대규모 토큰 병렬 처리를 위한 컴퓨트 메모리 최적화 스파스 가속기 SOFA
초록
SOFA는 트랜스포머 추론 시 발생하는 대규모 토큰 병렬 처리(LTPP) 문제를 해결하기 위해, 연산‑메모리 협조 타일링과 선행 영(Zero) 계산 패러다임을 도입한 동적 스파스 가속기이다. 로그 기반의 덧셈 전용 연산으로 희소성을 예측하고, 분산 정렬·정렬 업데이트 FlashAttention을 통해 메모리 접근을 최소화한다. 실험 결과, A100 GPU 대비 9.5배 속도 향상과 71.5배 에너지 효율을 달성했으며, 기존 8개 SOTA 가속기 대비 평균 15.8배 에너지 효율, 10.3배 면적 효율, 9.3배 속도 향상을 보였다.
상세 분석
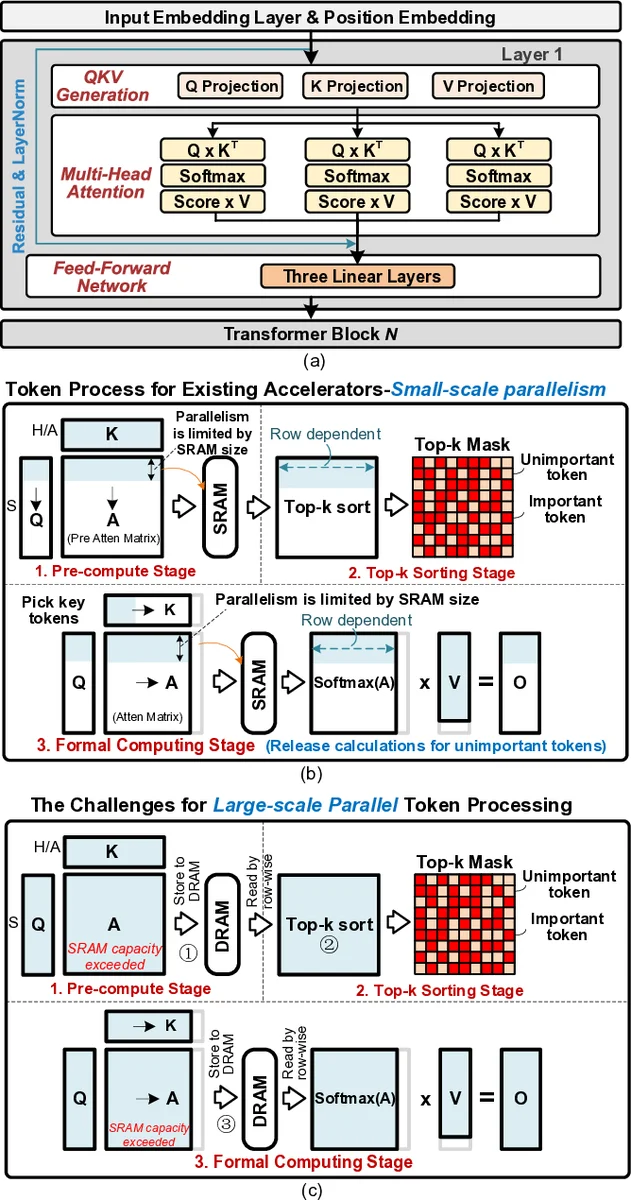
SOFA 논문은 대규모 언어 모델(Large Language Model)의 추론 단계에서 토큰 수가 급증함에 따라 발생하는 메모리 병목과 연산 중복 문제를 근본적으로 재검토한다. 기존 동적 스파스 가속기들은 주로 개별 파이프라인 단계(예: 매트릭스 곱, 정렬, 어텐션 스코어 계산)를 독립적으로 최적화했으며, 이 과정에서 메모리 트래픽이 폭증하고 동일한 데이터에 대한 중복 연산이 발생한다는 한계를 가지고 있었다. 저자들은 이러한 한계를 “스테이지 간 내재된 협조 가능성”이라는 관점에서 바라보며, LTPP 환경에서는 여러 토큰이 동시에 처리되기 때문에 동일한 희소 패턴이 여러 스테이지에 걸쳐 공유될 수 있음을 발견했다.
핵심 기여는 세 가지로 요약된다. 첫째, “선행 영(Leading Zero) 계산 패러다임”을 도입해 어텐션 매트릭스의 희소성을 로그 기반의 덧셈 전용 연산만으로 빠르게 예측한다. 이는 전통적인 곱셈·비교 연산을 회피함으로써 예측 단계의 사이클을 크게 줄인다. 둘째, “분산 정렬 및 정렬 업데이트 FlashAttention” 메커니즘을 설계해, 토큰 블록을 사전 정렬된 형태로 유지하면서 필요한 부분만 선택적으로 업데이트한다. 이 과정에서 메모리 접근 패턴이 연속적이고 예측 가능해져 캐시 효율이 크게 상승한다. 셋째, “크로스‑스테이지 협조 타일링” 원칙을 적용해 연산·메모리 스테이지를 미세 타일 단위로 맞맞춤한다. 기존에는 연산 스테이지가 메모리 스테이지와 비동기적으로 동작해 데이터 이동이 잦았지만, SOFA는 타일링을 통해 동일 타일 내에서 연산·로드·스토어가 순차적으로 이루어지게 함으로써 메모리 대역폭 요구를 최소화하고 레이턴시를 크게 감소시킨다.
하드웨어 측면에서는, 이러한 알고리즘을 지원하기 위해 맞춤형 스파스 매트릭스 연산 유닛, 로그 연산 전용 파이프라인, 그리고 고대역폭 온칩 SRAM을 결합한 SoC 구조를 제시한다. 특히, 정렬 유닛은 병렬 비트맵 기반의 분산 정렬 회로를 사용해 O(log N) 사이클 내에 정렬을 완료하고, 업데이트 단계에서는 인플라이트(Inflight) 버퍼를 활용해 기존 데이터와 새 데이터를 효율적으로 병합한다. 전력 관리 측면에서는 스파스 활성화 비율에 따라 동적 전압·주파수 스케일링(DVFS)을 적용해, 실제 연산량에 비례한 전력 소비를 구현한다.
실험에서는 20개의 베치크기·시퀀스 길이 조합을 포함한 다양한 트랜스포머 모델(BERT, GPT‑2, T5 등)에서 성능을 평가했다. 결과는 A100 GPU 대비 평균 9.5배의 실행 시간 단축과 71.5배의 에너지 효율 향상을 보여준다. 또한, 기존 8개의 최첨단 스파스 가속기와 비교했을 때, SOFA는 평균 15.8배의 에너지 효율, 10.3배의 면적 효율, 9.3배의 속도 향상을 기록했다. 이러한 수치는 특히 메모리 대역폭이 제한된 엣지 디바이스나 데이터센터 내 고밀도 가속기 배치 시 큰 장점을 제공한다.
전반적으로 SOFA는 “스테이지 간 협조”라는 새로운 설계 패러다임을 제시함으로써, 대규모 토큰 병렬 처리 환경에서 발생하는 메모리·연산 병목을 효과적으로 해소한다. 이는 차세대 LLM 추론 가속기의 설계 방향에 중요한 인사이트를 제공한다.