학습 라벨 선택이 정량적 MRI 딥러닝 추정 정확도에 미치는 영향
본 논문은 정량적 MRI 파라미터 추정에 사용되는 딥러닝 모델의 학습 라벨을 재설계함으로써, 기존의 지도학습(ground‑truth 라벨)에서 발생하던 높은 편향을 감소시키고, 자기‑지도학습이 보여준 낮은 편향을 지도학습에서도 구현할 수 있음을 입증한다. 라벨을 직접적인 ground‑truth가 아닌 최대우도(MLE) 추정값으로 대체하고, 필요시 두 손실을 가중합한 하이브리드 방식을 제안한다. IVIM 모델과 Rician 잡음 환경에서 수행한 …
저자: Sean C. Epstein, Timothy J. P. Bray, Margaret Hall-Craggs
본 논문은 정량적 MRI(qMRI) 파라미터 추정에 딥러닝을 적용할 때, 학습 라벨 선택이 모델 성능에 미치는 영향을 체계적으로 분석하고, 새로운 라벨 설계 방식을 제안한다. qMRI는 신호 모델 M(z|y) 에 따라 여러 b‑값 혹은 다른 실험 파라미터를 가진 이미지 시퀀스를 획득하고, 각 voxel마다 모델 파라미터 y 를 추정한다. 전통적인 비선형 최소제곱(NLLS)이나 최대우도(MLE) 방식은 voxel‑wise 최적화를 필요로 하여 계산량이 크게 늘어나지만, 딥러닝은 전체 voxel 데이터를 하나의 전역 함수 F 로 학습함으로써 추정 비용을 사전에 amortize한다.
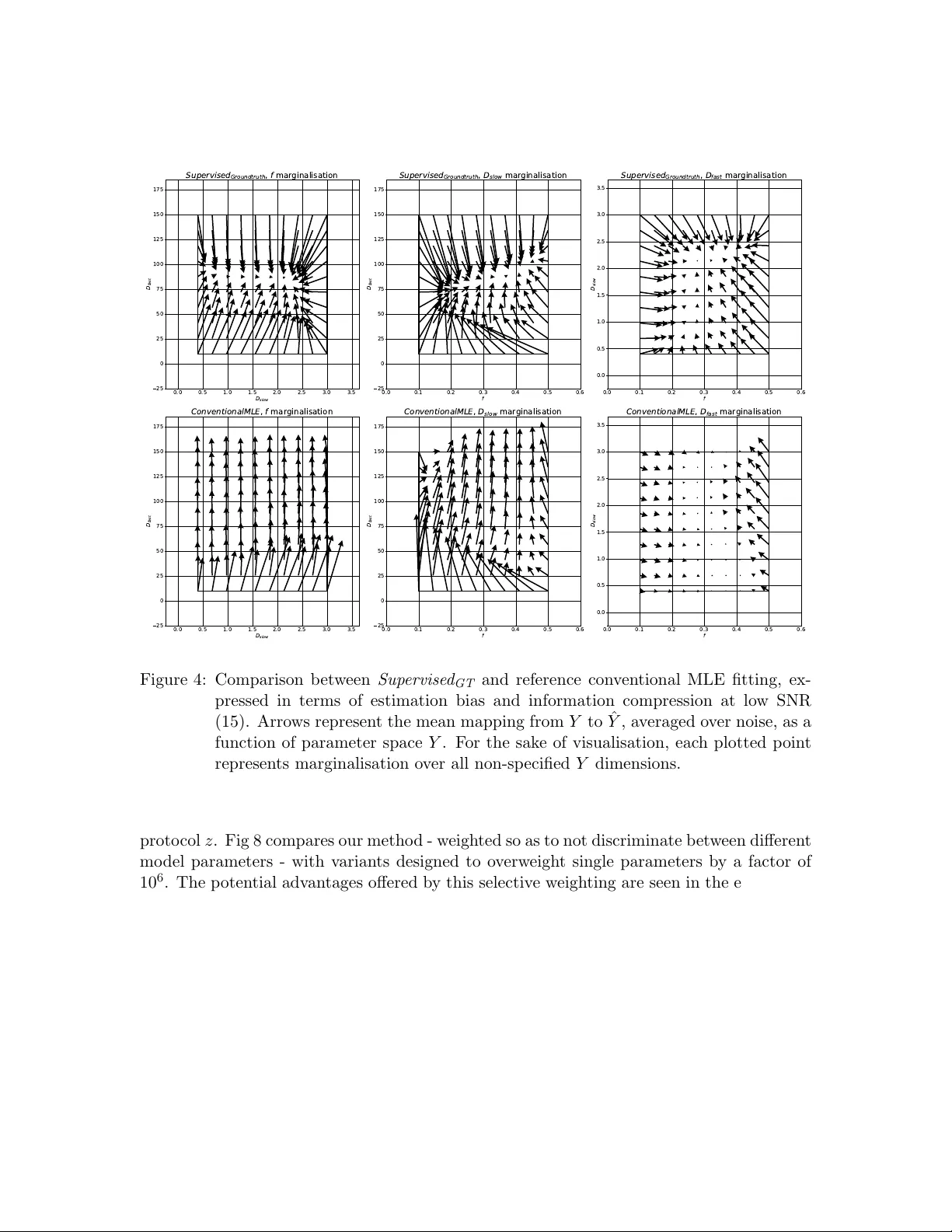
딥러닝 기반 qMRI 추정 방법은 크게 두 가지 패러다임으로 나뉜다. 첫 번째는 ‘지도학습(ground‑truth GT)’으로, 시뮬레이션이나 고정밀 MLE 결과를 라벨로 사용해 파라미터 공간 Y 에서 손실 ‖W·(ŷ−y_gt)‖² 을 최소화한다. 