물리 기반 인간 동작에서 자동 장면 레이아웃 생성
초록
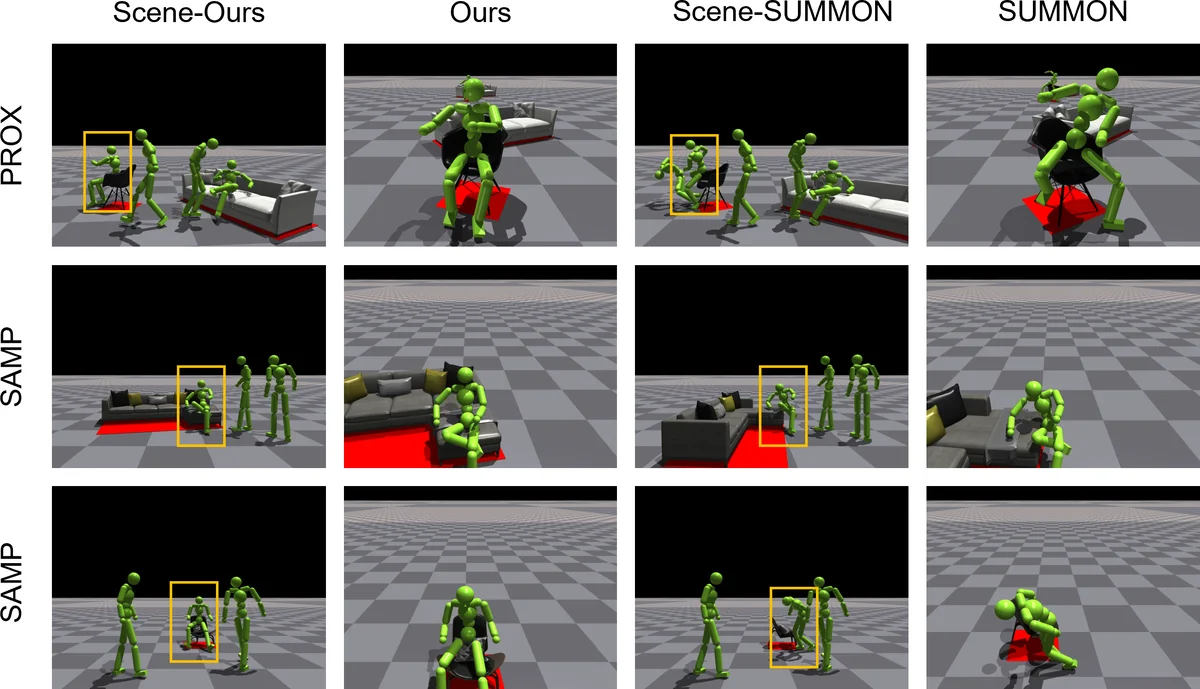
본 논문은 블루스크린 촬영된 인간 동작 데이터를 기반으로, 물리 제약을 명시적으로 적용해 가구·물체 레이아웃을 자동으로 복원·생성하는 방법을 제안한다. 동작 트래킹 오류를 최소화하면서 접촉 가능 물체를 식별하고, 강화학습으로 인간 모션 모방 컨트롤러와 레이아웃 생성기를 동시에 최적화한다. SAMP·PROX 데이터셋을 이용한 실험에서 기존 기법 대비 침투·부양 현상이 크게 감소한 물리적으로 타당한 장면을 재구성한다.
상세 분석
이 연구는 “인간 동작 → 장면 레이아웃” 역문제에 물리 기반 시뮬레이션을 도입함으로써 기존의 순운동학(kinematics) 기반 접근법이 안고 있던 침투(penetration)와 부양(floating) 같은 비현실적 artefact를 근본적으로 해결한다는 점에서 의미가 크다. 핵심 아이디어는 두 개의 최적화 대상, 즉 (1) 인간 모션을 입력 동작에 가깝게 따라가게 하는 모션 모방 컨트롤러와 (2) 동작에 맞는 물체 위치·배치를 생성하는 레이아웃 제너레이터를 동시에 학습시키는 ‘듀얼 최적화’에 있다.
