다중오믹스 네트워크로 밝힌 심혈관질환과 우울증 연관성
초록
본 연구는 청년 핀란드 코호트(YFS)의 단면 데이터를 활용해, 대사체와 지질체 두 오믹스 레이어를 연결하는 ‘multipartite projection’ 방법을 제안한다. 상호정보량(MI) 기반의 비선형 상관관계를 이용해 CVD와 우울증 관련 변수들을 중간 바이오마커와 연결하고, 이를 층별(weighted multilayer) 네트워크로 투영한다. 결과적으로 크레아티닌, 발린, HDL‑관련 인지질, LDL‑트리글리세리드, 아포지단백 B 등 여러 대사·지질 바이오마커가 두 질환 간 매개역할을 할 가능성을 제시했으며, 성별과 BMI가 주요 위험인자로 부각되었다.
상세 분석
이 논문은 기존의 ‘human disease network’ 접근법이 단일 오믹스(주로 유전자)와 선형 상관에 의존한다는 한계를 지적하고, 이를 극복하기 위해 세 가지 핵심 개선점을 도입한다. 첫째, 메타볼로믹스와 리피도믹스 등 다중 오믹스 레이어를 동시에 포함할 수 있는 확장 가능한 프레임워크를 설계하였다. 둘째, 변수 간 비선형 의존성을 포착할 수 있는 비모수적 정보이론 지표인 상호정보량(MI)을 상관 척도로 사용함으로써 Pearson 상관이 놓칠 수 있는 복합적인 관계를 탐지한다. 셋째, 단순히 공유 바이오마커의 개수를 세는 것이 아니라, 각 바이오마커와 질환 변수 사이의 MI 값을 평균화해 가중치를 부여함으로써 ‘weighted’ 연결 강도를 정의한다.
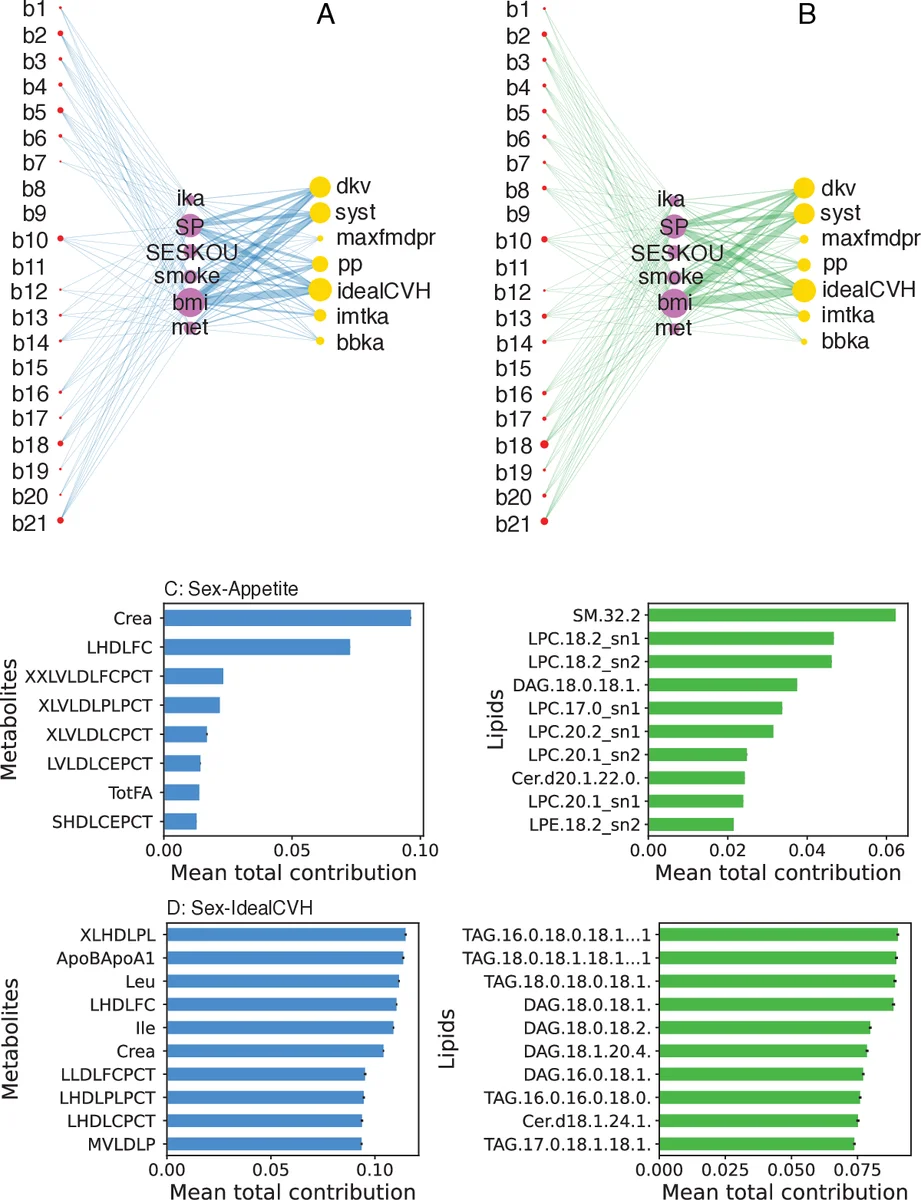
구체적으로, 연구자는 먼저 결측치를 랜덤 샘플링으로 보완하고, 연속형 변수를 Sturges 규칙에 기반한 분위수 구간으로 이산화하였다. 이렇게 전처리된 1,686명의 데이터에서 584개의 변수(17개의 CVD 지표, 6개의 우울증 증상, 6개의 위험인자, 228개의 대사체, 437개의 지질체)를 사용해 모든 쌍에 대해 MI를 계산하고, 부트스트랩 기반 p‑값 검정(α=0.01)으로 유의한 연결만을 추출했다. 중복 및 고상관 변수는 사전 필터링을 통해 제거함으로써 네트워크의 과잉 연결을 방지하였다.
