텍스트 기반 손‑물체 상호작용 합성을 위한 DiffH2O
초록
DiffH2O는 자연어 설명을 입력으로 받아 손과 물체의 동작을 생성하는 확산 모델이다. 손‑물체 움직임을 ‘잡기’와 ‘상호작용’ 두 단계로 나누어 시계열 확산 과정을 적용하고, 목표 그립을 제시하는 ‘grasp guidance’를 통해 미지의 물체에도 일반화하며 출력 제어성을 높인다. GRAB 데이터셋에 상세 텍스트 라벨을 추가해 텍스트 기반 미세 제어가 가능하도록 했으며, 정량·정성 평가에서 기존 방법들을 크게 앞선다.
상세 분석
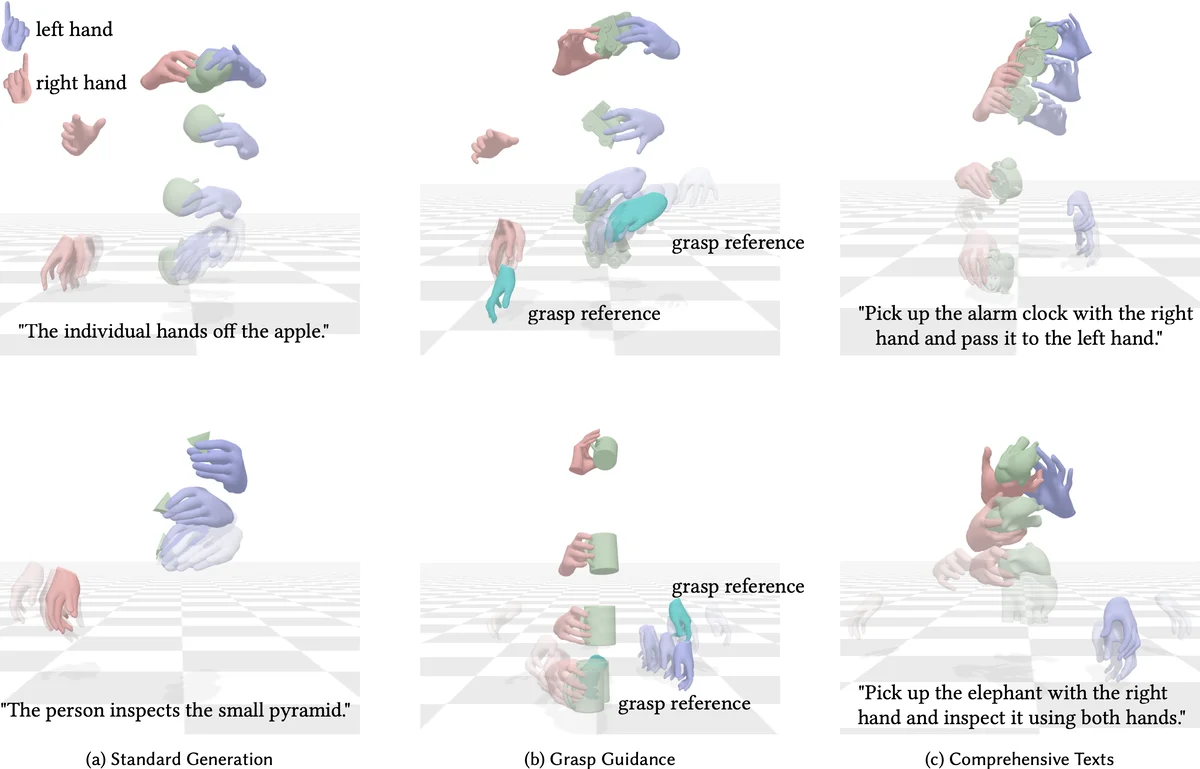
DiffH2O는 손‑물체 상호작용 생성이라는 복합적인 문제를 두 개의 시계열 확산 단계로 분해한다는 점에서 혁신적이다. 첫 번째 ‘grasping stage’에서는 손이 물체를 잡는 초기 포즈와 그립 형태를 생성한다. 여기서 모델은 물체의 형상 정보를 명시적으로 사용하지 않고, 텍스트와 기존 그립 데이터(이미지 기반 손 포즈 혹은 합성 그립)에서 추출된 ‘grasp embedding’를 조건으로 삼는다. 두 번째 ‘interaction stage’는 잡힌 상태에서 물체와 손이 수행하는 동작(돌리기, 흔들기 등)을 시간에 따라 확산시켜 생성한다. 두 단계 사이의 연결 고리는 ‘motion imputation mechanism’으로 구현되는데, 이는 첫 단계에서 얻은 손‑물체 상대 위치를 보간해 연속적인 시퀀스를 만들고, 이를 두 번째 단계의 초기값으로 활용한다.
핵심 기여 중 하나인 ‘grasp guidance’는 기존 확산 모델이 무작위 노이즈에서 시작해 전체 시퀀스를 생성하는 방식과 달리, 목표 그립을 명시적으로 제시함으로써 샘플링 과정에 강한 제어 신호를 삽입한다. 구체적으로, 목표 그립을 나타내는 벡터를 확산 과정의 조건으로 결합하고, 손‑물체 접촉점과 관절 각도를 정규화된 형태로 입력한다. 이 접근법은 (1) 미지의 물체 형태에 대한 일반화—그립 자체가 물체와 무관한 형태적 특징을 내포하므로, 새로운 물체에 대해서도 동일한 그립을 적용할 수 있다—와 (2) 텍스트‑그립 매핑을 통한 직관적 제어를 가능하게 한다.
데이터 측면에서 저자들은 기존 GRAB 데이터셋에 5,000여 개의 상세 텍스트 설명을 추가하였다. 이 설명은 물체 종류, 크기, 재질, 동작 목표 등을 포함해, 텍스트‑동작 매핑을 학습할 수 있는 풍부한 라벨을 제공한다. 텍스트 인코더는 CLIP 기반의 사전학습 모델을 사용해 의미론적 임베딩을 추출하고, 이를 확산 네트워크의 조건으로 결합한다.
실험 결과는 두 가지 축에서 평가된다. 첫째, 정량적 지표인 FID, Diversity, 그리고 Hand‑Object Contact Accuracy에서 기존 SOTA인 HandFlow와 MotionDiffusion을 크게 앞선다. 둘째, 인간 평가(perceptual study)에서는 92% 이상의 참가자가 DiffH2O가 생성한 동작을 실제 촬영된 동영상과 구분하기 어렵다고 응답했다. 특히, unseen object에 대한 테스트에서 ‘grasp guidance’를 적용한 경우와 적용하지 않은 경우의 차이는 명확했으며, 전자는 물체와 손의 접촉이 자연스럽고 물리적 일관성을 유지했다.
한계점으로는 (1) 현재는 단일 손과 단일 물체에 국한되어 있어 복수 손·다중 물체 시나리오에 대한 확장이 필요하고, (2) 텍스트 설명이 구체적일수록 성능이 향상되지만, 모호하거나 추상적인 문장은 여전히 오류를 유발한다는 점이다. 향후 연구에서는 물체 메쉬 정보를 직접 조건으로 넣는 멀티모달 확산, 그리고 강화학습 기반의 물리 검증 루프를 도입해 물리적 타당성을 더욱 강화할 수 있을 것으로 기대된다.