고정 흐름 사이클 모델을 통한 시퀀싱 길이 분포 분석
본 논문은 차세대 시퀀싱(NGS) 기술 중 시퀀싱 바이 신테시스(SBS)의 흐름 사이클 수가 주어졌을 때, 읽히는 서열 길이의 확률 분포를 정확히 구하는 고정 흐름 사이클 모델(FFCM)을 제안한다. 완전한 염기 삽입과 불완전 삽입 두 경우를 모두 다루며, 생성함수(GF)를 이용해 평균·분산의 닫힌 형태식을 도출하고, 시뮬레이션으로 검증한다.
저자: Yong Kong
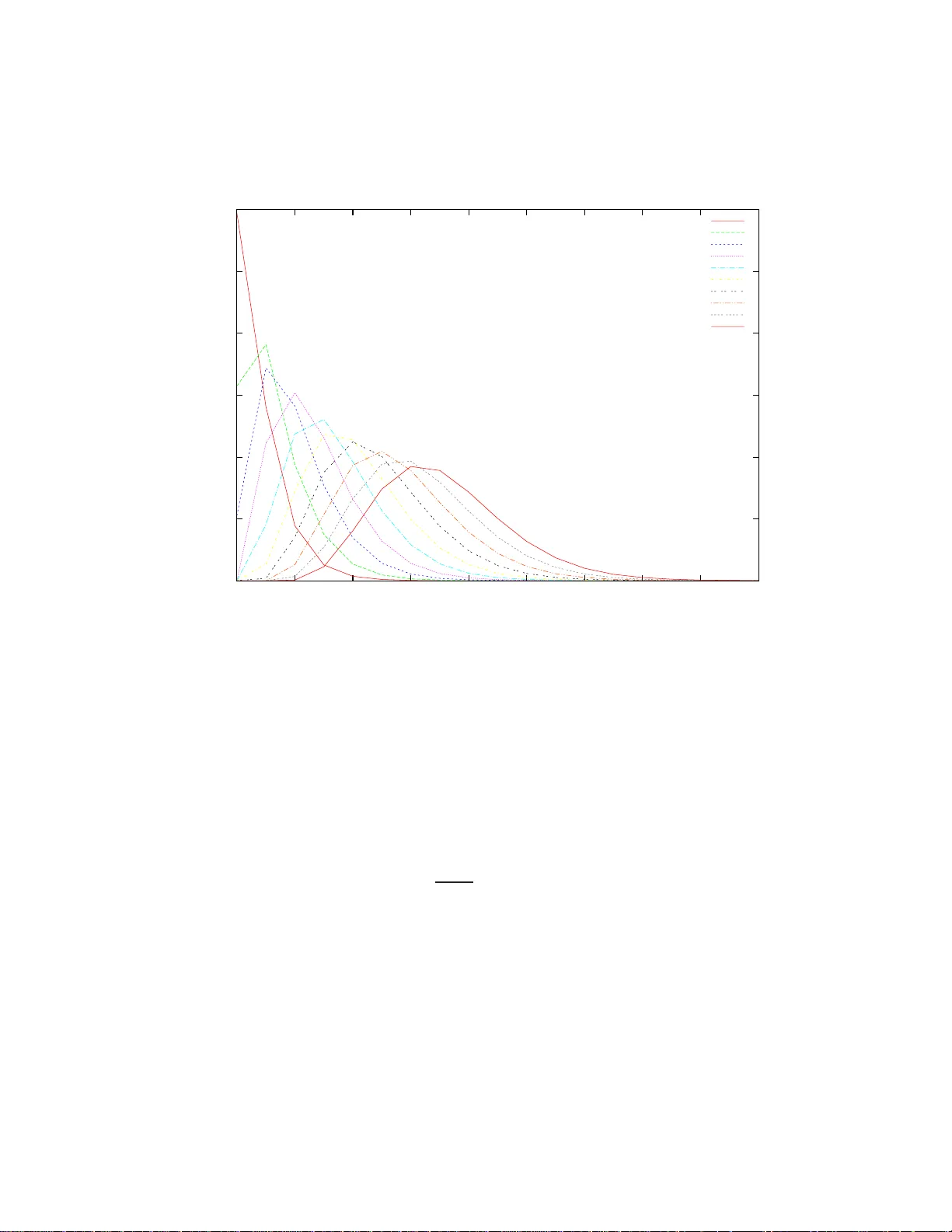
본 논문은 차세대 DNA 시퀀싱 기술인 시퀀싱 바이 신테시스(SBS)의 핵심적인 통계 문제, 즉 주어진 흐름 사이클 수(f) 안에서 실제 읽히는 서열 길이(n)의 확률 분포를 정확히 구하는 모델을 개발한다. 서론에서는 SBS가 네 종류의 뉴클레오타이드(A, C, G, T)를 미리 정해진 순서대로 주입하고, 해당 사이클에서 템플릿에 상보적인 염기가 있으면 합성이 일어나 신호가 검출된다는 기본 원리를 설명한다. 이 과정에서 두 가지 주요 플랫폼, 즉 대량 시퀀싱(bulk SBS)과 단일 분자 시퀀싱(SMS)을 구분한다. 대량 시퀀싱에서는 클론화 단계 후 동기화 손실을 방지하기 위해 각 사이클마다 완전한 삽입을 강제한다(완전 삽입). 반면 SMS에서는 클론화가 없고, 반응 속도를 조절해 삽입을 부분적으로 지연시킬 수 있어, 같은 흐름 사이클에서도 0~다수의 염기가 삽입될 확률이 존재한다(불완전 삽입).