이 방식은 학습 시 가장 풍부한 정보를 제공하지만, 라벨이 실제 측정 신호와 완전히 일치하지 않는 ‘이상적인’ 값이기 때문에 추정된 파라미터에 체계적 편향(bias)이 발생한다. 두 번째는 ‘자기‑지도학습(self‑supervised)’으로, 입력 신호 x 와 네트워크 출력 파라미터 ŷ 를 다시 신호 모델에 대입해 재구성 신호 M(z|ŷ) 와 원본 x 사이의 차이를 신호 공간 X 에서 최소화한다. 이 접근은 전통적인 MLE와 동일한 목표 함수를 사용하므로 편향이 낮고 분산이 상대적으로 크다. 그러나 신호‑공간 손실은 Rician 잡음 등 비가우시안 노이즈 모델을 정확히 반영하기 어렵고, 파라미터별 가중치 조정이 제한적이다.
저자들은 ‘지도학습’의 풍부한 정보와 ‘자기‑지도학습’의 낮은 편향을 동시에 달성하기 위해 라벨을 ‘비‑ground‑truth’인 MLE 추정값으로 교체한다. 구체적으로, 훈련 데이터에 Rician 잡음이 가해진 신호 x 와 동일 데이터에 대해 독립적인 MLE(경계 제약 비선형 최적화)로 얻은 파라미터 y_MLE 를 쌍으로 만든다. 손실은 파라미터 공간에서 ‖W·(ŷ−y_MLE)‖² 형태이며, 여기서 W 는 파라미터 스케일에 따라 조정 가능한 대각 행렬이다. 이 ‘Supervised MLE’ 방식은 (1) Rician 로그‑우도 기반 라벨을 사용해 비가우시안 잡음에 대한 정확한 통계 모델링을 가능하게 하고, (2) 파라미터별 가중치를 자유롭게 설정해 특정 파라미터에 대한 성능을 강화할 수 있다.
또한 두 손실을 가중합한 ‘Hybrid loss = α·Supervised MLE + (1−α)·Supervised GT’ 형태를 제안한다. α ∈
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기