일관성 기반 무지도 자기학습을 통한 ASR 개인화
본 논문은 라벨이 없는 사용자 음성 데이터를 활용해 사전 학습된 ASR 모델을 개인화하는 새로운 방법을 제안한다. 데이터 필터링 후, SpecAugment와 드롭아웃을 이용한 다양한 변형을 적용한 pseudo‑label을 생성하고, 일관성 제약(Consistency Constraint)을 손실 함수로 사용해 첫 번째 패스 모델을 자체적으로 미세조정한다. 실험 결과, 기존 무지도 적응 기법 대비 17.3%·8.1%의 WER 감소를 달성하였다.
저자: Jisi Zhang, V, ana Rajan
**1. 서론**
대규모 데이터로 사전 학습된 엔드‑투‑엔드 ASR 모델은 실제 디바이스에 탑재될 때 사용자마다 다른 억양, 발음, 배경 잡음 등으로 인해 성능 저하를 겪는다. 이를 해결하기 위한 개인화(personalisation) 접근법은 주로 라벨이 있는 사용자 데이터를 이용해 모델을 미세조정하지만, 라벨링 비용과 프라이버시 문제로 실용성이 떨어진다. 따라서 라벨이 전혀 없는 상황에서도 효과적으로 모델을 적응시키는 무지도(self‑training) 방법이 필요하다.
**2. 관련 연구**
기존 무지도 개인화 연구는 (1) 보조 스피커 특징을 결합, (2) 데이터 필터링 후 pseudo‑label을 활용, (3) 엔트로피 최소화 기반 적응 등으로 나뉜다. 특히, 데이터 필터링 단계에서는 NCM, DUST, Confidence Thresholding 등 다양한 신뢰도 추정 기법이 사용된다. 하지만 이러한 방법들은 pseudo‑label의 오류가 누적될 경우 모델이 drift하는 문제를 안고 있다.
**3. 배경**
본 연구는 두 단계 Conformer‑Transducer 모델을 사용한다. 첫 번째 패스는 Conformer 기반 트랜스듀서이며, 두 번째 패스는 LAS(Latent Attention Sequence) 디코더로 첫 번째 패스의 출력에 재점수를 매긴다. 모델은 RNN‑T 손실과 CE 손실을 동시에 학습한다. 데이터 필터링에는 NCM 이진 분류기를 활용해 WER=0인 샘플만을 선택한다. NCM은 디코더 로그와 빔 스코어를 입력으로 받아, 높은 신뢰도를 가진 샘플을 판별한다.
**4. 제안 방법**
제안 파이프라인은 크게 (1) 데이터 필터링, (2) N 라운드의 pseudo‑label 생성 및 모델 학습, (3) 일관성 제약 적용의 세 단계로 구성된다.
- **데이터 필터링**: 전체 무라벨 데이터 X에 D_A_T_A_F_I_L_T_E_R을 적용해 ˆX를 얻는다. 여기서는 NCM을 기본으로 사용하지만, DUST·CT와도 호환 가능함을 보인다.
- **Pseudo‑label 생성**: 현재 모델 f(θ_i)를 사용해 ˆX의 각 샘플에 SpecAugment를 적용한 뒤, 두 번째 패스 LAS 디코더로 beam search를 수행해 hard label ˆy를 만든다.
- **일관성 제약 기반 학습**: 첫 번째 패스 모델에 다시 SpecAugment와 드롭아웃을 적용해 변형된 입력 ˜x를 만든다. 변형된 입력에 대해 RNN‑T 손실 L = −ln Pr(ˆy|˜x) 를 최소화한다. 여기서 일관성 제약은 동일 입력에 대해 변형 전후의 출력이 일관되도록 강제한다.
알고리즘 1은 위 과정을 N 라운드, 각 라운드마다 M epoch 동안 반복한다. pseudo‑label은 매 라운드마다 최신 모델로 갱신되어 오류 전파를 최소화한다.
**5. 실험 설정**
- **데이터**: 사전 학습 모델은 20K시간 영어 음성(공개·내부 데이터 혼합)으로 학습되었으며, 검증 셋(6시간)에서 15.69% WER을 기록한다. 개인화 실험은 12명의 화자에 대해 Apps(앱 실행), Contacts(연락처 명령), Dictations(일상 대화) 세 종류의 음성을 사용한다. 각 화자당 총 31.77분(8.37+16.93+6.47) 데이터가 있다.
- **모델 구성**: 첫 번째 패스는 16개의 Conformer 블록, 두 개 LSTM(640) 예측 네트워크, joint dense layer; 두 번째 패스는 LSTM encoder(680)와 두 개 LSTM decoder(680). Beam size는 1‑pass 4, 2‑pass 1이며 LM은 사용하지 않는다.
- **필터링 설정**: NCM은 2개의 dense‑64, tanh, self‑attention, 또 다른 dense‑64 구조이며, 학습률 1e‑3, 배치 32, K=4. DUST는 dropout 0.2, 5 hypothesis, edit distance threshold 0.1. CT는 NCM 기반 임계값을 사용한다.
- **학습 하이퍼파라미터**: 배치 16, Adam, 학습률 5e‑6(모델 fine‑tuning), 1e‑3(LHUC), SpecAugment(주파수 마스크 13, 시간 마스크 12×2), dropout 0.1, N=3 라운드, M=5 epoch 등.