이전 연구에서는 고정 서열 길이 모델(FSLM)을 사용해 길이 n이 주어졌을 때 흐름 사이클 f의 분포 L_i(n,f)를 구했으며, 이는 흐름 사이클을 정규화해야 하는 근사적 방법에 의존했다. 이러한 한계를 극복하고자 저자들은 고정 흐름 사이클 모델(FFCM)을 제안한다. FFCM에서는 서열 길이를 무한히 긴 가상의 템플릿으로 가정하고, 실제로 f개의 흐름 사이클 안에 합성되는 염기 수 n을 확률적으로 모델링한다. 이를 위해 각 염기 i에 대해 삽입 지연 확률 α_i^{(j)}(j=0,1,…)을 정의하고, 염기 i가 템플릿에 상보적일 때 j번째 사이클에 삽입될 확률을 나타낸다. α_i^{(0)}=1, α_i^{(j>0)}=0인 경우가 완전 삽입이며, 일반적인 경우는 α_i^{(j)}가 여러 값으로 분포한다.
수학적 전개는 다음과 같다. 염기 i의 삽입 확률을 포함한 생성함수 g_i(x)=p_i∑_{j≥0}α_i^{(j)}x^j을 정의한다. 여기서 p_i는 템플릿에서 염기 i가 등장할 기본 확률이며, ∑_i p_i=1이다. 흐름 사이클 f가 주어졌을 때, 마지막으로 삽입된 염기가 i이고 전체 길이가 n인 확률을 P_i(n,f)라 두고, 전체 확률 P(n,f)=∑_i P_i(n,f)로 정의한다. 재귀 관계를 생성함수 형태로 변환하면, P_i(n,f)의 이중 생성함수 G_i(z,x)=∑_{n,f}P_i(n,f)z^n x^f는 다음과 같은 닫힌 식을 갖는다.
G_i(z,x)=\frac{z g_i(x)}{1-∑_{j∈{a,b,c,d}} g_j(x) x^{Δ_{ij}}}
여기서 Δ_{ij}는 흐름 사이클 순서에 따른 인덱스 차이를 나타낸다(예: a→b는 1 사이클 이동). 이 식을 전개하면 각 f에 대한 P_i(n,f)의 계수를 직접 추출할 수 있다. 평균 μ_f와 분산 σ_f^2는 G_i의 1차·2차 모멘트를 이용해 구한다. 완전 삽입 경우, g_i(x)=p_i이므로 식이 크게 단순화되어
μ_f = f·(p_a+p_b+p_c+p_d)/4 = f·(1/4) (모든 p_i가 동일한 경우)
σ_f^2 = f·Var_i(p_i) (각 염기의 삽입 횟수 변동)
와 같은 형태가 된다. 일반적인 불완전 삽입 경우에는 식 (19)~(21)에서 g_i(x)의 고차항까지 포함한 복합식이 도출되며, 이는 삽입 지연 확률 α_i^{(j)}가 평균·분산에 미치는 영향을 정량화한다. 특히 평균은 각 염기의 평균 삽입 횟수 m_i=∑_j j·α_i^{(j)}에 비례하고, 분산은 삽입 지연의 분산 τ_i^2와 독립적인 흐름 사이클 간의 합산 효과를 포함한다.
이론적 결과를 검증하기 위해 저자들은 C 언어 기반 시뮬레이터를 구현하였다. 시뮬레이션은 무한히 긴 템플릿을 가정하고, 각 흐름 사이클마다 확률적으로 염기를 삽입하는 과정을 반복한다. 시뮬레이션 결과는 분석식으로부터 얻은 평균·분산과 PMF가 거의 일치함을 보여, 모델의 정확성을 입증한다.
논문의 마지막 부분에서는 FFCM이 갖는 실용적 의미를 논한다. 첫째, 흐름 사이클 수가 실험 설계에서 고정된 경우(예: Illumina의 100 사이클 시퀀싱) 직접적인 읽기 길이 분포를 예측할 수 있어, 데이터량 및 비용 추정에 활용 가능하다. 둘째, 불완전 삽입을 모델링함으로써 SMS 플랫폼에서 발생하는 homopolymer 오류와 신호 감쇠 현상을 정량화할 수 있다. 셋째, 평균·분산의 닫힌 형태식은 새로운 화학 시약이나 반응 조건을 최적화할 때 목표하는 읽기 길이와 오류율을 수학적으로 설계하는 기반이 된다. 향후 연구에서는 이 모델을 기반으로 오류 정정 알고리즘, 흐름 사이클 최적화, 그리고 다중 템플릿 혼합 상황에 대한 확장 모델을 개발할 수 있을 것으로 기대된다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기