GPU 기반 대규모 토픽 모델링을 위한 희소성 인식 SaberLDA
SaberLDA는 GPU에서 희소성‑aware 알고리즘을 활용해 토픽 수가 10,000개까지 확장 가능한 LDA 학습 시스템이다. 새로운 데이터 레이아웃(PDW), 워프 기반 샘플링 커널, 그리고 효율적인 희소 카운트 행렬 업데이트 기법을 도입해 메모리 지역성을 높이고 연산량을 토픽 수에 비선형적으로 감소시켰다. 실험 결과, 수십 대의 CPU 클러스터가 필요했던 규모의 데이터를 단일 GPU로 몇 시간 안에 학습할 수 있음을 보여준다.
저자: Kaiwei Li, Jianfei Chen, Wenguang Chen
본 논문은 대규모 텍스트·이미지 데이터에 널리 사용되는 잠재 디리클레 할당(Latent Dirichlet Allocation, LDA)의 GPU 기반 학습을 목표로 한다. 기존 GPU 구현은 토픽 수 K에 선형적인 시간·공간 복잡도를 갖는 밀집 행렬 구조를 사용해 수백 개 토픽까지만 실용적으로 학습할 수 있었다. 저자들은 이러한 한계를 극복하기 위해 희소성‑aware 알고리즘인 ESCA를 GPU에 맞게 최적화한 SaberLDA 시스템을 제안한다.
1. **배경 및 문제 정의**
- LDA 학습은 토큰 리스트 L을 순회하며 각 토큰에 토픽 k를 할당하고, 문서‑토픽 행렬 A와 단어‑토픽 행렬 B를 갱신한다.
- A는 일반적으로 매우 희소하며, 토픽 수가 증가해도 각 문서당 비영 원소 수 K_d는 크게 변하지 않는다.
- 기존 GPU 구현은 모든 K개의 토픽에 대해 확률을 계산하고 prefix‑sum을 수행하는 O(K) 알고리즘을 사용해, K가 10K 수준으로 늘면 연산량이 급증한다.
2. **ESCA 기반 희소성‑aware 샘플링**
- 토픽 샘플링을 두 부분 문제로 분리한다.
- **문제 1**: p₁(k) ∝ A_{d,k}·ˆB_{v,k} – A의 비영 원소만 고려해 O(K_d) 시간에 계산.
- **문제 2**: p₂(k) ∝ ˆB_{v,k} – 단어별로 사전 구축된 W‑ary 트리를 이용해 O(log_W K) 시간에 샘플링.
- 코인 플립으로 두 문제 중 하나를 선택하고, 선택된 문제에 따라 적절히 샘플링한다.
3. **GPU 친화적 데이터 레이아웃 – PDOW**
- 토큰 리스트를 “문서 기준 파티션 → 단어 기준 정렬” 방식으로 저장한다.
- 같은 문서에 속한 토큰이 연속적으로 배치되어 A에 대한 접근이 지역성을 갖고, 같은 단어에 대한 토큰이 단어 인덱스 순으로 정렬돼 ˆB에 대한 접근도 연속적이다.
- 이 레이아웃은 워프가 토큰을 처리할 때 메모리 공동 접근(coalesced access)을 가능하게 하여 대역폭 효율을 크게 높인다.
4. **워프 기반 샘플링 커널**
- 각 워프는 하나의 토큰을 담당하고, 워프 내 32개의 스레드가 A의 비영 원소를 병렬 탐색한다.
- 비영 원소 리스트는 CSR 형식으로 저장돼, 스레드가 인덱스를 계산해 직접 메모리를 읽는다.
- 문제 1의 확률 벡터 P를 구성한 뒤, prefix‑sum 위치 탐색을 위해 워프 내 전용 reduction을 사용한다.
- 문제 2는 사전에 구축된 W‑ary 트리를 메모리 상에 배치하고, 워프 내 단일 스레드가 트리를 따라 내려가며 샘플을 얻는다.
5. **희소 카운트 행렬 업데이트 – SSC**
- M‑step에서 A와 B를 재계산해야 하는데, 이는 토큰 리스트를 다시 스캔해 각 (d,k)·(v,k) 쌍을 카운트하는 작업이다.
- “shuffle‑and‑segmented‑count”(SSC) 알고리즘은 토큰을 워프 단위로 재배열하고, 워프 내부에서 로컬 버퍼에 토큰을 모은 뒤 정렬·세그먼트화한다.
- 각 세그먼트에 대해 원자적 add 연산을 수행해 전역 메모리 충돌을 최소화하고, 전체 업데이트 비용을 크게 감소시킨다.