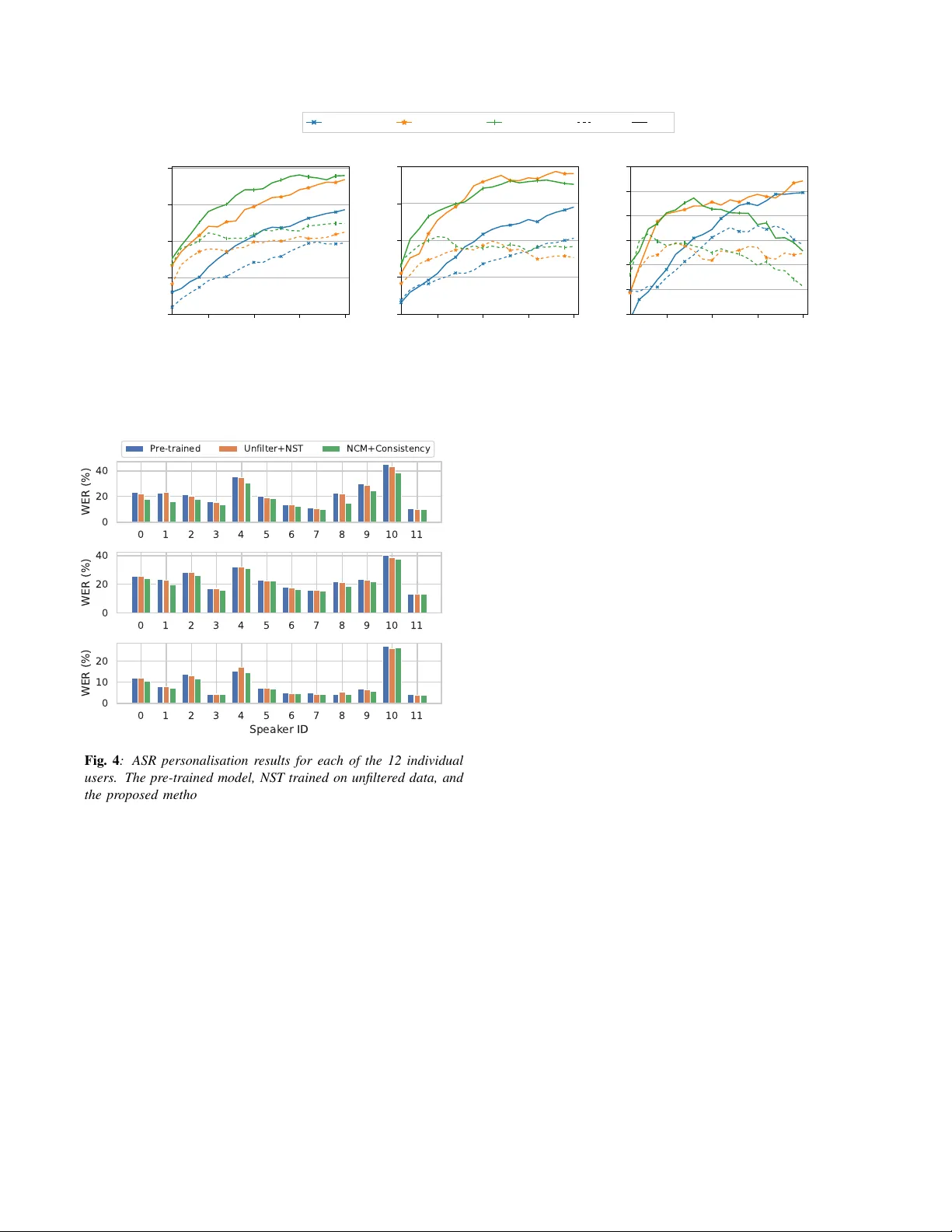
**6. 결과 및 분석**
- **전체 성능**: 제안 방법은 필터링된 Apps·Contacts 데이터에서 평균 17.3% WERR, 보지 않은 Dictations 데이터에서는 8.1% WERR을 달성했다. 이는 NST, LHUC, EM 등 기존 무지도 적응 기법보다 모두 높은 개선률을 보인다.
- **필터링 독립성**: NCM, DUST, CT 각각을 사용했을 때 성능 차이가 미미했으며, 일관성 제약이 필터링 방법에 크게 의존하지 않음을 확인했다.
- **개별 화자 분석**: 화자별 WER 감소 폭은 5%~25% 사이였으며, pseudo‑label WER이 10%~45% 범위에서도 일관성 제약이 안정적인 학습을 유지했다.
- **Ablation**: (1) SpecAugment 없이 CC만 적용하면 성능이 3~4% 감소, (2) 드롭아웃 없이 CC만 적용해도 비슷한 감소, (3) CC 없이 기존 pseudo‑label 학습만 하면 drift 현상이 심해 WER이 오히려 상승한다는 결과가 나왔다.
**7. 결론 및 향후 과제**
본 연구는 완전 무지도 환경에서 일관성 제약을 활용해 ASR 모델을 효과적으로 개인화하는 방법을 제시하였다. 필터링 단계와 무관하게 적용 가능하며, 다양한 억양·노이즈 환경에서도 견고한 성능 향상을 보인다. 향후 연구는 두 번째 패스 LAS 디코더에도 CC를 확장하고, 멀티‑모달(텍스트·음성) 신호를 이용한 고도화된 필터링 및 적응 전략을 탐색할 계획이다.
원본 논문
고화질 논문을 불러오는 중입니다...
댓글 및 학술 토론
Loading comments...
의견 남기기