강화학습 기반 합리성 시뮬레이션이 거시경제에 미치는 영향
초록
본 논문은 전통적인 거시경제 에이전트 기반 모델(ABM)에 다중 에이전트 강화학습(RL)을 도입해 ‘완전 합리적’ 기업 에이전트를 구현한다. RL 에이전트는 이익을 최대화하는 정책을 스스로 학습하며, 시장 경쟁 정도와 합리성 비율에 따라 세 가지 전략을 자동으로 구분한다. 합리적 에이전트 비중이 높아질수록 총생산량은 증가하지만, 전략에 따라 경제 변동성도 달라진다.
상세 분석
이 연구는 기존의 ‘제한된 합리성(bounded rationality)’을 전제로 한 거시경제 ABM에 비해 두드러진 두 가지 혁신을 제시한다. 첫째, 기업(C‑firms)의 가격·생산량 결정 규칙을 고정된 휴리스틱에서 강화학습 기반 정책으로 전환함으로써, 에이전트가 환경에 대한 피드백을 통해 직접 최적화된 행동을 학습하도록 설계하였다. 여기서 사용된 Q‑learning은 비동기식 ε‑greedy 방식을 적용했으며, 상태는 로그 변환된 가격·재고 차이, 행동은 가격·생산량의 로그 변동으로 이산화하였다. 이러한 설계는 경제학적 의미(가격 대비 시장 평균, 재고 과잉·부족)와 머신러닝 구현상의 효율성을 동시에 만족한다.
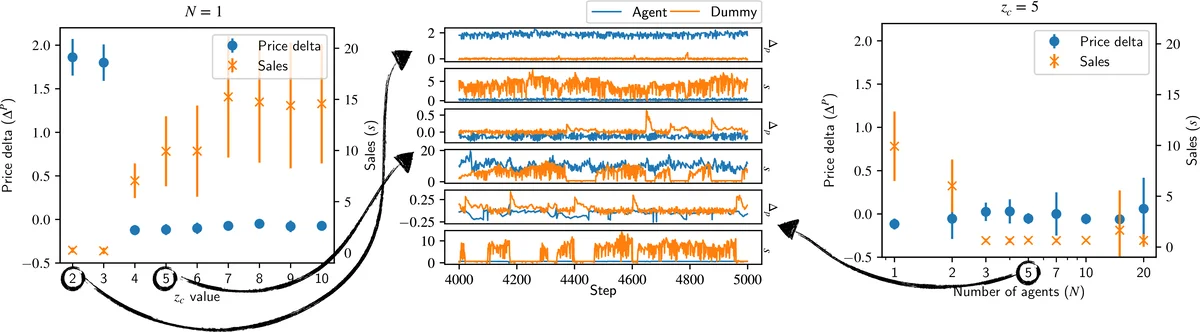
둘째, 다중 에이전트 환경에서 각 기업이 독립적인 정책을 학습하도록 함으로써, 에이전트 간 직접적인 통신 없이도 전략적 군집화가 자연스럽게 발생한다는 점이다. 실험 결과, RL 기업은 (1) 가격을 평균 이하로 낮추고 생산량을 늘려 시장 점유율을 확대하는 ‘가격 경쟁 전략’, (2) 가격을 평균 이상으로 유지하면서 생산량을 조절해 마진을 극대화하는 ‘마진 최적화 전략’, (3) 시장 상황에 따라 가격·생산량을 동적으로 조절하는 ‘혼합 전략’으로 구분되었다. 특히, 경쟁 강도가 낮은(z_c가 작을 때) 환경에서는 가격 경쟁 전략이, 경쟁이 치열한(z_c가 클 때) 환경에서는 마진 최적화 전략이 우세했다.
경제 전체에 미치는 파급 효과를 측정한 결과, RL 기업 비중이 증가할수록 총생산량(GDP)은 일관되게 상승했지만, 전략 선택에 따라 생산량 변동성(거시경제 불안정성)이 달라졌다. 마진 최적화 전략을 주로 채택한 경우, 높은 이익을 달성하면서도 생산량 변동이 커져 경기 진동이 심화되는 경향을 보였다. 반면, 가격 경쟁 전략은 이익이 다소 낮지만 생산량이 보다 안정적인 패턴을 유지했다.
이 논문은 강화학습을 거시경제 ABM에 통합하는 방법론적 프레임워크(R‑MABM)를 제시하고, 오픈소스 구현을 통해 재현 가능성을 확보했다. 또한, ‘전략적 분리’ 현상이 통신 없이도 발생한다는 점은 기존 경제학 이론에서 가정하던 ‘협조적 행동’이나 ‘정보 공유’ 없이도 시장 권력 집중이 일어날 수 있음을 시사한다. 마지막으로, 정책 입안자는 합리적 에이전트 비중과 그들이 채택하는 전략 유형을 고려해, 성장 촉진과 안정성 확보 사이의 트레이드오프를 설계해야 함을 강조한다.
댓글 및 학술 토론
Loading comments...
의견 남기기