다음 단계인 ‘multipartite projection’에서는 두 질환 변수 X_i, X_j가 동일한 중간 바이오마커 Y_k와 모두 비제로 MI 연결을 가질 때, (f(X_i,Y_k)+f(X_j,Y_k))/2 를 합산해 가중 연결 점수 w(X_i,X_j)를 산출한다. 이 정의는 세 가지 제안된 방식 중 가장 성능이 좋았으며, 각 레이어(대사체 vs 지질체)별로 별도의 네트워크 층을 형성한다. 또한, 각 바이오마커의 전체 기여도 CON(Y_k)를 정의해 CVD‑우울증 전체 연관성에 대한 상대적 중요성을 정량화하였다. 위험인자(성별, BMI 등)의 경우, 특정 질환 변수와의 투영 점수를 전체 위험인자 점수의 비율로 나타내는 r(Z_i,X_j)를 도입해 위험인자의 상대적 영향력을 평가하였다.
분석 결과, 크레아티닌, 발린, HDL‑관련 인지질, 소형 LDL‑트리글리세리드, 아포지단백 B 등은 CVD와 우울증 사이의 높은 CON 값을 보였으며, 특정 스핑고미린, 포스파티딜콜린, 트리아실글리세리드, 디아실글리세리드도 유의미한 매개 역할을 하는 것으로 나타났다. 위험인자 분석에서는 남성보다 여성에서, 그리고 BMI가 높은 집단에서 더 강한 네트워크 연결이 관찰되어, 이들이 공통 위험요인으로 작용함을 시사한다.
방법론적 강점은 (1) 다중 오믹스 레이어를 자연스럽게 통합할 수 있는 구조, (2) 비선형 관계를 포착하는 MI 기반 상관, (3) 가중치 부여를 통한 정교한 연결 강도 측정이다. 그러나 몇 가지 제한점도 존재한다. 첫째, MI 계산 시 이산화 과정에서 정보 손실 가능성이 있다. 둘째, 단일 코호트(Young Finns Study)와 횡단적 설계에 기반하므로 인과관계를 확정하기 어렵다. 셋째, 무작위 샘플링 기반 결측치 보완이 데이터 왜곡을 초래할 여지가 있다. 향후 연구에서는 longitudinal 데이터와 외부 코호트 검증, 그리고 연속형 MI 추정 방법(예: k‑nearest neighbor) 도입이 필요하다.
전반적으로, 이 논문은 복합 질환 간의 메커니즘을 다중 오믹스 네트워크와 정보이론적 투영을 통해 정량화하는 새로운 분석 파이프라인을 제시함으로써, 시스템 생물학 및 정밀의학 분야에 중요한 방법론적 기여를 한다.
댓글 및 학술 토론
Loading comments...
의견 남기기