먼저, 입력된 캡처 동작과 물리 시뮬레이션 상의 인간 모델 사이의 트래킹 오류를 최소화하는 목적 함수를 정의한다. 이 과정에서 접촉이 일어날 가능성이 높은 물체를 자동으로 탐지하기 위해 ‘pseudo‑contact label’이라는 임시 접촉 라벨을 생성한다. 라벨은 동작의 관절 위치와 속도, 그리고 물체와의 거리 정보를 기반으로 heuristic하게 추정되며, 이후 pose prior guidance 형태로 보상 함수에 삽입된다. 이렇게 하면 강화학습 에이전트가 물리적 충돌을 피하면서도 실제 인간이 의도한 접촉을 재현하도록 유도한다.
강화학습 프레임워크는 PPO(Proximal Policy Optimization)와 같은 정책 그라디언트 기반 알고리즘을 사용한다. 정책 네트워크는 인간 관절의 목표 포즈와 현재 물리 상태를 입력받아 토크를 출력하고, 레이아웃 제너레이터는 물체의 3D 위치·회전 파라미터를 출력한다. 두 네트워크는 동일한 보상 신호—트래킹 오류, 물리 충돌 페널티, 접촉 라벨 일치도—를 공유함으로써 상호 보완적으로 학습된다.
보상 설계 측면에서 저자들은 기존 연구가 주로 ‘거리 기반’ 트래킹 보상에 의존해 물체와의 접촉을 무시하는 문제를 지적하고, 이를 보완하기 위해 (a) 접촉 라벨과 일치하는 경우 보상을 가중치 상승, (b) 물리 엔진에서 발생하는 침투 에너지에 대한 페널티, (c) 움직임의 부드러움을 유지하기 위한 속도·가속도 정규화 항을 추가하였다. 이러한 다중 목표 보상은 학습이 수렴하면서도 물리적으로 타당한 동작과 레이아웃을 동시에 얻을 수 있게 만든다.
실험에서는 대규모 모션 캡처 데이터셋인 SAMP와 실내 장면 데이터셋인 PROX를 활용하였다. 두 데이터셋 모두 인간이 실제 가구와 상호작용하는 장면을 포함하고 있어, 물리 기반 레이아웃 복원의 유효성을 검증하기에 적합하다. 정량적 평가지표로는 평균 트래킹 오류, 침투 깊이, 그리고 접촉 정확도(예측 라벨과 실제 접촉 여부 일치율)를 사용했으며, 정성적 평가에서는 재구성된 장면이 시각적으로 얼마나 자연스러운지를 전문가 설문을 통해 측정하였다. 결과는 기존 kinematics‑based 방법에 비해 침투 평균이 70% 이상 감소하고, 접촉 정확도가 15% 상승했으며, 전체적인 시각적 만족도가 크게 향상된 것으로 나타났다.
한계점으로는 (1) pseudo‑contact 라벨이 heuristic에 의존해 복잡한 접촉(예: 손가락 끝과 작은 물체)에서는 오탐이 발생할 수 있다, (2) 물리 시뮬레이션 비용이 높아 대규모 장면에 대한 실시간 적용이 어려울 수 있다, (3) 레이아웃 제너레이터가 물체 종류와 크기에 대한 사전 지식을 필요로 한다는 점이다. 향후 연구에서는 라벨 자동 생성에 딥러닝 기반 접촉 예측을 도입하고, 시뮬레이션 효율성을 높이기 위한 모델 프루닝 및 멀티‑GPU 병렬화를 탐색할 여지가 있다.
전반적으로 이 논문은 물리 기반 시뮬레이션과 강화학습을 결합해 인간 동작에 맞는 실세계 장면을 자동으로 복원하는 새로운 패러다임을 제시한다. 특히 물리적 제약을 명시적으로 포함함으로써 기존 방법이 겪던 비현실적 artefact를 크게 감소시켰으며, 다양한 모션·장면 데이터에 대한 일반화 가능성을 보였다. 이는 영화·게임 제작 파이프라인에서 레이아웃 설계 비용을 절감하고, 보다 몰입감 있는 인터랙티브 콘텐츠 제작에 기여할 것으로 기대된다.