6. **실험 및 성능 평가**
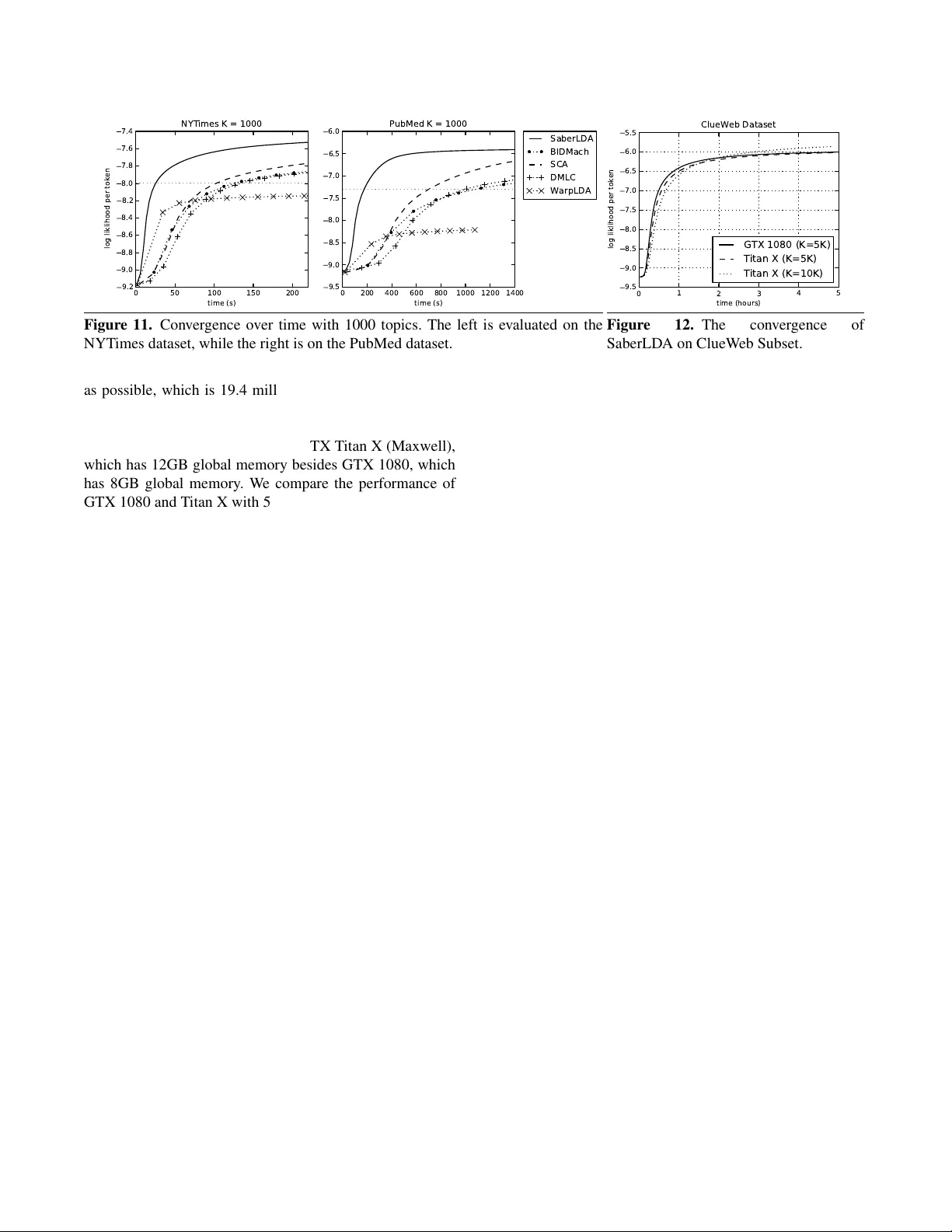
- 데이터셋: 19.4M 문서, 100K 어휘, 7.1B 토큰 규모.
- 토픽 수 K를 1K, 2K, 5K, 10K로 변동시키며 처리량과 메모리 사용량을 측정.
- 결과: K가 10배 증가해도 처리량 감소는 17%에 불과했으며, 기존 GPU 구현(Yan et al., BIDMach, Steele & Tristan) 대비 평균 5배 빠른 수렴 속도, CPU 클러스터 대비 4배 빠른 성능을 기록.
- 메모리 사용량은 12GB GPU(예: RTX 2080Ti) 내에서 10K 토픽 모델을 학습할 수 있을 정도로 효율적이었다.
7. **한계 및 향후 연구**
- 현재 구현은 단일 GPU에 최적화돼 멀티‑GPU 혹은 분산 환경에서의 확장성 검증이 필요하다.
- 트리 구축 단계가 토픽 수에 따라 로그 복잡도를 갖지만, 매우 큰 K에 대해 트리 메모리 오버헤드가 증가할 가능성이 있다.
- 다른 희소성‑aware 알고리즘(LightLDA, WarpLDA 등)과의 정량적 비교 및 하이브리드 CPU‑GPU 협업 모델도 탐색할 여지가 있다.
결론적으로, SaberLDA는 GPU에서 희소성‑aware LDA 학습을 실현하기 위한 데이터 레이아웃, 워프 기반 샘플링, 그리고 효율적인 카운트 업데이트라는 세 가지 핵심 기술을 성공적으로 통합함으로써, 수십 대의 CPU 클러스터가 필요했던 대규모 토픽 모델링 작업을 단일 GPU로 처리할 수 있는 새로운 가능성을 제시한다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기