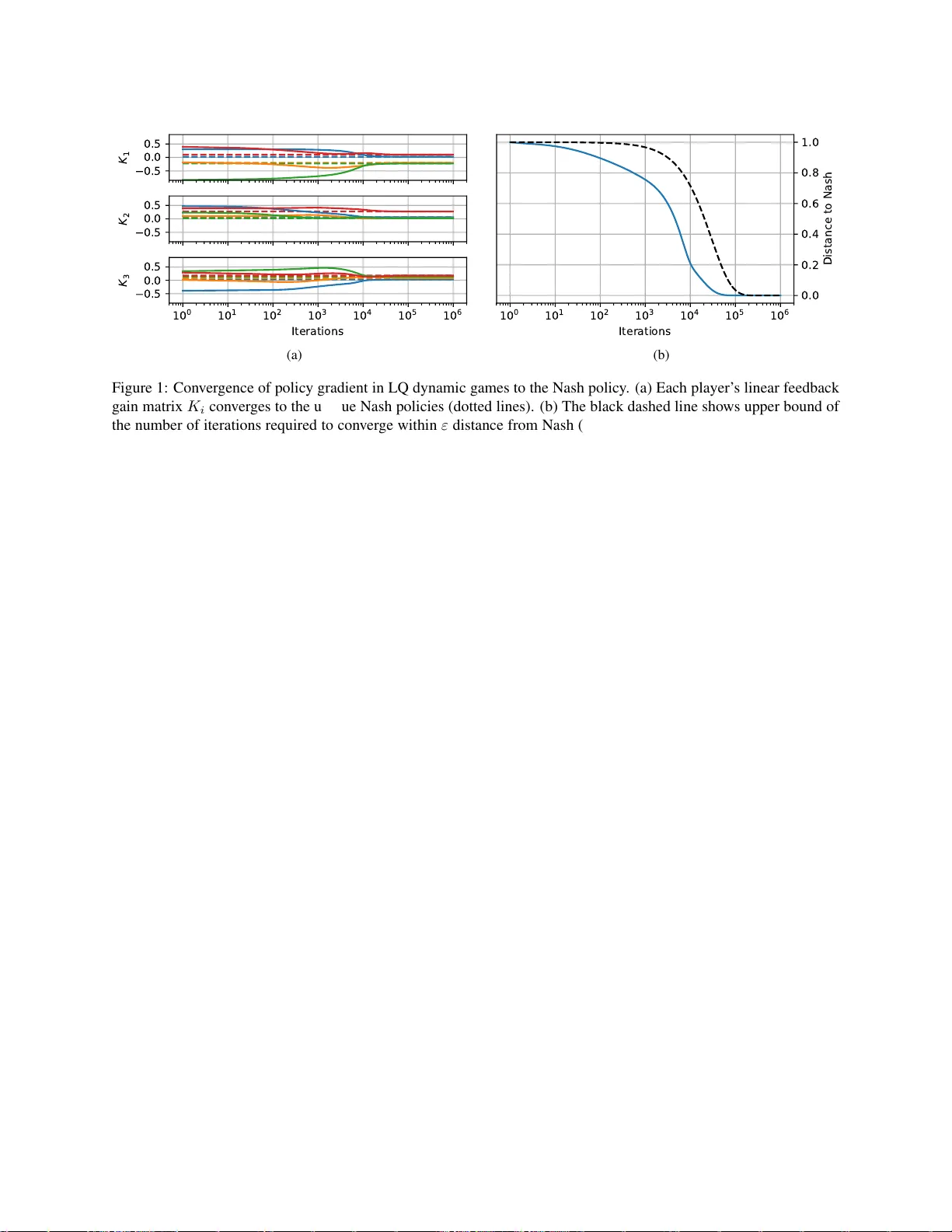
이 논문은 비협력적인 다중 에이전트 환경에서 그라디언트 기반 학습 알고리즘의 수렴 특성을 체계적으로 분석한다. 먼저, 연속적인 n‑플레이어 게임을 정의하고, 각 플레이어 i가 비용 함수 f_i(x_i,x_{−i})에 대해 자신의 행동 x_i를 업데이트하는 일반적인 형태 x_{i,k+1}=x_{i,k}−γ_i g_i(x_{i,k},x_{−i,k})를 제시한다. 여기서 g_i는 정확한 그라디언트 D_i f_i이거나, 무편향 추정치 d D_i f_i이며, E
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기